ABM Marketing with InsightRed
![]()
About
InsightRed is an LLM-powered Account-Based Marketing (ABM) tool that extracts the latest Reddit comments from Subreddits, sorted by “Hot”, and pinpoints users who exhibit potential interest in your project or product. It helps you identify and target high-value users on Reddit to get your initial users for your product/project. This project was built for the ANARCHY October 2023 Hackathon.
Announcement(s)
October 19, 2023
As a follow up to this project, I’m excited to announce that we won 1st place at Anarchy’s October 2023 Hackathon!
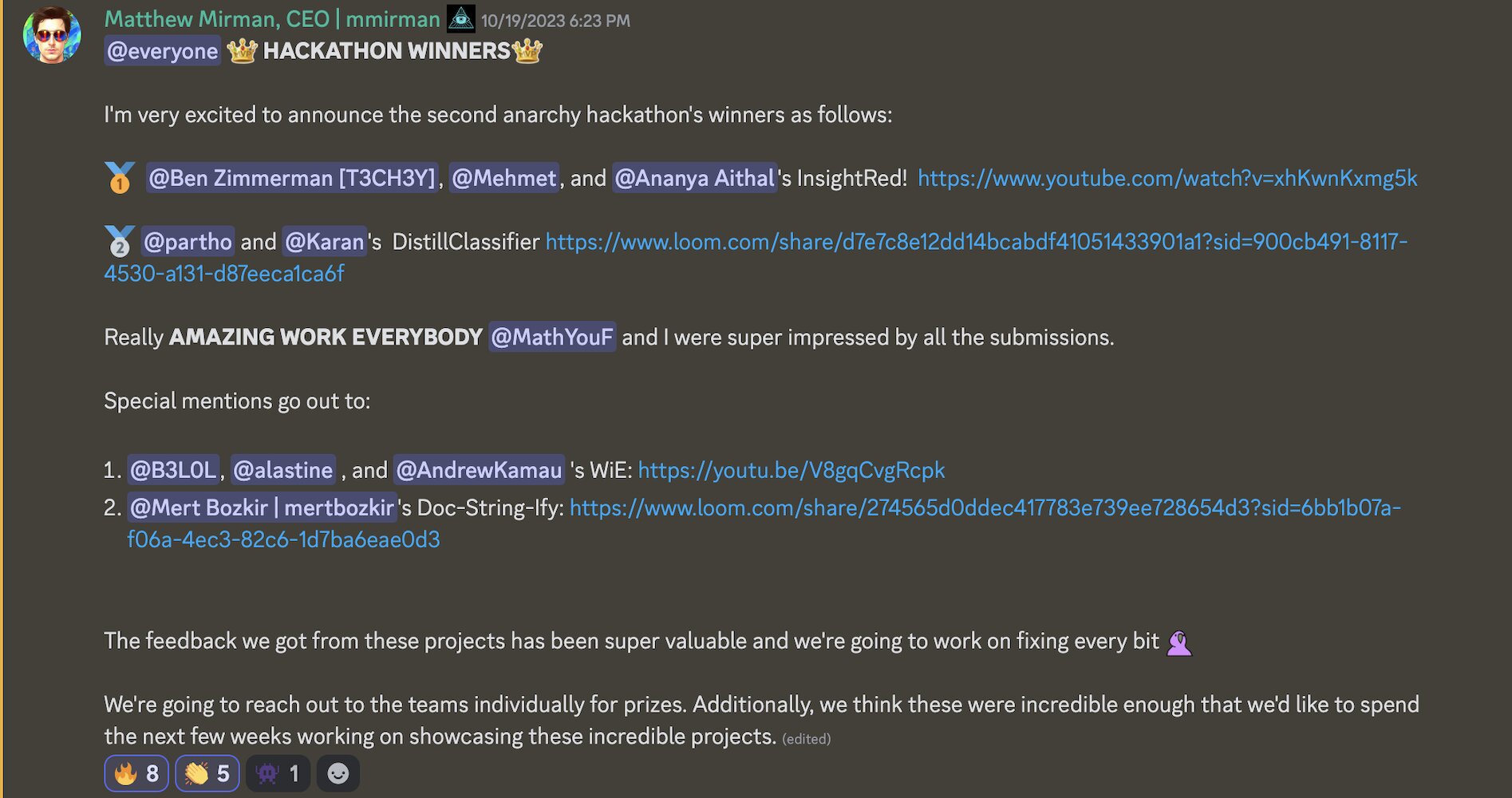
Click here to view the message in TEXT mode (modified due to Discord's formatting)
@everyone **👑 HACKATHON 👑**
I'm very excited to announce the second anarchy hackathon's winners as follows:
🥇 "@Ben Zimmerman [T3CH3Y]", @Mehmet, and "@Ananya Aithal"'s InsightRed! https://www.youtube.com/watch?v=xhKwnKxmg5k
🥈 @partho and @Karan's DistillClassifier https://www.loom.com/share/d7e7c8e12dd14bcabdf41051433901a1?sid=900cb491-8117-4530-a131-d87eeca1ca6f
Really **AMAZING WORK EVERYBODY** @MathYouF and I were super impressed by all the submissions.
Special mentions go out to:
1. @B3LOL, @alastine , and @AndrewKamau 's WiE: https://youtu.be/V8gqCvgRcpk
2. "@Mert Bozkir | mertbozkir"'s Doc-String-Ify: https://www.loom.com/share/274565d0ddec417783e739ee728654d3?sid=6bb1b07a-f06a-4ec3-82c6-1d7ba6eae0d3
The feedback we got from these projects has been super valuable and we're going to work on fixing every bit 🦜
We're going to reach out to the teams individually for prizes. Additionally, we think these were incredible enough that we'd like to spend the next few weeks working on showcasing these incredible projects.
Demo
InsightRed’s Components
🧩 Collector
The Collector collects the latest Reddit posts and that post’s comments, for a given Subreddits, by using Reddit’s API. After collecting, the collector saves the collected data to a local SQLite database. This is made easy by using the python package praw to assist with using the Reddit API and SQLAlchemy for performing CRUD operations in the local SQLite database.
🧩 Vectorizer
The Vectorizer checks the local SQLite database to see which comments have not been saved to the vector database. After getting a list of comments, it creates an embedding of the post+comment using OpenAI’s “text-embedding-ada-002” model. This embedding is used as an Index in the vector database and some metadata, in the form of a JSON, is also created. The Index and metadata is then uploaded to the vector database, which in this case is Pinecone (cloud-based). After being uploaded, the local SQLite database is updated to avoid re-uploading the same data to Pinecone. This is all done by using Pinecone’s python client (pinecone-client) for making CRUD options to the vector database and LangChain for handing the embedding process.
🧩 Interface
The interface is what is used by the user to interact with the tool. In this case, the interface is a CLI. The interface has an implementation of Retrieval-Augmented-Generation (RAG). Where the user provides a description of their product, a list of Subreddits to check, as well as some filters. Given this context, the Collector is called then the Vectorizer is called. After those two services are done processing, the inputted product description is used to make a similarly search in the vector database. The top results and the product description are then fed into a prompt template which creates the final prompt. The final prompt is then sent to OpenAI’s GPT-4 model and the final results are then presented to the user. These results will be a listing of all the Reddit comments that highly suggest the Reddit user(s) would be interested in the provided product, based on it’s description. This component works by using the Collector and Vectorizer comments, as well as, by using Anarchy’s LLM-VM to handling querying OpenAI’s GPT-4 model.
Team Members
Notable Outside Credit
casta (Hacker News)
Providing the inspiration for this project though their HN post. Since their solution was not open-source, I was motivated to create an open-source version (this project).
ChatGPT (GPT-4)
Was very helpful with development by really speeding up the dev cycle. And it generated the project’s logo and YouTube thumbnail using OpenAI’s new DALL-E 3 model.
James Briggs (YouTuber)
Jame’s video really explained how to use Reddit’s API as well as how to implement a basic RAG pipeline using Python.
Sources
- Show HN: Labor Day Fun Project, Find Reddit Comments to Promote Your Business
- Pinecone Indexing Overview Docs
- YouTube: Chatbots with RAG - LangChain Full Walkthrough
- OpenAI API Page
- Pinecone Quickstart Docs
- Reddit: Updated rate limits going into effect over the coming weeks
- Reddit Apps Page
- YouTube: How-to Use The Reddit API in Python
- Medium: Scraping Reddit data using Reddit API
- GitHub Gist: Reddit API
- GitHub: praw
- ChatGPT - Web App