Найвищий виклик Top Coder 8090-х
Оригінальний допис у LinkedIn
GitHub-репозиторій проєкту
У п’ятницю ввечері я побачив публічний допис у Twitter/X від Chamath Palihapitiya, який оголошував відкритий Top Coder Challenge, організований його новою компанією, 8090 Solutions. Приєднатися міг будь-хто. Виклик мав відбутися вже наступного дня, тривати лише 8 годин і передбачав зворотну розробку застарілої системи як чорної скриньки, використовуючи лише історичні дані та кілька інтерв’ю зі співробітниками.
Я вирішив спробувати!
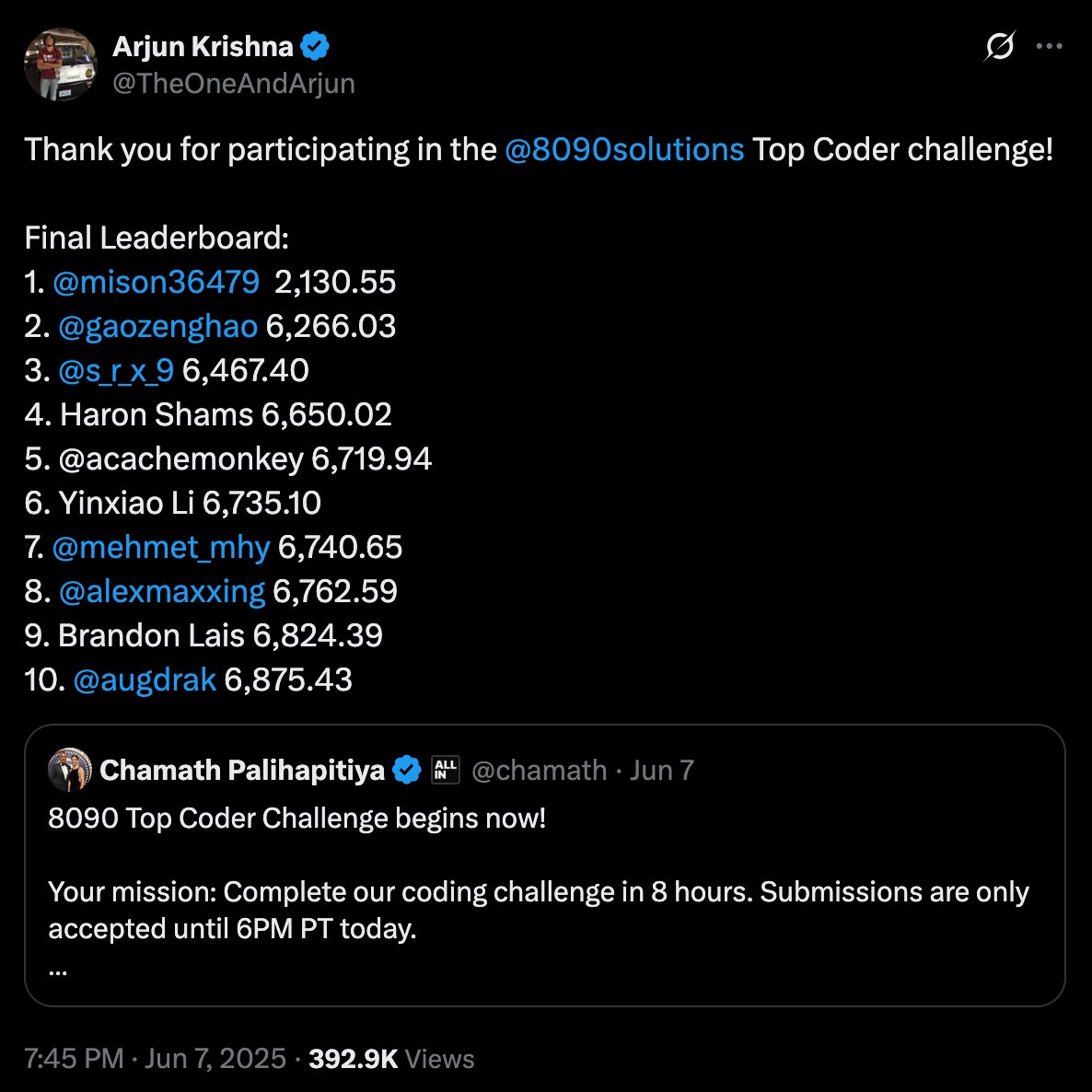
До кінця дня я мав честь посісти 7-ме місце серед 425 інженерів. Ви можете подивитися таблицю лідерів ТУТ і переглянути код для цього виклику ТУТ. Але, не буду брехати, я щиро просто сподівався хоч щось завершити за такий короткий проміжок часу, тож потрапити до таблиці лідерів стало для мене сюрпризом і величезною особистою перемогою.
Виклик був індивідуальним, а метою було відтворити 60-річну систему відшкодування витрат на подорожі як чорну скриньку, яка не мала ані вихідного коду, ані документації. Нам надали кілька матеріалів, зокрема опис продукту, стенограми інтерв’ю зі співробітниками та публічний набір даних, що містив 1 000 історичних прикладів вхідних даних і очікуваних вихідних даних. На основі цього я мав вивести бізнес-логіку того, як обчислювалися суми відшкодування, і реалізувати сучасну версію, яка могла б відтворювати ті самі результати якомога точніше. Подання оцінювалися на окремому прихованому наборі даних, який містив 5 000 тестових випадків замість початкових 1 000. Саме цей більший приватний набір зрештою визначав ваш фінальний бал і місце в рейтингу. Система оцінювання винагороджувала точність, де нижчий бал означав, що ваше рішення точніше відповідало прихованій поведінці оригінальної системи.
Щоб впоратися з невизначеністю та закономірностями в даних, я використав класичні методи машинного навчання разом із базовими евристиками та програмною логікою. Це був уважний мікс аналізу даних, моделювання ознак і наближеного відтворення правил на основі недосконалих підказок.
Ось мій eval-бал для публічного набору з 1 000 даних:
✅ Підсумок оцінювання
------------------------
Загальна кількість випадків : 1000
Точні збіги (<$0.01): 0
Близькі збіги (<$1.00): 17
Середня похибка : $31.15
Бал : 3214.93
Розробити рішення для такого виклику за 8 годин було б майже неможливо без допомоги інструментів на основі ШІ, які спростили швидке дослідження, інтеграцію та тестування ідей.
Це відчувалося як археологія програмного забезпечення, поєднана з живим кодинг-спринтом. Без сумніву, один із найінтенсивніших і найвинагороджувальніших технічних викликів, які я проходив.
Дякую Chamath Palihapitiya та Arjun Krishna за організацію такого креативного й натхненного виклику.
Посилання: