Desafio Top Coder da 8090
Post Original no LinkedIn
Repositório GitHub do Projeto
Na noite de sexta-feira, vi uma postagem pública no Twitter/X de Chamath Palihapitiya anunciando um Top Coder Challenge aberto hospedado por sua nova empresa, 8090 Solutions. Qualquer pessoa poderia participar. O desafio ocorreria no dia seguinte, duraria apenas 8 horas e envolveria engenharia reversa de um sistema legado de caixa preta usando apenas dados históricos e algumas entrevistas com funcionários.
Decidi entrar!
No final do dia, tive a honra de ficar em 7º lugar entre 425 engenheiros. Você pode conferir a classificação AQUI e conferir o código deste desafio AQUI. Mas, não vou mentir, eu estava honestamente apenas esperando terminar algo dentro desse curto período de tempo, então aparecer na classificação foi uma surpresa e uma grande vitória pessoal para mim.
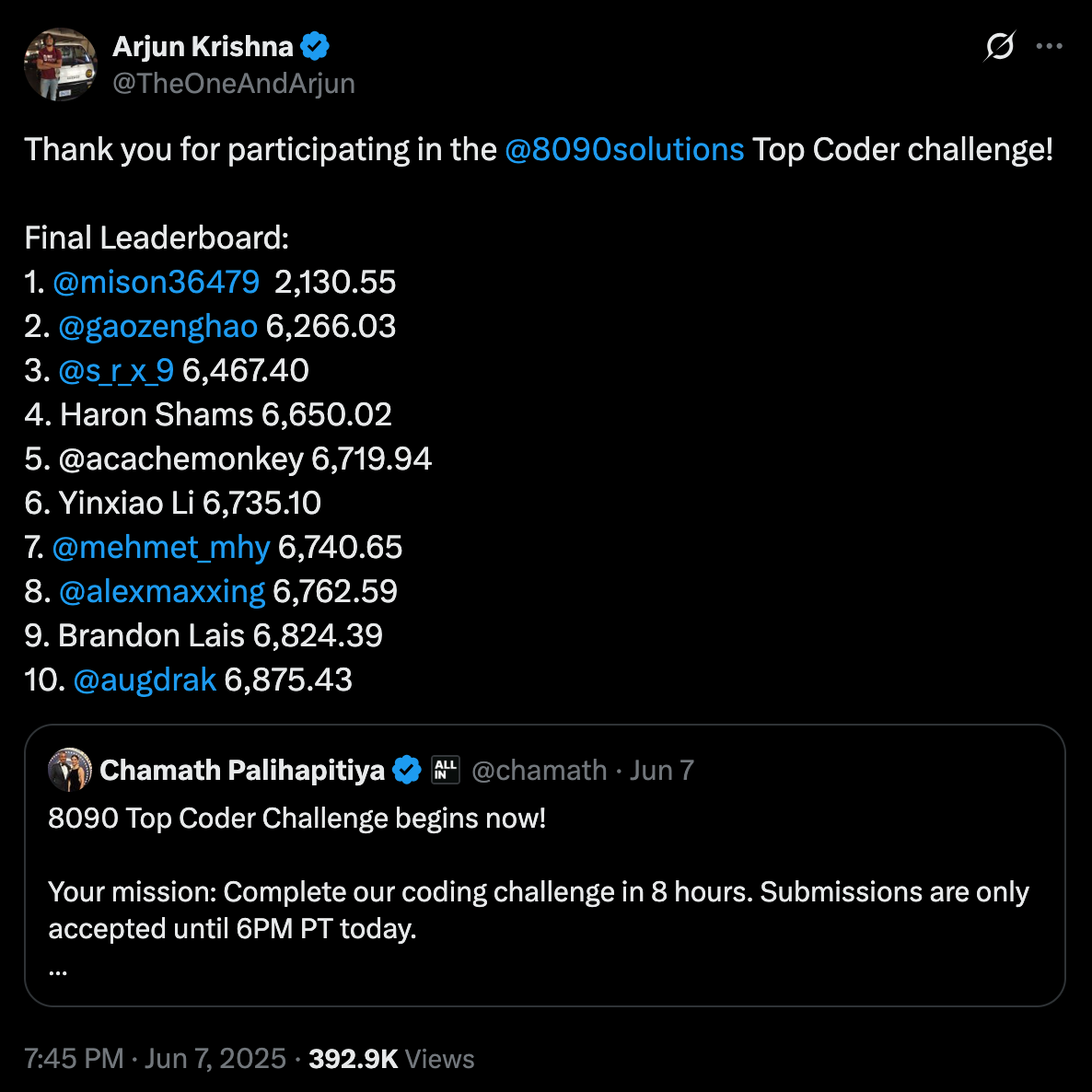
O desafio era solo, e o objetivo era replicar um sistema de reembolso de viagens de caixa preta com 60 anos, que não tinha código-fonte nem documentação. Recebemos alguns artefatos, incluindo um resumo do produto, transcrições de entrevistas com funcionários e um conjunto de dados público contendo 1.000 exemplos históricos de entradas e saídas esperadas. A partir disso, tive que inferir a lógica de negócios por trás de como os valores de reembolso eram calculados e implementar uma versão moderna que pudesse produzir os mesmos resultados o mais próximo possível. As submissões foram avaliadas em um conjunto de dados oculto separado que continha 5.000 casos de teste, em vez dos 1.000 originais. Esse conjunto privado maior foi o que determinou, em última análise, sua pontuação final e classificação. O sistema de pontuação recompensava a precisão, onde uma pontuação menor significava que sua solução correspondia mais de perto ao comportamento oculto do sistema original.
Para enfrentar a incerteza e os padrões nos dados, usei técnicas clássicas de aprendizado de máquina juntamente com heurísticas básicas e lógica programática. Foi uma combinação cuidadosa de análise de dados, modelagem de recursos e aproximação de regras baseada em pistas imperfeitas.
Este foi o meu eval score para o conjunto de dados público de 1.000:
✅ Evaluation Summary
------------------------
Total cases : 1000
Exact matches (<$0.01): 0
Close matches (<$1.00): 17
Average error : $31.15
Score : 3214.93
Desenvolver uma solução para um desafio assim em 8 horas teria sido quase impossível sem a ajuda de ferramentas alimentadas por IA que facilitaram a exploração, integração e teste rápido de ideias.
Parecia arqueologia de software combinada com um sprint de codificação ao vivo. Facilmente um dos desafios técnicos mais intensos e gratificantes que já fiz.
Obrigado a Chamath Palihapitiya e Arjun Krishna por organizar um desafio tão criativo e inspirador.
Links: