Building Labeler NearBy
Table of Contents

My First Hackathon
During the later parts of summer of 2022, I really wanted to work on a exciting project. I had just finished my undergraduate and was working full time as a software engineer. I really wanted to commit to a side project and at the time, I had enough free time to do so. I really did not know what to work on, until I discovered a website called Devpost on August 2022. Devpost is a website that hosts software competitions called hackathons. Well browsing Devpost, I discovered a hackathon called NEAR MetaBUILD III which was a hackathon hosted by the NEAR Protocol organization.
What is NEAR?
The NEAR Protocol is a blockchain that supports smart contracts and the NEAR cryptocurrency. It is mainly known for having very low transitions fees, support smart contracts, having it’s own official test network, and a great developer environment due to the fact that you can write smart contracts in Rust and/or Java Script. You can get a better overview of the NEAR Protocol though CoinGecko’s amazing video:
During this time, Coinbase officially started supporting the NEAR Protocol as a tradable coin on their platform. Which was a big deal because Coinbase is known for being every selective when it comes to which coins they support on their platform. This helped make NEAR a more trustable platform. You can still trade NEAR on Coinbase to this day.
Why Commit?
After spending some time thinking, I decided to commit my time towards competing in the NEAR MetaBUILD III hackathon. My reasoning was this:
- Crypto is not going away and is a technology that will stay. So it made sense to invest some time into learning the technology.
- The hackathon had great rewards, anywhere between $20,000 to $100,000 in NEAR if you one of winners.
- The hackathon had a specific deadline, meaning the project could not be dragged on for months like many side projects generally are.
- The project would be a great learning experience and a great introduction to hackathons
- Worst case, the hackathon would allow me to make a great project to show on my resume.
With all of this in mind, I called my close friend from college on August 26, 2022 and we started planning for this hackathon. The hackathon was scheduled to start on September 23, 2023 and conclude on November 21, 2022. Though the deadline did get extended towards November 24, 2023 towards the end of the hackathon. Sense we were 1 month early, we decided to spend this time learning and brain storming what we would work on for this 2 month hackathon. During that 1st month, we got a general overview of crypto and blockchains. We reviewed and practiced on NEAR’s testnet, reviewed the NEAR SDK, and deployed a couple smart contracts.
The Idea
After getting a great introduction to all things blockchain and NEAR, we started brain storming ideas. I wanted this project to be something that was not just a “hackathon project”, but something that could become a product that others can use and act as an example of how crypto could be useful for things outside of just trading.
With this in mind, we initially decided to create something similar to the Unreal Engine Blueprint, but for the easy creation and deployment of smart contracts on the NEAR blockchain without the need for coding. However, one week before the hackathon commenced, we abandoned the idea because it simply did not make sense. Why would anyone bother using our tool to create NEAR smart contracts if there was no practical use case for them yet? It would be like developing a tool that many people did not need.
With only one week left before the hackathon started, we started brain storming again and settled on this idea:
A decentralized platform where AI researchers can outsource
data labeling to labelers around the world
We named the project “Labeler NearBy.” Our decision to choose this idea was based on the following reasons:
- AI development requires human labeling of data for training.
- Finding and managing skilled individuals for labeling specific datasets is challenging.
- The idea has already been successfully implemented by a company called Scale AI, as evidenced by how they found product-market fit.
- Centralized services like Scale AI pose concerns as organizations have to send their data to the labeling company, which then outsources human labelers globally. After the labeling process, the company returns the labeled data to the organization. This relinquishes control over valuable training data, which could be used by the labeling company to train their own models. Decentralizing this service seemed like a logical solution.
- We found very few projects in the decentralized app (dApp) space working on this idea, providing an opportunity for us to innovate and pioneer in this area.
To help reduce complexity, we decided that Labeler NearBy will only support image data for the time being.
Submission
With the idea picked and the hackathon officially underway, my friend and I began building Labeler NearBy. We worked on our project for 2 months until we submitted the final draft of our project to Devpost on November 24, 2022. We submitted our project on Devpost and also created a copy of our submission on Github. This blog does not cover every technical aspect and development process of Labeler NearBy. Knowing this, to learn more about how Labeler NearBy works or to view our final submission, please visit one of the following links:
Labeler NearBy consists of two codebases: ln-researcher and ln-labeler. These codebases are completely open source under the MIT license and can be viewed through the following links:
Here is a general overview of how Labeler NearBy (LN) would work:
A researcher requires labeled images for training their AI model. To accomplish this, the researcher utilizes LN to host their data and provide a means for labelers to label their data. This is achieved though ln-researcher, a self hosted web service that consists of an API, the researcher’s smart contracts, and a local Postgres database. For the labeler, a web frontend is (would have been) provided, enabling them to access and label the researcher’s images. Well in the process of being labeled, one image is labeled three times by different labelers. Only the labeler with the best labels, determined through a voting system, is rewarded with NEAR coins. The web app responsible for this process is called ln-labeler. The researcher funds each labeling operation, and NEAR coins can be easily converted to dollars through Coinbase. All transaction logistics are handled by smart contracts hosted on the NEAR Protocol blockchain.
