Топовый челлендж кодера 8090-х
Оригинальный пост в LinkedIn
GitHub-репозиторий проекта
В пятницу вечером я увидел публичный пост в Twitter/X от Чамата Палихапитии, в котором он объявлял об открытом Top Coder Challenge, проводимом его новой компанией, 8090 Solutions. Принять участие мог любой желающий. Челлендж должен был состояться уже на следующий день, длиться всего 8 часов и заключаться в обратной разработке унаследованной системы с черным ящиком, используя только исторические данные и несколько интервью с сотрудниками.
Я решил ввязаться!
К концу дня я был удостоен чести занять 7-е место из 425 инженеров. Вы можете посмотреть таблицу лидеров ЗДЕСЬ и посмотреть код для этого челленджа ЗДЕСЬ. Но, не буду лукавить, я на самом деле просто надеялся хоть что-то завершить за такой короткий промежуток времени, так что попасть в таблицу лидеров стало для меня неожиданностью и огромной личной победой.
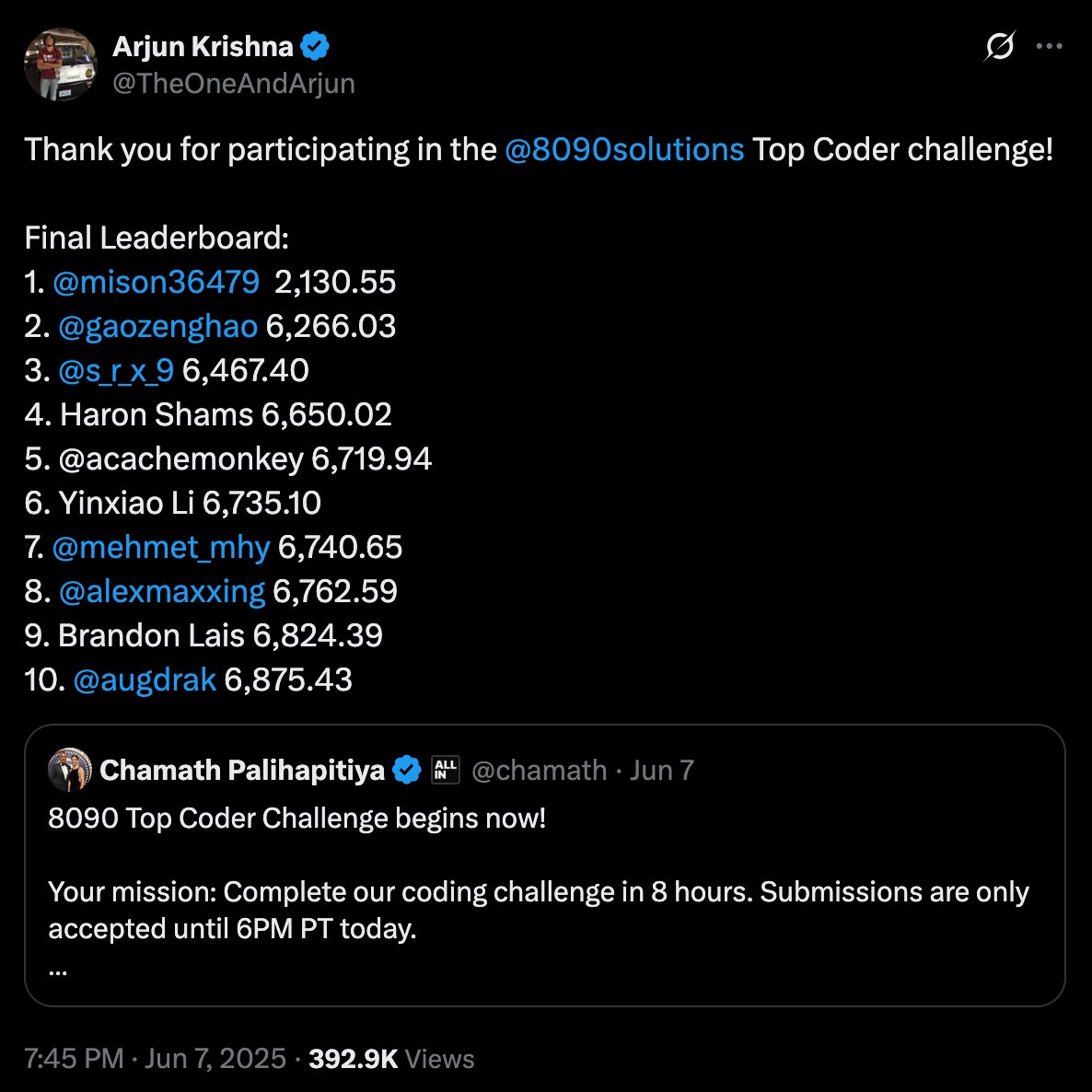
Челлендж был одиночным, и цель состояла в том, чтобы воспроизвести 60-летнюю систему возмещения командировочных расходов с черным ящиком, для которой не было ни исходного кода, ни документации. Нам дали несколько материалов, включая краткое описание продукта, расшифровки интервью с сотрудниками и публичный набор данных, содержащий 1 000 исторических примеров входных данных и ожидаемых выходных данных. На основе этого мне нужно было вывести бизнес-логику, по которой рассчитывались суммы возмещения, и реализовать современную версию, которая могла бы выдавать те же результаты как можно точнее. Отправленные решения оценивались на отдельном скрытом наборе данных, который содержал 5 000 тестовых случаев вместо первоначальных 1 000. Именно этот более крупный закрытый набор в конечном итоге определял ваш итоговый балл и место в рейтинге. Система оценки вознаграждала за точность, где более низкий балл означал, что ваше решение точнее соответствовало скрытому поведению оригинальной системы.
Чтобы справиться с неопределенностью и закономерностями в данных, я использовал классические методы машинного обучения вместе с базовыми эвристиками и программной логикой. Это было тщательное сочетание анализа данных, моделирования признаков и аппроксимации правил на основе несовершенных подсказок.
Вот мой eval-балл для публичного набора из 1 000 данных:
✅ Evaluation Summary
------------------------
Total cases : 1000
Exact matches (<$0.01): 0
Close matches (<$1.00): 17
Average error : $31.15
Score : 3214.93
Разработать решение для такого челленджа за 8 часов было бы почти невозможно без помощи инструментов на базе ИИ, которые облегчили быстрое исследование, интеграцию и тестирование идей.
Это ощущалось как программная археология, совмещенная с живым кодинг-спринтом. Легко один из самых интенсивных и полезных технических челленджей, которые я когда-либо проходил.
Спасибо Чамату Палихапитии и Арджуну Кришне за организацию такого креативного и вдохновляющего челленджа.
Ссылки: