Predizendo Ações Humanas
Detalhes
Este projeto foi o projeto #3 para a classe de Robótica Centrada no Ser Humano (CSCI473) do Dr. Zhang na Colorado School of Mines durante o semestre da primavera de 2020. Ele foi projetado para fornecer uma introdução ao aprendizado de máquina em robótica por meio do uso de Máquinas de Vetores de Suporte (SVM). Os entregáveis/descrição originais do projeto podem ser visualizados aqui.

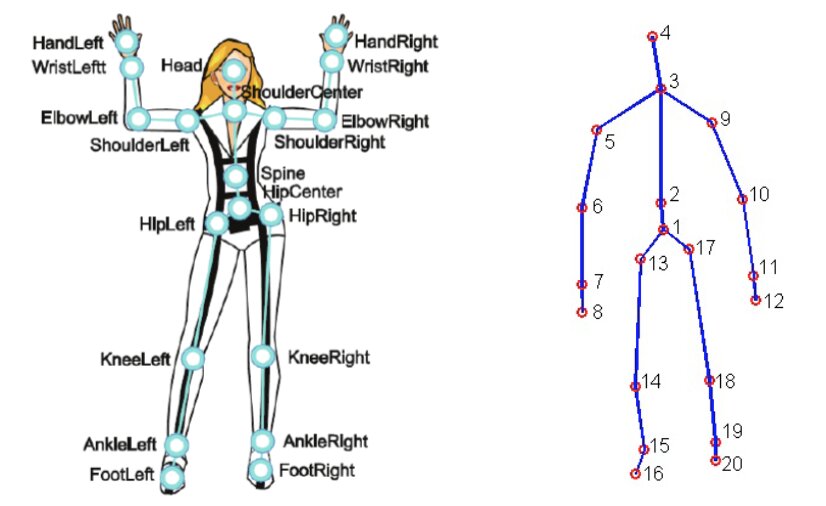
Para este projeto, foi usado o MSR Daily Activity 3D Dataset (Figura 2), com algumas modificações. Este conjunto de dados contém 16 atividades humanas coletadas de um sensor Xbox Kinetic e armazenadas como esqueletos. Esqueletos são um array de coordenadas reais do mundo, (x, y, z), de 20 articulações de um humano registradas em um quadro. Aqui está uma figura que mostra o que é um esqueleto:
Para alcançar a predição de ações humanas, os dados brutos devem ser representados em uma forma que possa ser processada por um SVM. Para este projeto, foram usadas as seguintes representações:
- Representação de Ângulos e Distâncias Relativas (RAD)
- Representação de Histograma de Diferenças de Posição das Articulações (HJPD)
Para classificação, a(s) representação(ões) é(são) enviada(s) para um SVM, alimentado por LIBSVM, para criar um modelo que possa prever ações humanas. Dois modelos serão criados, um usando RAD e outro usando HJPD. O objetivo é tornar esses modelos o mais precisos possível e ver qual representação tem o melhor desempenho.
Sabendo disso, aqui está uma visão geral do que o código faz:
- Carregar os dados brutos do conjunto de dados modificado
- Remover quaisquer dados discrepantes e/ou de erro do conjunto de dados carregado
- Converter os dados brutos finais em representações RAD e HJPD
- As representações são enviadas para SVM(s) ajustados para gerar dois modelos
- Os dois modelos então recebem dados brutos de teste e uma matriz de confusão é gerada para medir como o(s) modelo(s) se saiu(ram).
Resultados
Após executar o código e ajustar os modelos da melhor forma possível, aqui estão as matrizes de confusão finais para os modelos RAD e HJPD:
Representation: RAD
Accuracy: 62.5%
LIBSVM Classification 8.0 10.0 12.0 13.0 15.0 16.0
Actual Activity Number
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Representation: HJPD
Accuracy: 70.83%
LIBSVM Classification 8.0 10.0 12.0 13.0 15.0 16.0
Actual Activity Number
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Conclusão
Como ambas as precisões estão acima de 50%, este projeto foi um sucesso. Além disso, a representação HJPD parece ser a representação mais precisa para usar para estas classificações. Com isso, há um(s) modelo(s) que prevê(em) ações humanas usando dados esqueléticos. O(s) modelo(s) aqui está(ão) longe de ser perfeito(s), mas é melhor do que aleatório. Este projeto foi o que deu origem posteriormente ao projeto Moving Pose.
Notas Adicionais:
- Este projeto foi testado na versão 3.8.13 do Python
- Para este projeto, são usados o conjunto de dados MDA3 completo e um conjunto de dados MDA3 modificado. O MDA3 modificado contém apenas as atividades 8, 10, 12, 13, 15 e 16. Além disso, a versão modificada tem alguns pontos de dados “corrompidos” nela, enquanto o conjunto de dados completo não tem.
- Representação Espaço-Tempo de Pessoas Baseada em Dados Esqueléticos 3D: Uma Revisão
- YouTube: Como o Sensor de Profundidade Kinect Funciona em 2 Minutos
- Medium: Entendendo as Articulações e o Sistema de Coordenadas do Kinect V2
- Página da Wikipédia do Kinect
- Jameco Xbox Kinect
- Informações sobre SVM(s) e LibSVM: cjlin libsvm, página do libsvm no pypi, e libsvm github
- Lógica e documentação de SVM & LIBSVM: papel guia do cjlin e conjuntos de dados cjlin libsvmtools
- Informações Sobre o Conjunto de Dados Usado/Modificado