Передбачення людських дій
Деталі
Цей проєкт був проєктом #3 для курсу д-ра Чжана Human Centered Robotics (CSCI473) у Colorado School of Mines протягом весняного семестру 2020 року. Він був розроблений, щоб надати вступ до машинного навчання в робототехніці через використання машин опорних векторів (SVM). Оригінальні матеріали/опис проєкту можна переглянути тут.

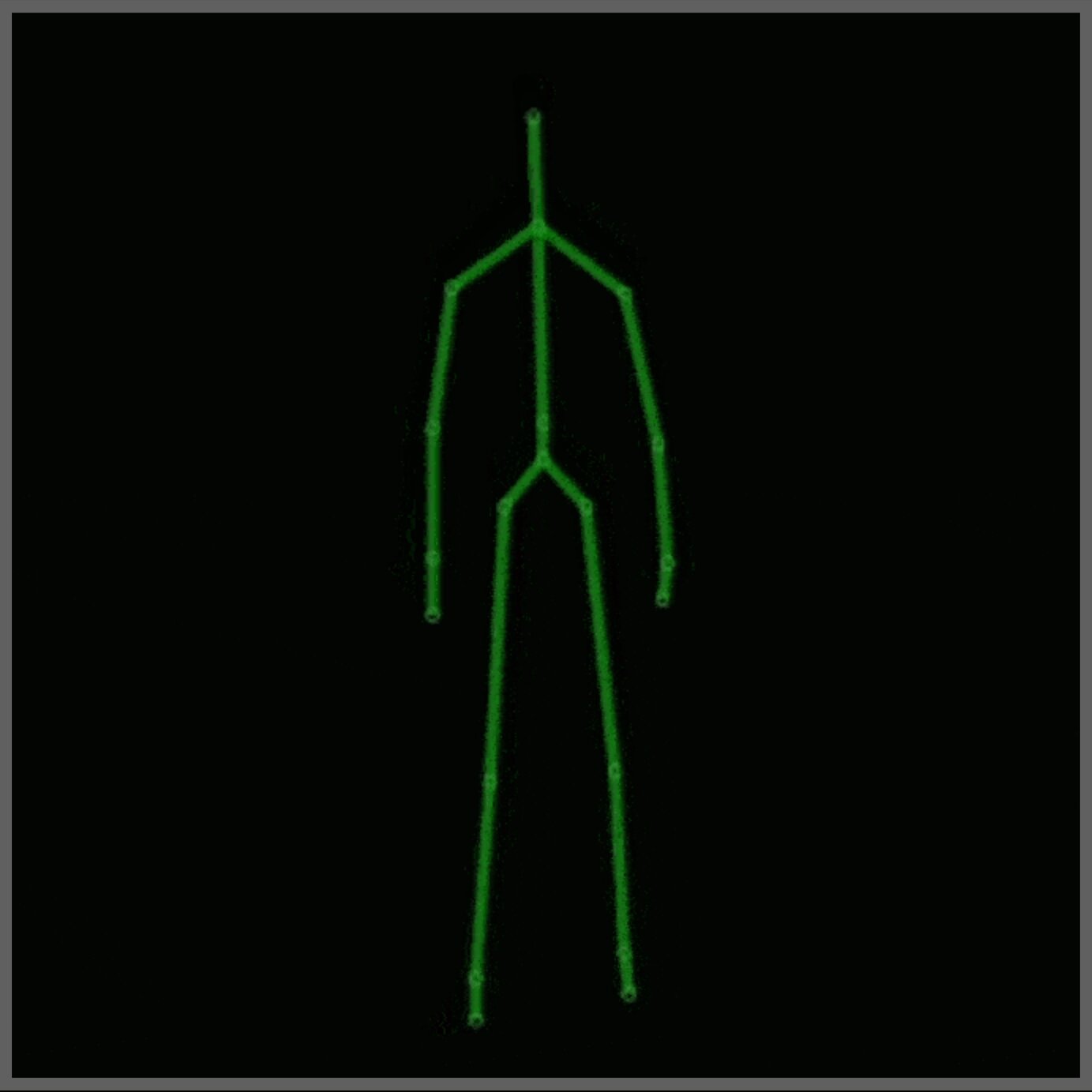
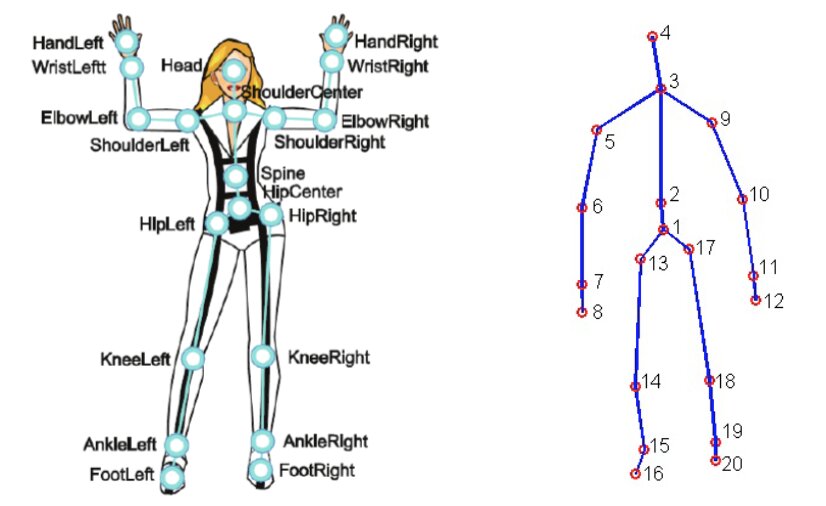
Для цього проєкту використовувався набір даних MSR Daily Activity 3D (Рисунок 2), з деякими модифікаціями. Цей набір даних містить 16 людських дій, зібраних за допомогою сенсора Xbox Kinetic і збережених у вигляді скелетів. Скелети — це масив реальних координат у форматі (x, y, z) для 20 суглобів людини, записаних в одному кадрі. Ось рисунок, який показує, що таке скелет:
Щоб виконати передбачення людських дій, необроблені дані мають бути представлені у формі, яку можна обробити за допомогою SVM. Для цього проєкту використовувалися такі представлення:
- Представлення Relative Angles and Distances (RAD)
- Представлення Histogram of Joint Position Differences (HJPD)
Для класифікації представлення надсилається до SVM, на основі LIBSVM, щоб створити модель, яка може передбачати людські дії. Буде створено дві моделі: одну з використанням RAD, а іншу з використанням HJPD. Мета полягає в тому, щоб зробити ці моделі якомога точнішими та побачити, яке представлення працює найкраще.
З огляду на це, ось огляд того, що робить код:
- Завантажує необроблені дані з модифікованого набору даних
- Видаляє будь-які дані-викиди та/або помилкові дані із завантаженого набору даних
- Перетворює остаточні необроблені дані у представлення RAD і HJPD
- Представлення надсилаються до налаштованих SVM, щоб згенерувати дві моделі
- Потім обидві моделі отримують тестові необроблені дані, і генерується матриця помилок, щоб виміряти, як саме працювала(ли) модель(і).
Результати
Після запуску коду та налаштування моделей настільки добре, наскільки це було можливо для мене, ось фінальні матриці помилок для обох моделей RAD і HJPD:
Representation: RAD
Accuracy: 62.5%
LIBSVM Classification 8.0 10.0 12.0 13.0 15.0 16.0
Actual Activity Number
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Representation: HJPD
Accuracy: 70.83%
LIBSVM Classification 8.0 10.0 12.0 13.0 15.0 16.0
Actual Activity Number
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Висновок
Оскільки обидві точності вищі за 50%, цей проєкт був успішним. Також схоже, що представлення HJPD є точнішим представленням для використання в цій класифікації. Завдяки цьому існує модель(і), яка передбачає людські дії, використовуючи дані скелета. Модель(і) тут далекі від ідеалу, але це краще, ніж випадковість. Саме цей проєкт згодом дав початок проєкту Moving Pose.
Додаткові примітки:
- Цей проєкт тестувався на версії Python 3.8.13
- Для цього проєкту використовувався повний набір даних MDA3 і модифікований набір даних MDA3. Модифікований MDA3 містить лише дії 8, 10, 12, 13, 15 і 16. Також модифікована версія має деякі “пошкоджені” точки даних, тоді як повний набір даних — ні.
- Просторово-часове представлення людей на основі 3D-скелетних даних: огляд
- YouTube: Як працює датчик глибини Kinect за 2 хвилини
- Medium: Розуміння суглобів Kinect V2 та системи координат
- Сторінка Kinect у Wikipedia
- Jameco Xbox Kinect
- Інформація про SVM(и) та LibSVM: cjlin libsvm, сторінка libsvm на pypi, і github libsvm
- Логіка та документація SVM і LIBSVM: стаття-посібник cjlin і набір даних cjlin libsvmtools
- Інформація про використаний/модифікований набір даних