Construindo o Labeler NearBy
Table of Contents

Meu Primeiro Hackathon
Durante as partes finais do verão de 2022, eu realmente queria trabalhar em um projeto empolgante. Eu tinha acabado de terminar minha graduação e estava trabalhando em tempo integral como engenheiro de software. Eu realmente queria me dedicar a um projeto paralelo e, na época, eu tinha tempo livre suficiente para isso. Eu realmente não sabia no que trabalhar, até que descobri um site chamado Devpost em agosto de 2022. Devpost é um site que hospeda competições de software chamadas hackathons. Enquanto navegava no Devpost, descobri um hackathon chamado NEAR MetaBUILD III, que foi um hackathon organizado pela organização NEAR Protocol.
O que é NEAR?
O NEAR Protocol é uma blockchain que suporta contratos inteligentes e a criptomoeda NEAR. É principalmente conhecido por ter taxas de transação muito baixas, suportar contratos inteligentes, ter sua própria rede de testes oficial e um ótimo ambiente para desenvolvedores, devido ao fato de que você pode escrever contratos inteligentes em Rust e/ou JavaScript. Você pode ter uma visão melhor do NEAR Protocol através do incrível vídeo da CoinGecko:
Durante esse tempo, a Coinbase começou a apoiar oficialmente o NEAR Protocol como uma moeda negociável em sua plataforma. Isso foi um grande feito, pois a Coinbase é conhecida por ser muito seletiva em relação às moedas que apoiam em sua plataforma. Isso ajudou a tornar o NEAR uma plataforma mais confiável. Você ainda pode negociar NEAR na Coinbase até hoje.
Por que Comprometer-se?
Depois de passar algum tempo pensando, decidi dedicar meu tempo para competir no hackathon NEAR MetaBUILD III. Meu raciocínio foi o seguinte:
- Cripto não vai desaparecer e é uma tecnologia que vai ficar. Então, fazia sentido investir algum tempo aprendendo a tecnologia.
- O hackathon tinha grandes recompensas, variando de $20.000 a $100.000 em NEAR se você fosse um dos vencedores.
- O hackathon tinha um prazo específico, o que significava que o projeto não poderia se arrastar por meses, como muitos projetos paralelos geralmente fazem.
- O projeto seria uma ótima experiência de aprendizado e uma ótima introdução aos hackathons.
- No pior dos casos, o hackathon me permitiria criar um ótimo projeto para mostrar no meu currículo.
Com tudo isso em mente, liguei para meu amigo próximo da faculdade em 26 de agosto de 2022 e começamos a planejar para este hackathon. O hackathon estava programado para começar em 23 de setembro de 2023 e concluir em 21 de novembro de 2022. Embora o prazo tenha sido estendido até 24 de novembro de 2023 no final do hackathon. Como estávamos um mês adiantados, decidimos passar esse tempo aprendendo e fazendo brainstorming sobre o que trabalharíamos para este hackathon de 2 meses. Durante aquele primeiro mês, obtivemos uma visão geral sobre cripto e blockchains. Revisamos e praticamos na testnet do NEAR, revisamos o SDK do NEAR e implantamos alguns contratos inteligentes.
A Ideia
Depois de obter uma ótima introdução a tudo sobre blockchain e NEAR, começamos a fazer brainstorming de ideias. Eu queria que este projeto fosse algo que não fosse apenas um “projeto de hackathon”, mas algo que pudesse se tornar um produto que outros pudessem usar e servir como um exemplo de como a cripto poderia ser útil para coisas além de apenas negociação.
Com isso em mente, inicialmente decidimos criar algo semelhante ao Blueprint do Unreal Engine, mas para a criação e implantação fácil de contratos inteligentes na blockchain NEAR sem a necessidade de codificação. No entanto, uma semana antes do início do hackathon, abandonamos a ideia porque simplesmente não fazia sentido. Por que alguém se daria ao trabalho de usar nossa ferramenta para criar contratos inteligentes NEAR se ainda não houvesse um caso de uso prático para eles? Seria como desenvolver uma ferramenta que muitas pessoas não precisavam.
Com apenas uma semana restante antes do início do hackathon, começamos a fazer brainstorming novamente e nos estabelecemos nesta ideia:
Uma plataforma descentralizada onde pesquisadores de IA podem terceirizar
a rotulagem de dados para rotuladores ao redor do mundo
Nomeamos o projeto de “Labeler NearBy”. Nossa decisão de escolher essa ideia foi baseada nas seguintes razões:
- O desenvolvimento de IA requer rotulagem humana de dados para treinamento.
- Encontrar e gerenciar indivíduos qualificados para rotular conjuntos de dados específicos é desafiador.
- A ideia já foi implementada com sucesso por uma empresa chamada Scale AI, como evidenciado por como eles encontraram o ajuste produto-mercado.
- Serviços centralizados como a Scale AI levantam preocupações, pois as organizações têm que enviar seus dados para a empresa de rotulagem, que então terceiriza rotuladores humanos globalmente. Após o processo de rotulagem, a empresa retorna os dados rotulados para a organização. Isso renuncia o controle sobre dados valiosos de treinamento, que poderiam ser usados pela empresa de rotulagem para treinar seus próprios modelos. Descentralizar esse serviço parecia uma solução lógica.
- Encontramos muito poucos projetos no espaço de aplicativos descentralizados (dApp) trabalhando nessa ideia, proporcionando uma oportunidade para nós inovarmos e pioneirarmos nessa área.
Para ajudar a reduzir a complexidade, decidimos que o Labeler NearBy só suportaria dados de imagem por enquanto.
Submissão
Com a ideia escolhida e o hackathon oficialmente em andamento, meu amigo e eu começamos a construir o Labeler NearBy. Trabalhamos em nosso projeto por 2 meses até submetermos o rascunho final do nosso projeto ao Devpost em 24 de novembro de 2022. Submetemos nosso projeto no Devpost e também criamos uma cópia de nossa submissão no Github. Este blog não cobre todos os aspectos técnicos e o processo de desenvolvimento do Labeler NearBy. Sabendo disso, para saber mais sobre como o Labeler NearBy funciona ou para ver nossa submissão final, visite um dos seguintes links:
O Labeler NearBy consiste em duas bases de código: ln-researcher e ln-labeler. Essas bases de código são completamente de código aberto sob a licença MIT e podem ser visualizadas através dos seguintes links:
Aqui está uma visão geral de como o Labeler NearBy (LN) funcionaria:
Um pesquisador requer imagens rotuladas para treinar seu modelo de IA. Para conseguir isso, o pesquisador utiliza o LN para hospedar seus dados e fornecer um meio para que os rotuladores rotulem seus dados. Isso é alcançado através do ln-researcher, um serviço web auto-hospedado que consiste em uma API, os contratos inteligentes do pesquisador e um banco de dados Postgres local. Para o rotulador, uma interface web é (teria sido) fornecida, permitindo que eles acessem e rotulem as imagens do pesquisador. Enquanto o processo de rotulagem está em andamento, uma imagem é rotulada três vezes por diferentes rotuladores. Apenas o rotulador com os melhores rótulos, determinado através de um sistema de votação, é recompensado com moedas NEAR. O aplicativo web responsável por esse processo é chamado ln-labeler. O pesquisador financia cada operação de rotulagem, e as moedas NEAR podem ser facilmente convertidas em dólares através da Coinbase. Toda a logística de transação é gerenciada por contratos inteligentes hospedados na blockchain do NEAR Protocol.
Você pode ver nosso vídeo de demonstração do Labeler NearBy para o hackathon aqui:
Maior Conquista
O recurso do qual mais me orgulho de implementar é uma função chamada getImage(). Esta função serve como um ponto de extremidade da API em ln-researcher e desempenha um papel crucial no pipeline de dados entre pesquisadores e rotuladores no Labeler NearBy (LN).
Este ponto de extremidade da API permite que os pesquisadores distribuam suas imagens de forma segura e confiável para rotulagem. As atribuições de rotulagem são gerenciadas através de contratos inteligentes NEAR na blockchain do NEAR Protocol, enquanto os dados da imagem são hospedados pelo pesquisador através do ln-researcher.
O ponto de extremidade realiza uma série de verificações de segurança para garantir que apenas o rotulador designado possa acessar a imagem. Isso inclui verificar a assinatura da solicitação e checar o contrato inteligente associado para confirmar a existência da tarefa e sua atribuição ao rotulador que está solicitando.
Uma vez que a solicitação é validada na API auto-hospedada do pesquisador ln-researcher, a função recupera a imagem do banco de dados Postgres local, criptografa a imagem e a entrega ao rotulador autorizado, que pode então descriptografar a imagem para rotulagem. Simultaneamente, a função atualiza o status da imagem no banco de dados, indicando o progresso da rotulagem da imagem. Durante todo esse processo, chaves RSA de ambos, o pesquisador e o rotulador, são usadas para autenticar. Enquanto a criptografia AES é usada para criptografar a imagem.
Este ponto de extremidade desempenha um papel crítico na gestão da distribuição segura e controlada de imagens de pesquisadores para rotuladores. Ele garante a transferência segura de dados e rastreia e gerencia efetivamente o processo de rotulagem de imagens. Além disso, esse processo tem o potencial de eliminar a necessidade de usar HTTPS, pelo menos para este ponto de extremidade.
Este ponto de extremidade/função específica foi testado e provado funcional. Abaixo está um diagrama ilustrando a funcionalidade geral do Labeler NearBy, incluindo uma representação clara de como o ponto de extremidade/função mencionado acima funciona:
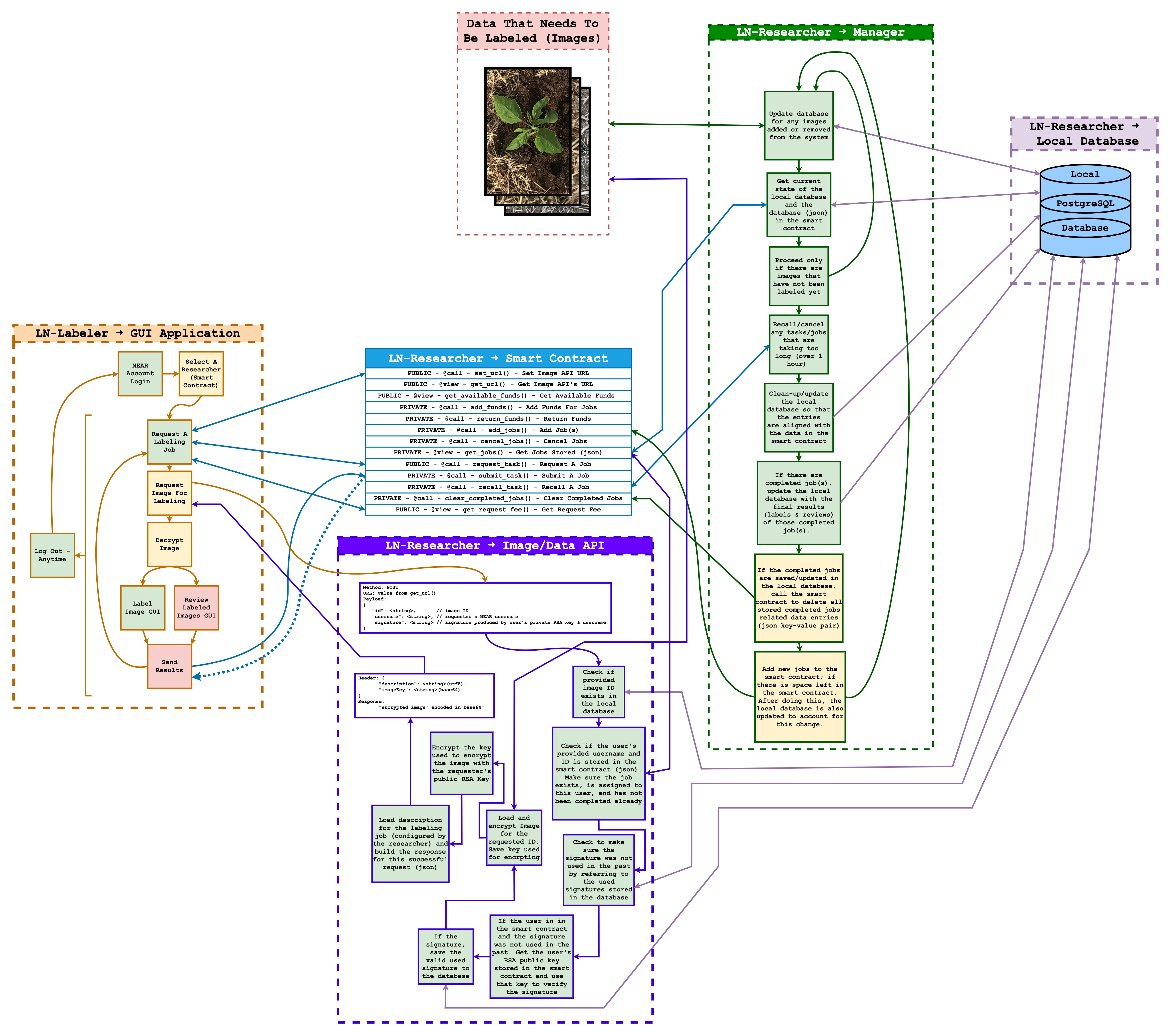
Resultado
Lamentavelmente, a triste realidade é que não conseguimos concluir totalmente este projeto até o prazo do hackathon. A maior parte do projeto foi concluída, como o ln-researcher, mas o frontend (ln-labeler) não foi finalizado e não conseguimos implantar uma demonstração ao vivo. Embora o backend (ln-researcher) estivesse basicamente concluído, sem um frontend funcionando corretamente e sem uma demonstração ao vivo, ninguém pôde experimentar a ideia do Labeler NearBy. Não só isso, mas os juízes não puderam experimentar o projeto e, em vez disso, tiveram que ler a submissão, analisar o código e/ou tentar executá-lo por conta própria. O que fez com que nossas chances de ganhar caíssem para basicamente zero por cento. Isso foi confirmado em 15 de dezembro de 2022, quando os vencedores do hackathon foram anunciados, e não estávamos entre eles.
Perdendo
Não vou esconder o fato de que o resultado final deste hackathon foi desanimador. Meses foram investidos neste projeto e eu tinha uma grande visão para ele, pois achava que proporcionaria uma ferramenta muito útil para os pesquisadores.
Eu tenho um padrão claro para os projetos que empreendo: ou eles têm sucesso ou falham; não há meio termo. Portanto, este projeto foi um fracasso porque não foi totalmente concluído até o prazo e permaneceu inacessível para usuários potenciais.
Mas é importante lembrar que o fracasso é uma parte natural da vida. Nossas conquistas são construídas sobre as lições que aprendemos com nossos fracassos. Embora o resultado deste hackathon tenha sido desanimador, ainda assim forneceu insights valiosos quando se trata de desenvolver e construir um projeto/produto.
Lições Aprendidas
As principais lições que tirei dessa experiência foram as seguintes:
- O projeto que escolhemos exigia muitos recursos construídos antecipadamente antes que pudéssemos iterar sobre ele. O que quero dizer com isso? Bem, este projeto exigia que quase todos os componentes da ideia fossem construídos antes que pudéssemos até mesmo testar a ideia. Teria feito mais sentido escolher um projeto que tivesse menos componentes essenciais para funcionar. Ao fazer isso, poderíamos ter construído os componentes essenciais mais rapidamente e iterado sobre o projeto mais cedo. Assim, poderíamos ter cumprido o prazo mais facilmente e feito um projeto que poderia ter sido mais simples, mas mais completo. A YC, uma aceleradora de startups de tecnologia, enfatiza que você deve lançar rapidamente, conversar com os usuários e iterar. Deveríamos ter feito isso com nosso projeto para este hackathon.
- Subestimamos quanto tempo este projeto levaria para ser construído. Este foi nosso primeiro hackathon e nossa primeira vez fazendo uma aplicação descentralizada (dapp). Não só isso, mas eu estava trabalhando em tempo integral como engenheiro de software e meu amigo estava completando seu mestrado. No entanto, achamos que 2 meses seriam suficientes. Teria feito mais sentido reduzir o escopo do projeto e/ou encontrar mais um membro da equipe que pudesse ter reduzido nossa carga de trabalho.
- Winston Churchill afirmou famosamente: “A perfeição é o inimigo do progresso”. Eu estava tratando este projeto como um produto de negócio para consumidor (B2C), quando na realidade este era apenas um projeto de hackathon e, no máximo, um produto mínimo viável (MVP). Portanto, no início, perdi muito tempo em pequenos detalhes quando deveria ter me concentrado em fazer as funcionalidades principais funcionarem adequadamente.
Além dessas lições valiosas, adquiri novas habilidades que se mostraram inestimáveis tanto em meus projetos pessoais quanto em meus empreendimentos profissionais. Essas habilidades incluem:
- Desenvolvimento de APIs através de Node.js, JavaScript e Express.js
- Configuração e uso do PostgreSQL para gerenciamento de dados
- Incorporação do PostgreSQL no desenvolvimento de APIs usando pacotes como PG.
- Utilização de RSA (criptografia assimétrica) e AES (criptografia simétrica) para segurança de dados aprimorada.
Conclusão
No geral, estou feliz por termos participado deste hackathon, apesar de estar decepcionado com o resultado final. Sou grato pelas lições valiosas e habilidades que adquiri ao trabalhar no Labeler NearBy, pois elas me tornaram um desenvolvedor melhor e contribuíram significativamente para o desenvolvimento do meu próximo projeto: Notify-Cyber.
Outras Notas
- Eu posso voltar ao Labeler NearBy, mas por enquanto, este projeto está em “longa pausa”
- Atualmente, o Labeler NearBy deve funcionar SOMENTE na testnet da NEAR. Ele precisa de mais desenvolvimento, testes e auditoria.