You can view our demo video of Labeler NearBy for the hackathon here:
Greatest Achievement
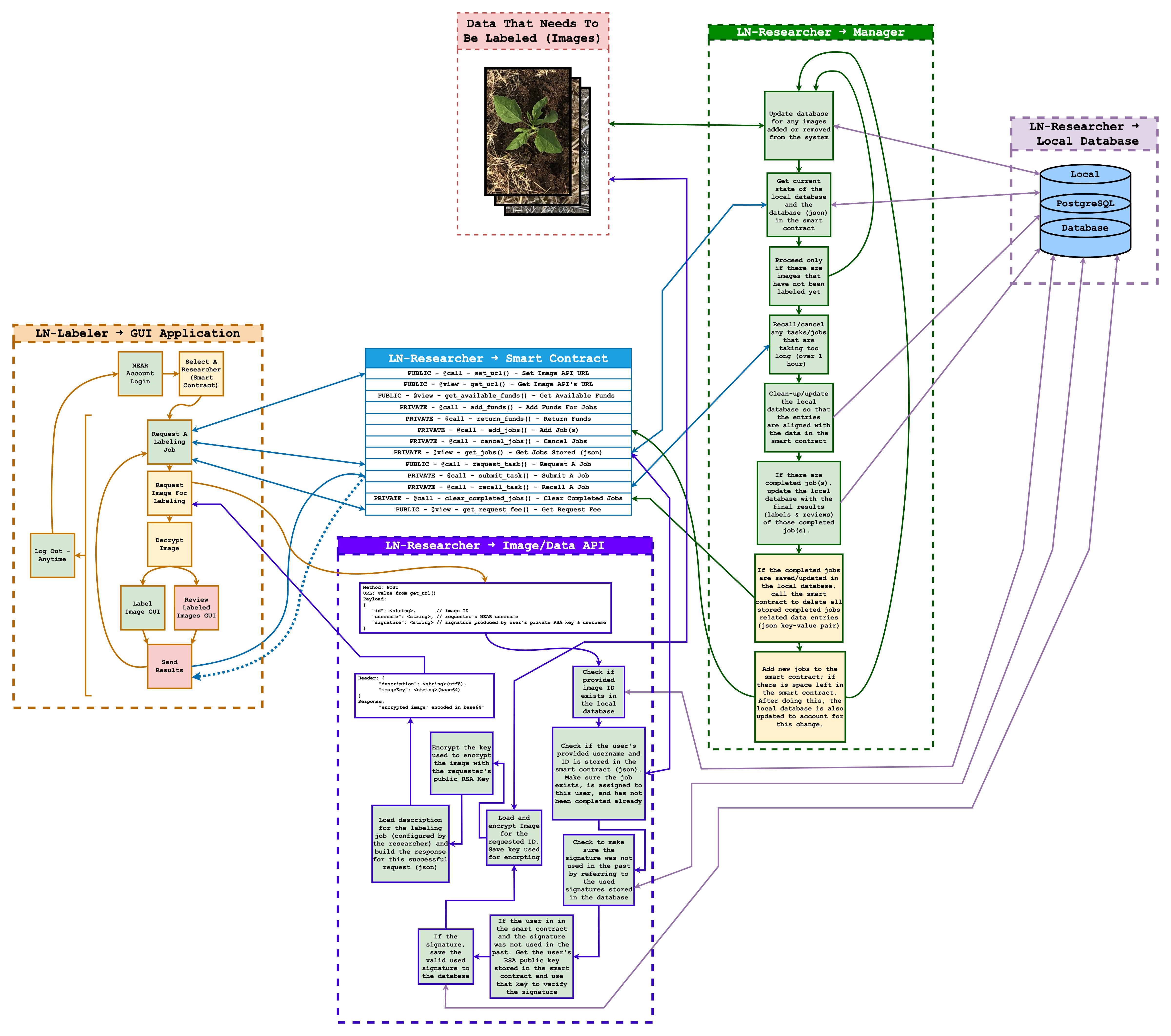
The feature I am most proud of implementing is a function called getImage(). This function serves as an API endpoint in ln-researcher and plays a crucial role in the data pipeline between researchers and labelers in Labeler NearBy (LN).
This API endpoint enables researchers to securely and reliably distribute their images for labeling. The labeling assignments are managed via a NEAR smart contracts on the NEAR Protocol blockchain well the image data is hosted by the researcher though ln-researcher.
The endpoint performs a series of security checks to ensure that only the assigned labeler can access the image. This includes verifying the signature of the request and checking the associated smart contract to confirm the existence of the task and its assignment to the requesting labeler.
Once the request is validated in the researcher’s self-hosted ln-researcher API, the function retrieves the image from the local Postgres database, encrypts the image, and delivers it to the authorized labeler who can then decrypt the image for labeling. Simultaneously, the function updates the image’s status in the database, indicating the progress of the image getting labeled. Though out this process, RSA keys from both the researcher and labeler is used to authenticate. Well AES encryption is used to encrypt the image.
This endpoint plays a critical role in managing the secure and controlled distribution of images from researchers to labelers. It ensures secure data transfer and effectively tracks and manages the image labeling process. Additionally, this process has the potential to eliminate the need for using HTTPS, at least for this endpoint.
This specific endpoint/function was tested and proven to be functional. Below is a diagram illustrating the overall functionality of Labeler NearBy, including a clear depiction of how the aforementioned endpoint/function works:
Outcome
Regrettably, the sad reality is that we were unable to fully complete this project by the hackathon’s deadline. Most of the project was completed, such as the ln-researcher, but the frontend (ln-labeler) was not completed and we were not able to deploy a live demo. Though the backend (ln-researcher) was basically completed, with no properly working frontend and no live demo, no one was able to try out the idea of Labeler NearBy. Not only that, but the judges were not able to try out the project and instead had to read the submission, go though the code, and/or try to run it themselves. Which made our chances of winning go down to basically zero percent. This was confirmed on December 15, 2022 when the hackathon winners were announced, and we were not among them.
Losing
I won’t hide the fact that the final outcome from this hackathon was disheartening. Months were invested into this project and I had a major vision for this project as I thought it would provide a very useful tool to researchers.
I have a clear standard for the projects I undertake: either they succeed or they fail; there is no middle ground. So this project was a failure because it was not fully completed by the deadline and remained inaccessible to potential users.
But it’s important to remember that failure is a natural part of life. Our successes are built upon the lessons we learn from our failures. While the outcome of this hackathon was disheartening, it still provided valuable insights when it comes to developing and building a project/product.
Lessons Learned
The main lessons I took from this experience was the following:
- The project we picked required a lot features built upfront before we could iterate on it. What do I mean by this? Well, this project required nearly all components of the idea to be built out before we could even test the idea. It would have made more sense to pick a project that had less essential components to function. In doing so, we could have built the essential components faster then iterate on the project sooner. In doing so, we could have hit the deadline more easily and made a project that might have been simpler but more complete. YC, a tech startup accelerator, emphasizes that you should launch quickly, talk with users, and iterate. We should have done that with our project for this hackathon.
- We underestimated how long this project was going to take to build. This was our first hackathon and our fist time making a decentralized application (dapp). Not only that, but I was working full time as software engineer and my friend was completing his Masters. Yet, we thought 2 months would be enough. It would have made more sense to reduce the scope of the project and/or find one more team member who could have reduced our work load.
- Winston Churchill famously stated: “Perfection is the enemy of progress”. I was treating this project like a business-to-customer (B2C) product, when it reality this was just a hackathon project and at most a minimum viable product (MVP). So early on, I wasted too much time on small details when I should have been focusing my time on making core features work sufficiently.
In addition to these valuable lessons, I have gained new skills that have proven invaluable in both my personal side projects and professional endeavors. These skills include:
- Developing APIs though Node.js, JavaScript, and Express.js
- Setting up and using PostgreSQL for data management
- Incorporating PostgresSQL into API development by using packages like PG.
- Utilize RSA (asymmetric encryption) and AES (symmetric encryption) for enhanced data security.
Conclusion
Overall, I am glad that we participated in this hackathon, despite being disappointed with the final outcome. I am grateful for the valuable lessons and skills I acquired while working on Labeler NearBy, as they have made me a better developer and have significantly contributed to the development of my next project: Notify-Cyber.
Other Notes
- I might come back to Labeler NearBy, but for the time being, this project is on “long hiatus”
- Currently, Labeler NearBy should ONLY run in NEAR’s testnet. It needs further development, testing, and auditing.