Прогнозирование человеческих действий
Подробности
Этот проект был проектом #3 для класса Человекоцентрированная робототехника (CSCI473) профессора Чжана в Колорадском университете в Майне в весеннем семестре 2020 года. Он был разработан для предоставления введения в машинное обучение в робототехнике с использованием методов опорных векторов (SVM). Оригинальные результаты проекта/описание можно просмотреть здесь.
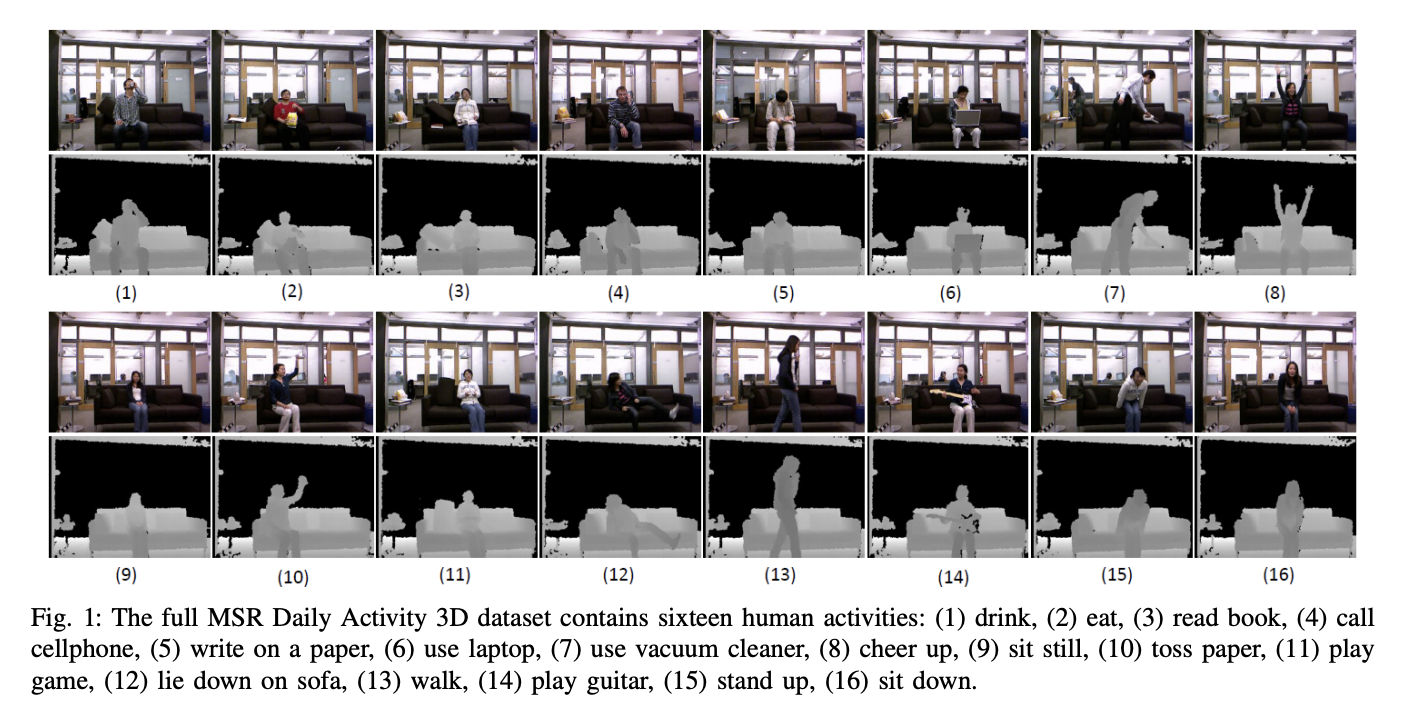
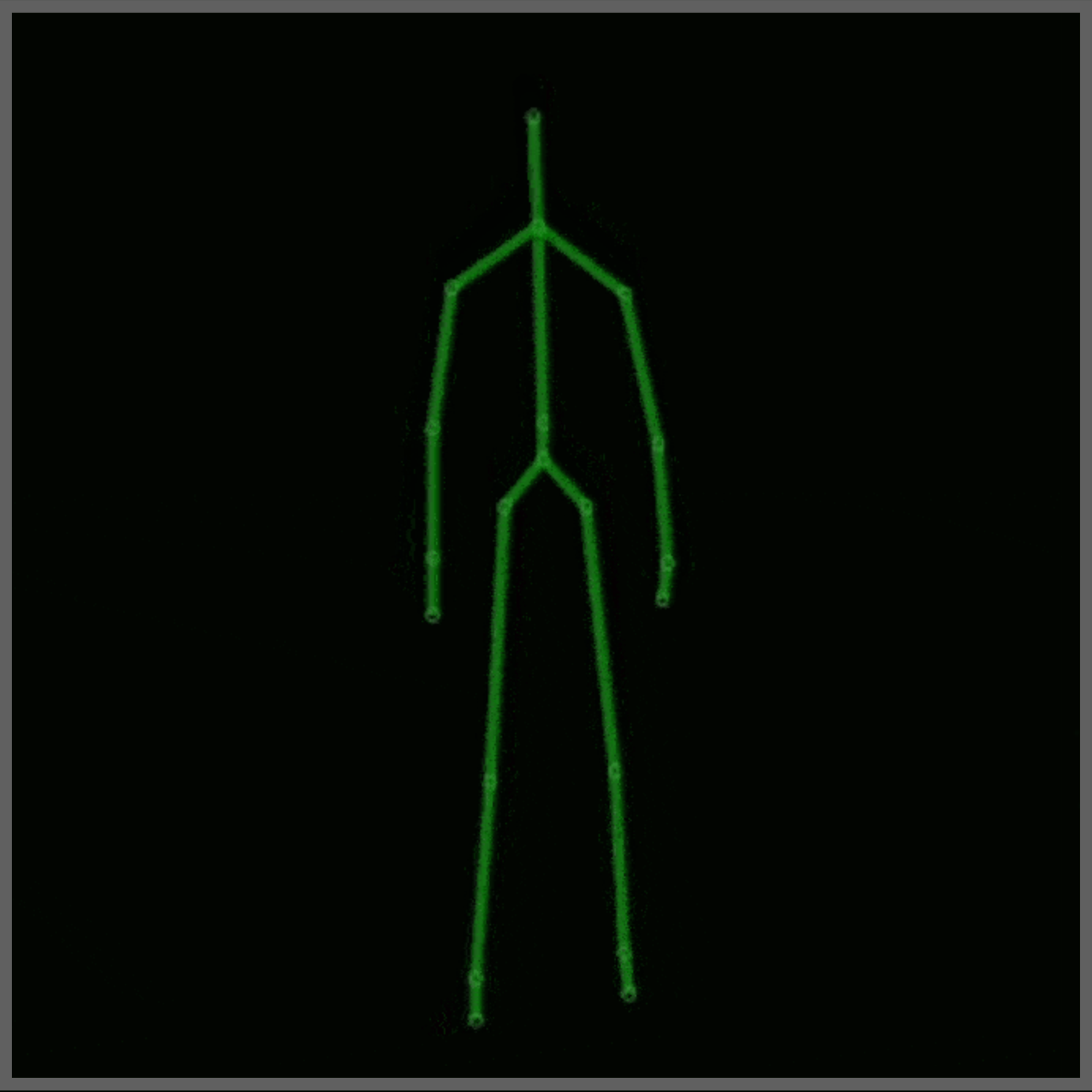
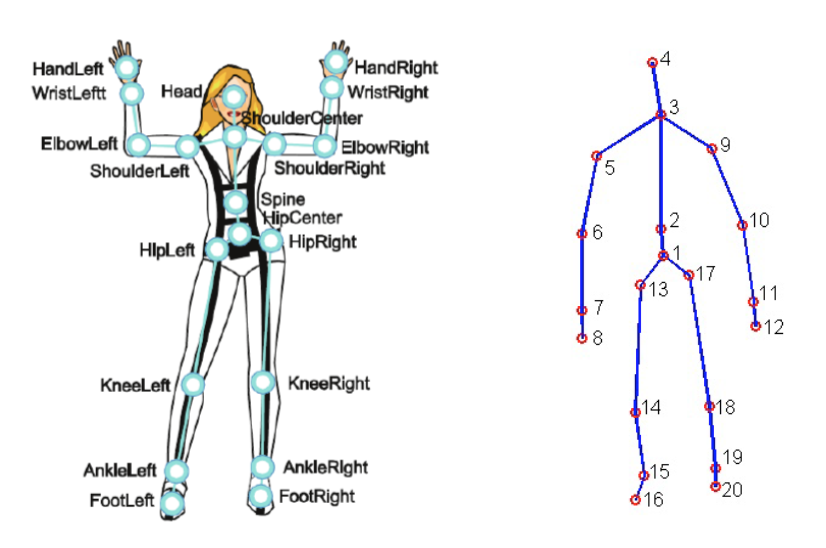
Для этого проекта использовался Набор данных MSR Daily Activity 3D (Рисунок 2) с некоторыми модификациями. Этот набор данных содержит 16 человеческих действий, собранных с помощью датчика Xbox Kinetic и сохраненных в виде скелетов. Скелеты представляют собой массив реальных (x, y, z) координат 20 суставов человека, записанных в одном кадре. Вот рисунок, который показывает, что такое скелет:
Чтобы достичь прогнозирования человеческих действий, необработанные данные должны быть представлены в форме, которая может быть обработана SVM. Для этого проекта использовались следующие представления:
- Представление относительных углов и расстояний (RAD)
- Представление гистограммы различий положений суставов (HJPD)
Для классификации представления отправляются в SVM, работающий на LIBSVM, чтобы создать модель, которая может прогнозировать человеческие действия. Будут созданы две модели: одна с использованием RAD и другая с использованием HJPD. Цель состоит в том, чтобы сделать эти модели как можно более точными и увидеть, какое представление работает лучше.
Зная это, вот обзор того, что делает код:
- Загружает необработанные данные из модифицированного набора данных
- Удаляет любые выбросы и/или ошибочные данные из загруженного набора данных
- Преобразует окончательные необработанные данные в представления RAD и HJPD
- Представления отправляются в настроенные SVM для генерации двух моделей
- Обе модели затем получают тестовые необработанные данные, и создается матрица путаницы для измерения того, как модели работали.
Результаты
После запуска кода и настройки моделей наилучшим образом, вот окончательная матрица путаницы для моделей RAD и HJPD:
Представление: RAD
Точность: 62.5%
Классификация LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
Фактический номер действия
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Представление: HJPD
Точность: 70.83%
Классификация LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
Фактический номер действия
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Заключение
Поскольку обе точности превышают 50%, этот проект был успешным. Кроме того, представление HJPD, похоже, является более точным представлением для этой классификации. Таким образом, есть модель(и), которые прогнозируют человеческие действия, используя данные скелета. Модель(и) здесь далеки от идеала, но они лучше, чем случайные. Этот проект стал основой для проекта Движущаяся поза позже.
Дополнительные заметки:
- Этот проект был протестирован на Python версии 3.8.13
- Для этого проекта использовался полный набор данных MDA3 и модифицированный набор данных MDA3. Модифицированный MDA3 содержит только действия 8, 10, 12, 13, 15 и 16. Также в модифицированной версии есть некоторые “поврежденные” точки данных, в то время как полный набор данных этого не имеет.
- Пространственно-временное представление людей на основе 3D-скелетных данных: Обзор
- YouTube: Как работает датчик глубины Kinect за 2 минуты
- Medium: Понимание суставов и системы координат Kinect V2
- Страница Википедии Kinect
- Jameco Xbox Kinect
- Информация о SVM(ах) и LibSVM: cjlin libsvm, страница libsvm на pypi, и libsvm на github
- Логика и документация SVM и LIBSVM: cjlin guide paper и cjlin libsvmtools datasets
- Информация о используемом/модифицированном наборе данных