Топ Кодер Челлендж 8090-х
Оригинальный пост в LinkedIn
Репозиторий проекта на GitHub
В пятницу вечером я увидел публичный пост в Twitter/X от Чамата Палихапитии, который объявил об открытом Топ Кодер Челлендже, организованном его новой компанией, 8090 Solutions. Каждый мог присоединиться. Челлендж должен был пройти на следующий день, продлиться всего 8 часов и включать обратное проектирование черного ящика устаревшей системы, используя только исторические данные и несколько интервью с сотрудниками.
Я решил принять участие!
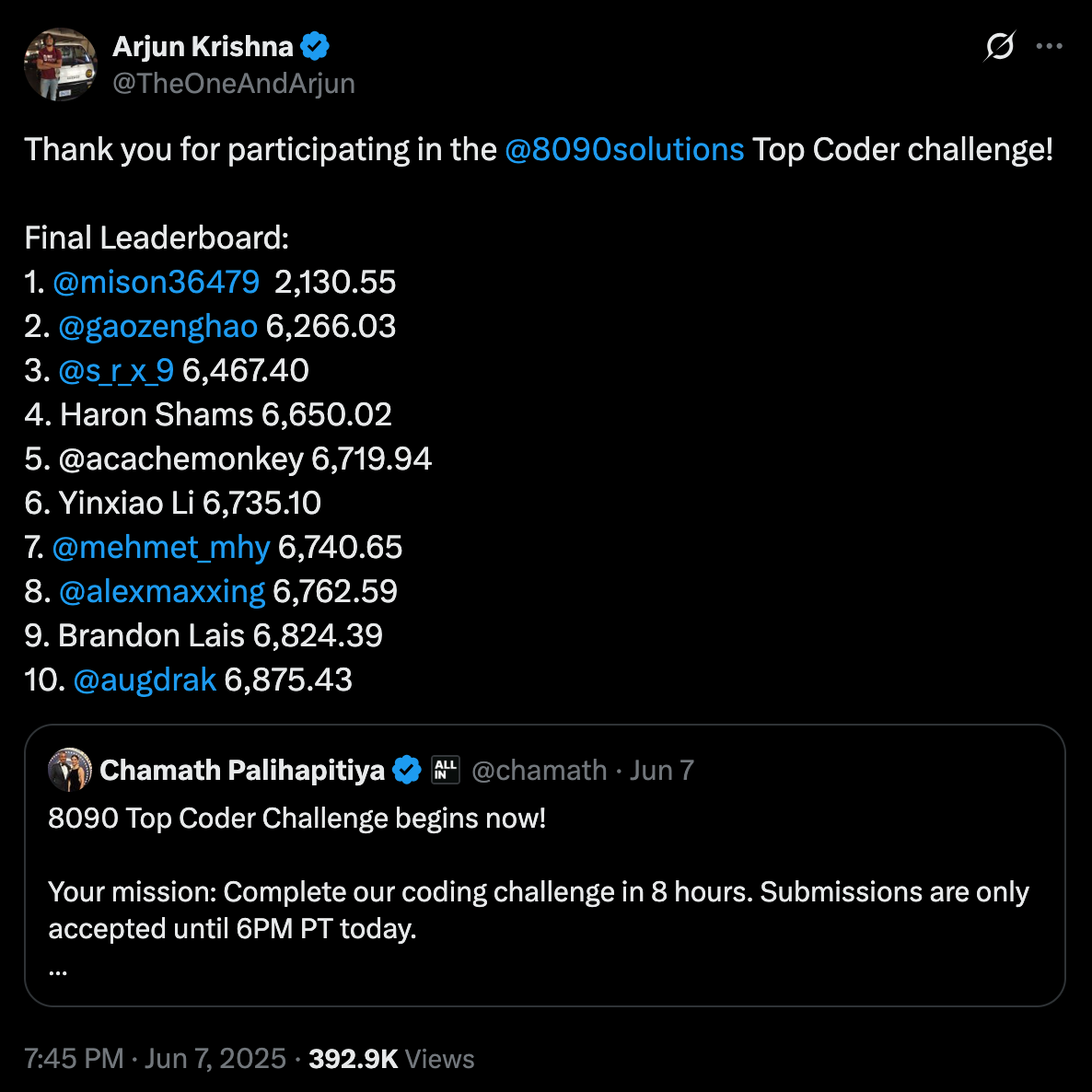
К концу дня я был удостоен чести занять 7-е место из 425 инженеров. Вы можете посмотреть таблицу лидеров ЗДЕСЬ и ознакомиться с кодом для этого челленджа ЗДЕСЬ. Но я не буду лгать, я на самом деле просто надеялся завершить что-то за этот короткий промежуток времени, поэтому попадание в таблицу лидеров стало для меня сюрпризом и огромной личной победой.
Челлендж был индивидуальным, и цель заключалась в том, чтобы воспроизвести 60-летнюю систему возмещения расходов на поездки, у которой не было исходного кода и документации. Нам были предоставлены несколько артефактов, включая краткое описание продукта, стенограммы интервью с сотрудниками и публичный набор данных, содержащий 1,000 исторических примеров входных данных и ожидаемых выходных данных. На основе этого мне нужно было вывести бизнес-логику, по которой рассчитывались суммы возмещения, и реализовать современную версию, которая могла бы выдавать такие же результаты, как можно ближе. Отправленные работы оценивались на отдельном скрытом наборе данных, который содержал 5,000 тестовых случаев вместо оригинальных 1,000. Этот более крупный частный набор в конечном итоге определял ваш окончательный балл и рейтинг. Система оценки вознаграждала точность, где более низкий балл означал, что ваше решение более точно соответствовало скрытому поведению оригинальной системы.
Чтобы справиться с неопределенностью и паттернами в данных, я использовал классические методы машинного обучения наряду с базовыми эвристиками и программной логикой. Это было осторожное сочетание анализа данных, моделирования признаков и приближения правил на основе несовершенных подсказок.
Вот мой eval балл для публичного набора данных из 1,000:
✅ Резюме оценки
------------------------
Всего случаев : 1000
Точные совпадения (<$0.01): 0
Близкие совпадения (<$1.00): 17
Средняя ошибка : $31.15
Балл : 3214.93
Разработка решения для такого челленджа за 8 часов была бы почти невозможна без помощи инструментов на базе ИИ, которые облегчали бы быстрое исследование, интеграцию и тестирование идей.
Это было похоже на археологию программного обеспечения, объединенную с живым кодированием. Легко одно из самых интенсивных и вознаграждающих технических испытаний, которые я проходил.
Спасибо Чамату Палихапитии и Арджуну Кришне за организацию такого креативного и вдохновляющего челленджа.
Ссылки: