ਲੈਬਲਰ ਨਿਅਰਬਾਈ ਬਣਾਉਣਾ
Table of Contents

ਮੇਰਾ ਪਹਿਲਾ ਹੈਕਾਥਾਨ
ਗਰਮੀ ਦੇ 2022 ਦੇ ਬਾਅਦੀ ਹਿੱਸਿਆਂ ਦੌਰਾਨ, ਮੈਂ ਸੱਚਮੁੱਚ ਇਕ ਰੋਚਕ ਪ੍ਰੋਜੈਕਟ ‘ਤੇ ਕੰਮ ਕਰਨ ਦੀ ਇੱਛਾ ਰੱਖਦਾ ਸੀ। ਮੈਂ ਆਪਣੀ ਅੰਡਰਗ੍ਰੈਜੂਏਟ ਪੜਾਈ ਹਾਲ ਹੀ ਵਿੱਚ ਮੁਕੰਮਲ ਕੀਤੀ ਸੀ ਅਤੇ ਪੂਰੇ ਸਮੇਂ ਇੱਕ ਸਾਫਟਵੇਅਰ ਇੰਜੀਨੀਅਰ ਵਜੋਂ ਕੰਮ ਕਰ ਰਿਹਾ ਸੀ। ਮੈਂ ਸਾਈਡ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਸਮਰਪਿਤ ਹੋਣਾ ਚਾਹੁੰਦਾ ਸੀ ਅਤੇ ਉਸ ਸਮੇਂ ਮੇਰੇ ਕੋਲ ਇਹ ਕਰਨ ਲਈ ਕਾਫੀ ਖਾਲੀ ਸਮਾਂ ਸੀ। ਮੈਨੂੰ ਅਸਲ ਵਿੱਚ ਪਤਾ ਨਹੀਂ ਸੀ ਕਿ ਕਿਸ ‘ਤੇ ਕੰਮ ਕਰਨਾ ਹੈ, ਜਦ ਤਕ ਮੈਂ ਅਗਸਤ 2022 ਵਿੱਚ ਇੱਕ ਵੈਬਸਾਈਟ ਡੇਵਪੋਸਟ ਨੂੰ ਨਹੀਂ ਲੱਭਿਆ। ਡੇਵਪੋਸਟ ਇੱਕ ਵੈਬਸਾਈਟ ਹੈ ਜੋ ਹੈਕਾਥਾਨ ਨਾਮਕ ਸਾਫਟਵੇਅਰ ਮੁਕਾਬਲਿਆਂ ਦੀ ਮੇਜ਼ਬਾਨੀ ਕਰਦੀ ਹੈ। ਡੇਵਪੋਸਟ ਨੂੰ ਬ੍ਰਾਊਜ਼ ਕਰਦਿਆਂ, ਮੈਂ ਇੱਕ ਹੈਕਾਥਾਨ ਲੱਭਿਆ ਜਿਸਦਾ ਨਾਮ NEAR ਮੈਟਾਬਿਲਡ III ਸੀ ਜੋ ਕਿ NEAR ਪ੍ਰੋਟੋਕੋਲ ਸੰਸਥਾ ਵੱਲੋਂ ਮੀਜ਼ਬਾਨ ਕੀਤਾ ਗਿਆ ਸੀ।
NEAR ਕੀ ਹੈ?
NEAR ਪ੍ਰੋਟੋਕੋਲ ਇੱਕ ਬਲੌਕਚੇਨ ਹੈ ਜੋ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ ਅਤੇ NEAR ਸਿਕ्का ਨੂੰ ਸਮਰਥਨ ਕਰਦਾ ਹੈ। ਇਹ ਮੁੱਖਤੌਰ ‘ਤੇ ਬਹੁਤ ਘੱਟ ਲੈਣਦੇਣ ਫੀਸਾਂ, ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ ਦੀ ਸਮਰਥਾ, ਆਪਣਾ ਅਧਿਕਾਰਤ ਟੈਸਟ ਨੈਟਵਰਕ ਅਤੇ ਇੱਕ ਸ਼ਾਨਦਾਰ ਡਿਵੈਲਪਰ ਵਾਤਾਵਰਨ ਲਈ ਜਾਣਿਆ ਜਾਂਦਾ ਹੈ ਕਿਉਂਕਿ ਤੁਸੀਂ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ Rust ਅਤੇ/ਜਾਂ JavaScript ਵਿੱਚ ਲਿਖ ਸਕਦੇ ਹੋ। ਤੁਸੀਂ NEAR ਪ੍ਰੋਟੋਕੋਲ ਬਾਰੇ ਵਧੇਰੇ ਜਾਣਕਾਰੀ CoinGecko ਦੇ ਸ਼ਾਨਦਾਰ ਵੀਡੀਓ ਰਾਹੀਂ ਪ੍ਰਾਪਤ ਕਰ ਸਕਦੇ ਹੋ:
ਇਸ ਸਮੇਂ ਦੌਰਾਨ, Coinbase ਨੇ ਸਰਕਾਰੀ ਤੌਰ ‘ਤੇ NEAR ਪ੍ਰੋਟੋਕੋਲ ਨੂੰ ਆਪਣੀ ਪਲੇਟਫਾਰਮ ‘ਤੇ ਟਰੇਡ ਕਰਨ ਯੋਗ ਸਿਕ्कੇ ਦੇ ਤੌਰ ‘ਤੇ ਸਹਿਯੋਗ ਦਿੱਤਾ। ਇਹ ਵੱਡੀ ਗੱਲ ਸੀ ਕਿਉਂਕਿ Coinbase ਉਨ੍ਹਾਂ ਸਿੱਕਿਆਂ ਲਈ ਬਹੁਤ ਚੋਣੀਦਾ ਰਹਿੰਦਾ ਹੈ ਜੋ ਉਹ ਆਪਣੇ ਪਲੇਟਫਾਰਮ ‘ਤੇ ਸਹਿਯੋਗ ਦਿੰਦੇ ਹਨ। ਇਸ ਨਾਲ NEAR ਇੱਕ ਜ਼ਿਆਦਾ ਭਰੋਸੇਯੋਗ ਪਲੇਟਫਾਰਮ ਬਣ ਗਿਆ। ਤੁਸੀਂ ਅਜੇ ਵੀ NEAR ਨੂੰ Coinbase ‘ਤੇ ਟਰੇਡ ਕਰ ਸਕਦੇ ਹੋ।
ਕਿਉਂ ਭਾਗ ਲੈਣਾ?
ਕੁਝ ਸਮਾਂ ਸੋਚਣ ਤੋਂ ਬਾਅਦ, ਮੈਂ ਫੈਸਲਾ ਕੀਤਾ ਕਿ ਮੈਂ ਆਪਣਾ ਸਮਾਂ NEAR MetaBUILD III ਹੈਕਾਥਾਨ ਵਿੱਚ ਮੁਕਾਬਲਾ ਕਰਨ ਲਈ ਸਮਰਪਿਤ ਕਰਾਂਗਾ। ਮੇਰਾ ਤਰਕ ਇਹ ਸੀ:
- ਕਰਿਪਟੋ ਹਰਗਿਜ਼ ਨਹੀਂ ਜਾ ਰਿਹਾ ਅਤੇ ਇਹ ਇਕ ਐਸੀ ਤਕਨਾਲੋਜੀ ਹੈ ਜੋ ਕਾਇਮ ਰਹੇਗੀ। ਇਸ ਲਈ ਤਕਨਾਲੋਜੀ ਸਿੱਖਣ ਵਿੱਚ ਸਮਾਂ ਨਿਵੇਸ਼ ਕਰਨਾ ਸਮਝਦਾਰ ਸੀ।
- ਹੈਕਾਥਾਨ ਵਿੱਚ ਸ਼ਾਨਦਾਰ ਇਨਾਮ ਸਨ, $20,000 ਤੋਂ $100,000 NEAR ਵਿੱਚ ਜੇ ਤੁਸੀਂ ਜਿੱਤੋਂਗੇ।
- ਹੈਕਾਥਾਨ ਦੀ ਨਿਰਧਾਰਤ ਅਖੀਰ ਦੀ ਮਿਆਦ ਸੀ, ਜਿਸਦਾ ਅਰਥ ਇਹ ਸੀ ਕਿ ਪ੍ਰੋਜੈਕਟ ਮਹੀਨਿਆਂ ਤਕ ਟਲ ਨਹੀਂ ਸਕਦਾ ਸੀ ਜਿਵੇਂ ਬਹੁਤ ਸਾਰੇ ਸਾਈਡ ਪ੍ਰੋਜੈਕਟ ਆਮ ਤੌਰ ‘ਤੇ ਹੋਦੇ ਹਨ।
- ਪ੍ਰੋਜੈਕਟ ਇੱਕ ਵਧੀਆ ਸਿੱਖਣ ਦਾ ਅਨੁਭਵ ਹੋਵੇਗਾ ਅਤੇ ਹੈਕਾਥਾਨਾਂ ਲਈ ਇੱਕ ਸ਼ਾਨਦਾਰ ਜਾਣ-ਪਛਾਣ ਹੋਵੇਗੀ।
- ਸਭ ਤੋਂ ਖ਼ਰਾਬ ਹਾਲਤ ਵਿੱਚ ਵੀ, ਹੈਕਾਥਾਨ ਮੈਨੂੰ ਮੇਰੇ ਰੈਜ਼ਿਊਮੇ ‘ਤੇ ਦਰਸਾਉਣ ਲਈ ਇੱਕ ਵਧੀਆ ਪ੍ਰੋਜੈਕਟ ਬਣਾਉਣ ਦੀ ਆਜਾਦੀ ਦਿੰਦਾ।
ਇਨ੍ਹਾਂ ਸਭ ਗੱਲਾਂ ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹੋਏ, ਮੈਂ 26 ਅਗਸਤ, 2022 ਨੂੰ ਆਪਣੀ ਕਾਲੇਜ ਦੀ ਇੱਕ ਨੇੜੀ ਦੀ ਦੋਸਤ ਨੂੰ ਫੋਨ ਕੀਤਾ ਅਤੇ ਅਸੀਂ ਇਸ ਹੈਕਾਥਾਨ ਦੀ ਯੋਜਨਾ ਬਣਾਉਣੀ ਸ਼ੁਰੂ ਕੀਤੀ। ਹੈਕਾਥਾਨ 23 ਸਤੰਬਰ, 2023 ਨੂੰ ਸ਼ੁਰੂ ਹੋ ਕੇ 21 ਨਵੰਬਰ, 2022 ਨੂੰ ਖਤਮ ਹੋਣ ਲਈ ਨਿਰਧਾਰਤ ਕੀਤਾ ਗਿਆ ਸੀ। ਹਾਲਾਂਕਿ ਅਖੀਰ ਵਿੱਚ ਹੈਕਾਥਾਨ ਦੀ ਮਿਆਦ 24 ਨਵੰਬਰ, 2023 ਤੱਕ ਵਧਾ ਦਿੱਤੀ ਗਈ ਸੀ। ਜਦੋਂ ਅਸੀਂ 1 ਮਹੀਨਾ ਪਹਿਲਾਂ ਸੀ, ਅਸੀਂ ਇਹ ਸਮਾਂ ਸਿੱਖਣ ਅਤੇ ਮਸਤਿਸ਼ਕ ਝਟਕੇ ਲੈਣ ਲਈ ਵਰਤਣ ਦਾ ਫੈਸਲਾ ਕੀਤਾ ਕਿ ਅਸੀਂ ਇਸ 2 ਮਹੀਨੇ ਦੇ ਹੈਕਾਥਾਨ ਲਈ ਕੀ ਬਣਾਵਾਂਗੇ। ਉਸ ਪਹਿਲੇ ਮਹੀਨੇ ਦੌਰਾਨ, ਅਸੀਂ ਕਰਿਪਟੋ ਅਤੇ ਬਲੌਕਚੇਨਜ਼ ਦੀ ਇੱਕ ਸਧਾਰਨ ਝਲਕ ਪ੍ਰਾਪਤ ਕੀਤੀ। ਅਸੀਂ NEAR ਦੇ ਟੈਸਟਨੈੱਟ ‘ਤੇ ਅਭਿਆਸ ਕੀਤਾ, NEAR SDK ਦੀ ਸਮੀਖਿਆ ਕੀਤੀ, ਅਤੇ ਕੁਝ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ ਨੂੰ ਡਿਪਲੋਏ ਕੀਤਾ।
ਵਿਚਾਰ
ਬਲੌਕਚੇਨ ਅਤੇ NEAR ਬਾਰੇ ਇੱਕ ਵਧੀਆ ਪਰਚਿਆ ਹੋਣ ਤੋਂ ਬਾਅਦ, ਅਸੀਂ ਵਿਚਾਰ ਮਸਤਿਸ਼ਕ ਸ਼ੁਰੂ ਕੀਤੇ। ਮੈਂ ਚਾਹੁੰਦਾ ਸੀ ਕਿ ਇਹ ਪ੍ਰੋਜੈਕਟ ਸਿਰਫ਼ ਇੱਕ “ਹੈਕਾਥਾਨ ਪ੍ਰੋਜੈਕਟ” ਨਾ ਰਹੇ, ਬਲਕਿ ਕੁਝ ਐਸਾ ਹੋਵੇ ਜੋ ਇੱਕ ਉਤਪਾਦ ਬਣ ਸਕੇ ਜਿਸਨੂੰ ਹੋਰ ਲੋਕ ਵਰਤ ਸਕਣ ਅਤੇ ਇਹ ਦਰਸਾ ਸਕੇ ਕਿ ਕਰਿਪਟੋ ਸਿਰਫ਼ ਟਰੇਡਿੰਗ ਤੋਂ ਇਲਾਵਾ ਹੋਰ ਚੀਜ਼ਾਂ ਲਈ ਵੀ ਉਪਯੋਗੀ ਹੋ ਸਕਦੀ ਹੈ।
ਇਸ ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹੋਏ, ਅਸੀਂ ਸ਼ੁਰੂ ਵਿੱਚ ਕੁਝ ਈਕਵੇਲੈਂਟ ਬਣਾਉਣ ਦਾ ਫੈਸਲਾ ਕੀਤਾ ਜੋ Unreal Engine Blueprint ਵਰਗਾ ਹੋਵੇ, ਪਰ NEAR ਬਲੌਕਚੇਨ ‘ਤੇ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ ਨੂੰ ਠੀਕ-ਠਾਠ ਬਿਨਾਂ ਕੋਡਿੰਗ ਦੇ ਆਸਾਨ ਤਰੀਕੇ ਨਾਲ ਬਣਾਉਣ ਅਤੇ ਡਿਪਲੋਏ ਕਰਨ ਲਈ। ਹਾਲਾਂਕਿ ਹੈਕਾਥਾਨ ਸ਼ੁਰੂ ਹੋਣ ਤੋਂ ਇੱਕ ਹਫਤਾ ਪਹਿਲਾਂ, ਅਸੀਂ ਇਸ ਵਿਚਾਰ ਨੂੰ ਛੱਡ ਦਿੱਤਾ ਕਿਉਂਕਿ ਇਹ ਸਧਾਰਨ ਤੌਰ ‘ਤੇ ਸਮਝ ਨਹੀਂ ਆਇਆ। ਆਖਿ, ਕੋਈ ਕਿਸੇ ਟੂਲ ਨੂੰ ਕਿਉਂ ਵਰਤੇਗਾ NEAR ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟ ਬਣਾਉਣ ਲਈ ਜਦੋਂ ਉਨ੍ਹਾਂ ਲਈ ਕੋਈ ਪ੍ਰਯੋਗਿਕ ਭੂਮਿਕਾ ਮੌਜੂਦ ਨਹੀਂ ਸੀ? ਇਹ ਉਸੇ ਤਰ੍ਹਾਂ ਹੋਵੇਗਾ ਜਿਵੇਂ ਕੋਈ ਟੂਲ ਡਿਵੈਲਪ ਕਰਨਾ ਜਿਸਦੀ ਬਹੁਤ ਘੱਟ ਲੋਕਾਂ ਨੂੰ ਲੋੜ ਹੋਵੇ।
ਹੈਕਾਥਾਨ ਸ਼ੁਰੂ ਹੋਣ ਤੋਂ ਕੇਵਲ ਇੱਕ ਹਫਤਾ ਪਹਿਲਾਂ, ਅਸੀਂ ਦੁਬਾਰਾ ਵਿਚਾਰ ਵਿਮਰਸ਼ ਸ਼ੁਰੂ ਕੀਤਾ ਅਤੇ ਇਸ ਵਿਚਾਰ ‘ਤੇ ਆਖਿਰਕਾਰ ਰੁਕੇ:
A decentralized platform where AI researchers can outsource
data labeling to labelers around the world
ਅਸੀਂ ਪ੍ਰੋਜੈਕਟ ਦਾ ਨਾਮ “Labeler NearBy” ਰੱਖਿਆ। ਇਸ ਵਿਚਾਰ ਨੂੰ ਚੁਣਨ ਦਾ ਫੈਸਲਾ ਹੇਠ ਲਿਖੇ ਕਾਰਨਾਂ ‘ਤੇ ਆਧਾਰਿਤ ਸੀ:
- AI ਵਿਕਾਸ ਲਈ ਟ੍ਰੇਨਿੰਗ ਲਈ ਡੇਟਾ ਦੀ ਮਨੁੱਖੀ ਲੇਬਲਿੰਗ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ।
- ਖਾਸ ਡੇਟਾਸੈਟਸ ਲਈ ਕੁਸ਼ਲ ਵਿਅਕਤੀਆਂ ਨੂੰ ਲੱਭਣਾ ਅਤੇ ਪ੍ਰਬੰਧਿਤ ਕਰਨਾ ਚੁਣੌਤੀਪੂਰਨ ਹੁੰਦਾ ਹੈ।
- ਇਹ ਵਿਚਾਰ ਪਹਿਲਾਂ ਇੱਕ ਕੰਪਨੀ ਫ਼ਲ੍ਹ ਸਕੇਲ ਏਆਈ (Scale AI) ਵੱਲੋਂ ਸਫਲਤਾਪੂਰਵਕ ਲਾਗੂ ਕੀਤਾ ਗਿਆ ਹੈ, ਜਿਸ ਤੋਂ ਉਨ੍ਹਾਂ ਨੇ ਪ੍ਰੋਡਕਟ-ਮਾਰਕੀਟ ਫਿਟ ਲੱਭਿਆ।
- ਕੇਂਦਰੀਕ੍ਰਤ ਸੇਵਾਵਾਂ, ਜਿਵੇਂ Scale AI, ਵਿੱਚ ਇਹ ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਸੰਸਥਾਵਾਂ ਨੂੰ ਆਪਣਾ ਡੇਟਾ ਲੇਬਲਿੰਗ ਕੰਪਨੀ ਨੂੰ ਭੇਜਣਾ ਪਏ, ਜੋ ਫਿਰ ਵਿਸ਼ਵ ਭਰ ਵਿੱਚ ਮਨੁੱਖੀ ਲੇਬਲਰਾਂ ਨੂੰ ਆਉਟਸੋਰਸ ਕਰਦੀ ਹੈ। ਲੇਬਲਿੰਗ ਪ੍ਰਕਿਰਿਆ ਦੇ ਬਾਅਦ, ਕੰਪਨੀ ਲੇਬਲ ਕੀਤਿਆ ਡੇਟਾ ਸੰਸਥਾ ਨੂੰ ਵਾਪਸ ਕਰਦੀ ਹੈ। ਇਸ ਨਾਲ ਕੀਮਤੀ ਟ੍ਰੇਨਿੰਗ ਡੇਟਾ ‘ਤੇ ਕੰਟਰੋਲ ਛੱਡ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ, ਜਿਸਦਾ ਉਪਯੋਗ ਲੇਬਲਿੰਗ ਕੰਪਨੀ ਆਪਣੇ ਮਾਡਲ ਤਿਆਰ ਕਰਨ ਲਈ ਕਰ ਸਕਦੀ ਹੈ। ਇਸ ਸੇਵਾ ਨੂੰ ਡੈਸੈਂਟਰਲਾਈਜ਼ ਕਰਨਾ ਲਾਜ਼ਮੀ ਹੱਲ ਵਾਂਗ ਲੱਗਿਆ।
- ਅਸੀਂ ਡੈਸੈਂਟਰਲਾਈਜ਼ਡ ਐਪ (dApp) ਖੇਤਰ ਵਿੱਚ ਇਸ ਵਿਚਾਰ ‘ਤੇ ਕੰਮ ਕਰ ਰਹੇ ਬਹੁਤ ਘੱਟ ਪ੍ਰੋਜੈਕਟ ਮਿਲੇ, ਜਿਸ ਨੇ ਸਾਨੂੰ ਨਵੀਨਤਾ ਅਤੇ ਅਗਵਾਈ ਕਰਨ ਦਾ ਮੌਕਾ ਦਿੱਤਾ।
ਜਟਿਲਤਾ ਨੂੰ ਘਟਾਉਣ ਲਈ, ਅਸੀਂ ਨਿਰਣਯ ਕੀਤਾ ਕਿ Labeler NearBy ਅਜੇ ਲਈ ਕੇਵਲ ਇਮੇਜ਼ ਡੇਟਾ ਨੂੰ ਸਮਰਥਨ ਦੇਵੇਗਾ।
ਜਮ੍ਹਾ ਕਰਵਾਉਣਾ
ਵਿਚਾਰ ਚੁਣਨ ਅਤੇ ਹੈਕਾਥਾਨ ਦੇ ਅਧਿਕਾਰਕ ਤੌਰ ‘ਤੇ ਸ਼ੁਰੂ ਹੋਣ ਨਾਲ, ਮੇਰੇ ਅਤੇ ਮੇਰੇ ਦੋਸਤ ਨੇ Labeler NearBy ਬਣਾਉਣਾ ਸ਼ੁਰੂ ਕੀਤਾ। ਅਸੀਂ ਆਪਣੇ ਪ੍ਰੋਜੈਕਟ ‘ਤੇ 2 ਮਹੀਨੇ ਕੰਮ ਕੀਤਾ ਜਦ ਤਕ ਅਸੀਂ 24 ਨਵੰਬਰ, 2022 ਨੂੰ Devpost ‘ਤੇ ਆਪਣੀ ਪ੍ਰੋਜੈਕਟ ਦੀ ਅਖੀਰੀ ਢਾਂਚਾ ਜਮ੍ਹਾ ਨਹੀਂ ਕਰਵਾ ਦਿੱਤਾ। ਅਸੀਂ ਆਪਣਾ ਪ੍ਰੋਜੈਕਟ Devpost ‘ਤੇ ਜਮ੍ਹਾ ਕੀਤਾ ਅਤੇ ਆਪਣੀ ਜਮ੍ਹਾਦਾਰੀ ਦੀ ਇੱਕ ਨਕਲ GitHub ‘ਤੇ ਵੀ ਬਣਾਈ। ਇਹ ਬਲੌਗ Labeler NearBy ਦੇ ਹਰ ਤਕਨੀਕੀ ਪਹਲੂ ਅਤੇ ਵਿਕਾਸ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਕਵਰ ਨਹੀਂ ਕਰਦਾ। ਇਸ ਨੂੰ ਜਾਣਦੇ ਹੋਏ, ਜੇ ਤੁਸੀਂ ਜਾਣਨਾ ਚਾਹੁੰਦੇ ਹੋ ਕਿ Labeler NearBy ਕਿਵੇਂ ਕੰਮ ਕਰਦਾ ਹੈ ਜਾਂ ਸਾਡੀ ਅਖੀਰੀ ਜਮ੍ਹਾਦਾਰੀ ਵੇਖਣਾ ਚਾਹੁੰਦੇ ਹੋ, ਤਾਂ مهربਾਨੀ ਕਰਕੇ ਹੇਠ ਲਿਖੀਆਂ ਲਿੰਕਾਂ ਵਿੱਚੋਂ ਇੱਕ ‘ਤੇ ਜਾਓ:
Labeler NearBy ਦੋ ਕੋਡਬੇਸਾਂ ਤੋਂ ਬਣਦਾ ਹੈ: ln-researcher ਅਤੇ ln-labeler। ਇਹ ਕੋਡਬੇਸ ਪੂਰੀ ਤਰ੍ਹਾਂ MIT ਲਾਇਸੰਸ ਤਹਿਤ ਓਪਨ ਸੋਰਸ ਹਨ ਅਤੇ ਹੇਠ ਲਿਖੀਆਂ ਲਿੰਕਾਂ ਰਾਹੀਂ ਵੇਖੇ ਜਾ ਸਕਦੇ ਹਨ:
ਇੱਥੇ ਇੱਕ ਸਧਾਰਨ ਝਲਕ ਦਿੱਤੀ ਗਈ ਹੈ ਕਿ Labeler NearBy (LN) ਕਿਵੇਂ ਕੰਮ ਕਰੇਗਾ:
ਇੱਕ ਰਿਸਰਚਰ ਨੂੰ ਆਪਣੇ AI ਮਾਡਲ ਦੀ ਟ੍ਰੇਨਿੰਗ ਲਈ ਲੇਬਲ ਕੀਤੀਆਂ ਇਮੇਜਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਇਸ ਨੂੰ ਹਾਸਲ ਕਰਨ ਲਈ, ਰਿਸਰਚਰ LN ਦੀ ਵਰਤੋਂ ਕਰਦਾ ਹੈ ਤਾਂ ਜੋ ਉਹ ਆਪਣਾ ਡੇਟਾ ਹੋਸਟ ਕਰ ਸਕੇ ਅਤੇ ਲੇਬਲਰਾਂ ਨੂੰ ਆਪਣਾ ਡੇਟਾ ਲੇਬਲ ਕਰਨ ਦਾ ਇਕ ਢੰਗ ਪ੍ਰਦਾਨ ਕਰ ਸਕੇ। ਇਹ ln-researcher ਰਾਹੀਂ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਜੋ ਇੱਕ ਸੈਲਫ-ਹੋਸਟ ਕੀਤੀ ਵੈੱਬ ਸੇਵਾ ਹੈ ਜਿਸ ਵਿੱਚ ਇੱਕ API, ਰਿਸਰਚਰ ਦੇ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ, ਅਤੇ ਇੱਕ ਲੋਕਲ Postgres ਡੇਟਾਬੇਸ ਸ਼ਾਮਲ ਹਨ। ਲੇਬਲਰ ਲਈ, ਇੱਕ ਵੈੱਬ ਫਰੰਟਐਂਡ (ਜੋ ਪ੍ਰਦਾਨ ਕੀਤਾ ਗਿਆ ਹੋਵੇਗਾ) ਉਪਲਬਧ ਕਰਵਾਇਆ ਜਾਂਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਉਹ ਰਿਸਰਚਰ ਦੀਆਂ ਇਮੇਜਾਂ ਤੱਕ ਪਹੁੰਚ ਕਰਕੇ ਉਨ੍ਹਾਂ ਨੂੰ ਲੇਬਲ ਕਰ ਸਕਦੇ ਹਨ। ਲੇਬਲ ਹੋਣ ਦੀ ਪ੍ਰਕਿਰਿਆ ਦੌਰਾਨ, ਇੱਕ ਇਮੇਜ ਨੂੰ ਵੱਖ-ਵੱਖ ਲੇਬਲਰਾਂ ਦੁਆਰਾ ਤਿੰਨ ਵਾਰੀ ਲੇਬਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਸਿਰਫ਼ ਉਹੀ ਲੇਬਲਰ ਜਿਸਦੇ ਲੇਬਲ ਸਭ ਤੋਂ ਵਧੀਆ ਮੰਨੇ ਜਾਂਦੇ ਹਨ (ਇਕ ਵੋਟਿੰਗ ਪ੍ਰਣਾਲੀ ਰਾਹੀਂ ਨਿਰਧਾਰਿਤ), NEAR ਸਕੇਅਰ ਨਾਲ ਇਨਾਮਿਤ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਇਸ ਪ੍ਰਕਿਰਿਆ ਲਈ ਜਿੰਮੇਵਾਰ ਵੈੱਬ ਐਪ ਨੂੰ ln-labeler ਕਿਹਾ ਗਿਆ। ਰਿਸਰਚਰ ਹਰ ਲੇਬਲਿੰਗ ਓਪਰੇਸ਼ਨ ਦਾ ਫੰਡ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ, ਅਤੇ NEAR ਸਕੇਅਰ ਨੂੰ Coinbase ਰਾਹੀਂ ਡਾਲਰਾਂ ਵਿੱਚ ਆਸਾਨੀ ਨਾਲ ਬਦਲਿਆ ਜਾ ਸਕਦਾ ਹੈ। ਸਾਰੇ ਲੈਣਦੇਣ ਲਾਜਿਸਟਿਕਸ NEAR ਪ੍ਰੋਟੋਕੋਲ ਬਲੌਕਚੇਨ ‘ਤੇ ਹੋਸਟ ਕੀਤੇ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ ਦੁਆਰਾ ਸੰਭਾਲੇ ਜਾਂਦੇ ਹਨ।
ਤੁਸੀਂ ਹੈਕਾਥਾਨ ਲਈ Labeler NearBy ਦਾ ਡੈਮੋ ਵੀਡੀਓ ਇੱਥੇ ਦੇਖ ਸਕਦੇ ਹੋ:
ਸਭ ਤੋਂ ਵੱਡੀ ਉਪਲਬਧੀ
ਜਿਸ ਫੀਚਰ ‘ਤੇ ਮੈਨੂੰ ਸਭ ਤੋਂ ਜ਼ਿਆਦਾ ਗਰਵ ਹੈ ਉਹ ਇੱਕ ਫੰਕਸ਼ਨ ਹੈ ਜਿਸਦਾ ਨਾਮ getImage() ਹੈ। ਇਹ ਫੰਕਸ਼ਨ ln-researcher ਵਿੱਚ ਇੱਕ API ਐਂਡਪੌਇੰਟ ਵਜੋਂ ਕੰਮ ਕਰਦਾ ਹੈ ਅਤੇ Labeler NearBy (LN) ਵਿੱਚ ਰਿਸਰਚਰਾਂ ਅਤੇ ਲੇਬਲਰਾਂ ਦਰਮਿਆਨ ਡੇਟਾ ਪਾਈਪਲਾਈਨ ਵਿੱਚ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਭੂਮਿਕਾ ਨਿਭਾਉਂਦਾ ਹੈ।
ਇਹ API ਐਂਡਪੌਇੰਟ ਰਿਸਰਚਰਾਂ ਨੂੰ ਸੁਰੱਖਿਅਤ ਅਤੇ ਭਰੋਸੇਯੋਗ ਤਰੀਕੇ ਨਾਲ ਆਪਣੀਆਂ ਇਮੇਜਾਂ ਲੇਬਲਿੰਗ ਲਈ ਵੰਡਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦਾ ਹੈ। ਲੇਬਲਿੰਗ ਅਸਾਈਨਮੈਂਟ NEAR ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟਸ ਰਾਹੀਂ NEAR ਪ੍ਰੋਟੋਕੋਲ ਬਲੌਕਚੇਨ ‘ਤੇ ਪ੍ਰਬੰਧਿਤ ਕੀਤੇ ਜਾਂਦੇ ਹਨ, ਜਦਕਿ ਇਮੇਜ ਡੇਟਾ ਰਿਸਰਚਰ ਦੁਆਰਾ ln-researcher ਰਾਹੀਂ ਹੋਸਟ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਇਹ ਐਂਡਪੌਇੰਟ ਸੁਰੱਖਿਆ ਜਾਂਚਾਂ ਦੀ ਇੱਕ ਲੜੀ ਚਲਾਉਂਦਾ ਹੈ ਤਾਂ ਜੋ ਸਿਰਫ਼ ਅਸਾਈਨ ਕੀਤਾ ਗਿਆ ਲੇਬਲਰ ਹੀ ਇਮੇਜ ਤੱਕ ਪਹੁੰਚ ਹਾਸਲ ਕਰ ਸਕੇ। ਇਸ ਵਿੱਚ ਰਿਕਵੇਸਟ ਦੇ ਸਿਗਨੇਚਰ ਦੀ ਪੁਸ਼ਟੀ ਕਰਨ ਅਤੇ ਸਬੰਧਤ ਸਮਾਰਟ ਕਾਂਟ੍ਰੈਕਟ ਦੀ ਜਾਂਚ ਕਰਨ ਸ਼ਾਮਲ ਹੈ ਤਾਂ ਜੋ ਟਾਸਕ ਦੀ ਮੌਜੂਦਗੀ ਅਤੇ ਉਸਦੀ ਅਸਾਈਨਮੈਂਟ ਬੇਨਤ ਕਰਨ ਵਾਲੇ ਲੇਬਲਰ ਨੂੰ ਪ੍ਰਮਾਣਿਤ ਕੀਤਾ ਜਾ ਸਕੇ।
ਜਦੋਂ ਰਿਕਵੇਸਟ ਰਿਸਰਚਰ ਦੀ ਸੈਲਫ-ਹੋਸਟ ਕੀਤੀ ln-researcher API ਵਿੱਚ ਪ੍ਰਮਾਣਿਤ ਹੋ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਇਹ ਫੰਕਸ਼ਨ ਲੋਕਲ Postgres ਡੇਟਾਬੇਸ ਤੋਂ ਇਮੇਜ ਪ੍ਰਾਪਤ ਕਰਦਾ ਹੈ, ਇਮੇਜ ਨੂੰ ਐਨਕ੍ਰਿਪਟ ਕਰਦਾ ਹੈ, ਅਤੇ ਅਧਿਕਾਰਤ ਲੇਬਲਰ ਨੂੰ ਸੌਂਪ ਦਿੰਦਾ ਹੈ ਜੋ ਫਿਰ ਵਾਪਸ ਇਮੇਜ ਨੂੰ ਡੀਕ੍ਰਿਪਟ ਕਰ ਕੇ ਲੇਬਲ ਕਰ ਸਕਦਾ ਹੈ। ਇਕੱਠੇ, ਇਹ ਫੰਕਸ਼ਨ ਡੇਟਾਬੇਸ ਵਿੱਚ ਇਮੇਜ ਦੀ ਹਾਲਤ ਨੂੰ ਅਪਡੇਟ ਕਰਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਇਮੇਜ ਲੇਬਲ ਹੋਣ ਦੀ ਪ੍ਰਗਟਿਰਾ ਦਰਸਾਈ ਜਾਂਦੀ ਹੈ। ਇਸ ਪ੍ਰਕਿਰਿਆ ਦੌਰਾਨ, ਰਿਸਰਚਰ ਅਤੇ ਲੇਬਲਰ ਦੋਹਾਂ ਦੇ RSA ਕੁੰਜੀਆਂ ਅਥਾਰਟੀਕੇਸ਼ਨ ਲਈ ਵਰਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ। ਇਮੇਜ ਨੂੰ ਐਨਕ੍ਰਿਪਟ ਕਰਨ ਲਈ AES ਐਨਕ੍ਰਿਪਸ਼ਨ ਵਰਤੀ ਜਾਂਦੀ ਹੈ।
ਇਹ ਐਂਡਪੌਇੰਟ ਰਿਸਰਚਰਾਂ ਤੋਂ ਲੇਬਲਰਾਂ ਵੱਲ ਇਮੇਜਾਂ ਦੀ ਸੁਰੱਖਿਅਤ ਅਤੇ ਨਿਯੰਤ੍ਰਿਤ ਵੰਡ ਪ੍ਰਬੰਧਿਤ ਕਰਨ ਵਿੱਚ ਇਕ ਅਹੰਕਾਰਪੂਰਨ ਭੂਮਿਕਾ ਨਿਭਾਉਂਦਾ ਹੈ। ਇਹ ਸੁਰੱਖਿਅਤ ਡੇਟਾ ਟ੍ਰਾਂਸਫਰ ਨੂੰ ਯਕੀਨੀ ਬਣਾਉਂਦਾ ਹੈ ਅਤੇ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਇਮੇਜ ਲੇਬਲਿੰਗ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਟ੍ਰੈਕ ਅਤੇ ਪ੍ਰਬੰਧਿਤ ਕਰਦਾ ਹੈ। ਇਲਾਵਾ, ਇਸ ਪ੍ਰਕਿਰਿਆ ਨਾਲ ਘੱਟੋ-ਘੱਟ ਇਸ ਐਂਡਪੌਇੰਟ ਲਈ HTTPS ਦੀ ਲੋੜ ਖਤਮ ਹੋ ਸਕਦੀ ਹੈ।
ਇਹ ਨਿਰਧਾਰਿਤ ਐਂਡਪੌਇੰਟ/ਫੰਕਸ਼ਨ ਟੈਸਟ ਕੀਤਾ ਗਿਆ ਅਤੇ ਕਾਰਗਰ ਸਾਬਤ ਹੋਇਆ। ਹੇਠਾਂ Labeler NearBy ਦੀ ਕੁੱਲ ਕਾਰਗਰਤਾ ਦੀ ਇੱਕ ਚਿੱਤਰਕਲਾ ਦਿੱਤੀ ਗਈ ਹੈ, ਜਿਸ ਵਿੱਚ ਉਪਰੋਕਤ ਐਂਡਪੌਇੰਟ/ਫੰਕਸ਼ਨ ਕਿਵੇਂ ਕੰਮ ਕਰਦਾ ਹੈ ਉਸ ਦੀ ਸਪଷਟ ਚਿੱਤਰਣ ਹੈ:
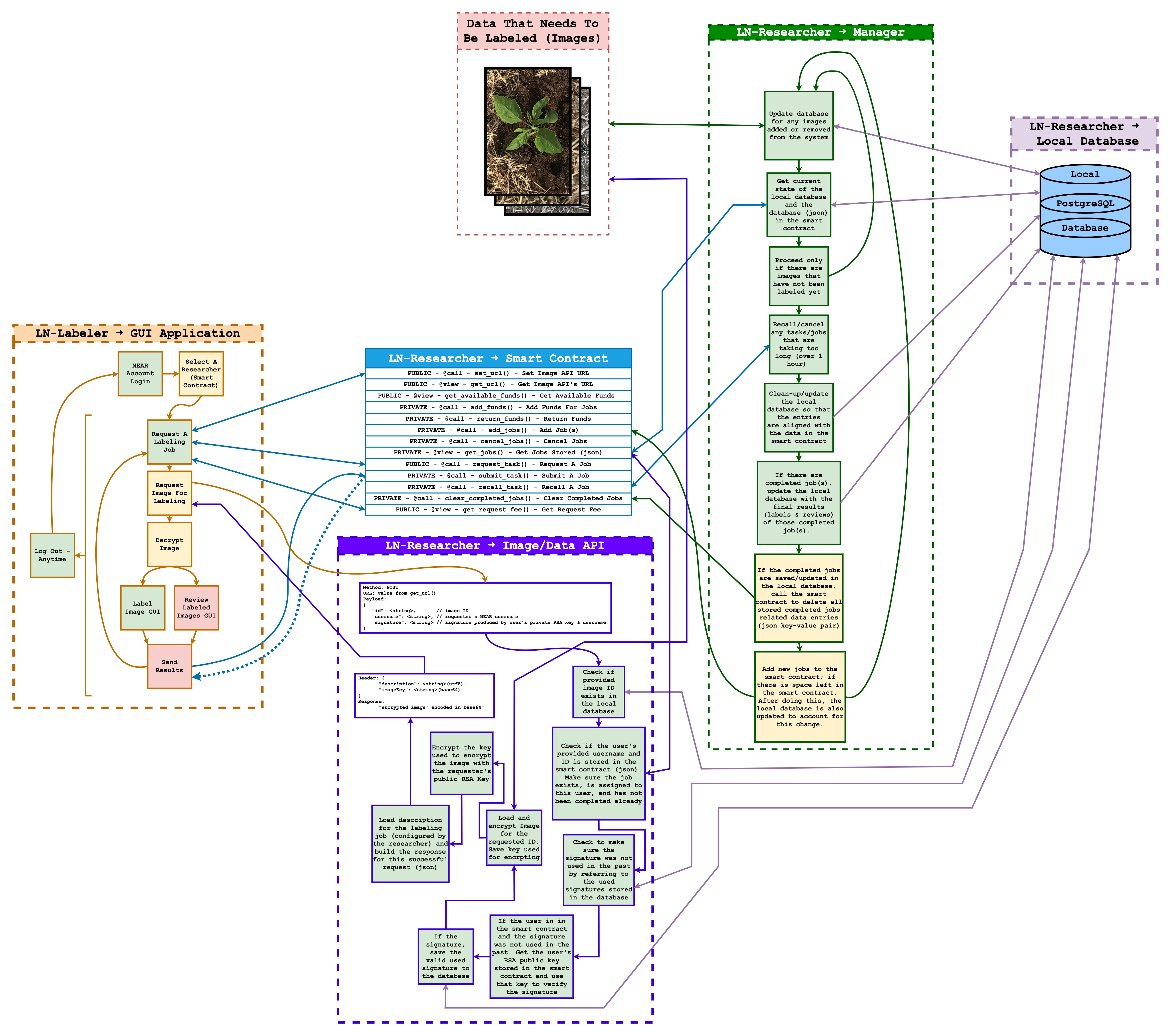
ਨਤੀਜਾ
ਬਦਕਿਸਮਤੀ ਨਾਲ, ਦਰਦਨਾਕ ਹਕੀਕਤ ਇਹ ਹੈ ਕਿ ਅਸੀਂ ਹੈਕਥਾਨ ਦੀ ਮਿਆਦ ਤੱਕ ਇਸ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਪੂਰੀ ਤਰ੍ਹਾਂ ਮੁਕੰਮਲ ਨਹੀਂ ਕਰ ਸਕੇ। ਪ੍ਰੋਜੈਕਟ ਦਾ ਜ਼ਿਆਦਾਤਰ ਹਿੱਸਾ ਤਿਆਰ ਹੋ ਗਿਆ ਸੀ, ਜਿਵੇਂ ਕਿ ln-researcher, ਪਰ ਫਰੰਟਐਂਡ (ln-labeler) ਮੁਕੰਮਲ ਨਹੀਂ ਹੋ ਸਕਿਆ ਅਤੇ ਅਸੀਂ ਲਾਈਵ ਡੈਮੋ ਤਾਈਨਾਤ ਨਹੀਂ ਕਰ ਸਕੇ। ਹਾਲਾਂਕਿ ਬੈਕਐਂਡ (ln-researcher) ਮੁਢਲੀ ਤੌਰ ‘ਤੇ ਮੁਕੰਮਲ ਸੀ, ਪਰ ਕੋਈ ਢੰਗ ਨਾਲ ਕੰਮ ਕਰਦਾ ਫਰੰਟਐਂਡ ਅਤੇ ਕੋਈ ਲਾਈਵ ਡੈਮੋ ਨਾ ਹੋਣ ਕਰਕੇ ਕਿਸੇ ਵੀ ਵਿਅਕਤੀ ਲਈ Labeler NearBy ਦਾ ਖਿਆਲ ਆਜ਼ਮਾਣਾ ਸੰਭਵ ਨਹੀਂ ਸੀ। ਨਾਂ ਸਿਰਫ ਇਹੀ, ਪਰ ਜੱਜਾਂ ਵੀ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਆਜ਼ਮਾ ਨਹੀਂ ਸਕੇ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਜਮ੍ਹਾਂ ਕੀਤੀ ਗਈ ਸਬਮਿਸ਼ਨ ਪੜ੍ਹਨੀ ਪਈ, ਕੋਡ ਦੇਖਣਾ ਪਿਆ, ਅਤੇ/ਜਾਂ ਆਪਣੇ ਆਪ ਹੀ ਇਸਨੂੰ ਚਲਾਉਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਨੀ ਪਈ। ਜਿਸ ਨਾਲ ਸਾਡੇ ਜਿੱਤਣ ਦੇ ਮੌਕੇ ਬੁਨਿਆਦੀ ਤੌਰ ‘ਤੇ ਸਿਫ਼ਰ ਪ੍ਰਤੀਸ਼ਤ ਹੋ ਗਏ। ਇਹ ਗੱਲ 15 ਦਸੰਬਰ, 2022 ਨੂੰ ਪੁਸ਼ਟੀ ਹੋਈ ਜਦੋਂ ਹੈਕਥਾਨ ਦੇ ਵਿਜੇਤਾ ਐਲਾਨ ਕੀਤੇ ਗਏ, ਅਤੇ ਅਸੀਂ ਉਹਨਾਂ ਵਿੱਚੋਂ ਨਹੀਂ ਸੀ।
ਹਾਰ
ਮੈਂ ਇਹ ਗੱਲ ਛੁਪਾਉਂਦਾ ਨਹੀਂ ਕਿ ਇਸ ਹੈਕਥਾਨ ਦਾ ਆਖਰੀ ਨਤੀਜਾ ਨਿਰਾਸ਼ਜਨਕ ਸੀ। ਇਸ ਪ੍ਰੋਜੈਕਟ ਵਿੱਚ ਮਹੀਨੇ ਲਗਾਏ ਗਏ ਅਤੇ ਮੇਰੇ ਕੋਲ ਇਸ ਪ੍ਰੋਜੈਕਟ ਲਈ ਇਕ ਵੱਡੀ ਦ੍ਰਿਸ਼ਟੀ ਸੀ ਕਿਉਂਕਿ ਮੈਂ ਸੋਚਦਾ ਸੀ ਕਿ ਇਹ ਖੋਜਕਾਰਾਂ ਲਈ ਇਕ ਬਹੁਤ ਹੀ ਉਪਯੋਗੀ ਟੂਲ ਦੇਵੇਗਾ।
ਮੇਰੇ ਵੱਲੋਂ ਕੀਤਾ ਜਾਣ ਵਾਲੇ ਪ੍ਰੋਜੈਕਟਾਂ ਲਈ ਇੱਕ ਸਪਸ਼ਟ ਮਿਆਰ ਹੈ: ਜਾਂ ਤਾਂ ਉਹ ਸਫਲ ਹੁੰਦੇ ਹਨ ਜਾਂ ਫੇਲ; ਦੋਹਾਂ ਵਿਚਕਾਰ ਕੋਈ ਮੱਧ ਰਸਤਾ ਨਹੀਂ। ਇਸ ਲਈ ਇਹ ਪ੍ਰੋਜੈਕਟ ਅਸਫਲ ਸੀ ਕਿਉਂਕਿ ਇਹ ਮਿਆਦ ਤੱਕ ਪੂਰੀ ਤਰ੍ਹਾਂ ਮੁਕੰਮਲ ਨਹੀਂ ਹੋਇਆ ਅਤੇ ਸੰਭਾਵੀ ਉਪਭੋਗਤਿਆਂ ਲਈ ਅਪਹੁੰਚ ਦਾ ਰਿਹਾ।
ਪਰ ਇਹ ਯਾਦ ਰੱਖਣਾ ਜਰੂਰੀ ਹੈ ਕਿ ਅਸਫਲਤਾ ਜੀਵਨ ਦਾ ਇੱਕ ਕੁਦਰਤੀ ਹਿੱਸਾ ਹੈ। ਸਾਡੀਆਂ ਸਫਲਤਾਵਾਂ ਉਹ ਪਾਠਾਂ ‘ਤੇ ਆਧਾਰਤ ਹੁੰਦੀਆਂ ਹਨ ਜੋ ਅਸੀਂ ਆਪਣੀਆਂ ਅਸਫਲਤਾਵਾਂ ਤੋਂ ਸਿੱਖਦੇ ਹਾਂ। ਜਦੋਂ ਕਿ ਇਸ ਹੈਕਥਾਨ ਦਾ ਨਤੀਜਾ ਨਿਰਾਸ਼ ਕਰਨ ਵਾਲਾ ਸੀ, ਫਿਰ ਵੀ ਇਸ ਨੇ ਪ੍ਰੋਜੈਕਟ/ਉਤਪਾਦ ਨੂੰ ਵਿਕਸਿਤ ਅਤੇ ਤਿਆਰ ਕਰਨ ਸੰਬੰਧੀ ਕੀਮਤੀ ਜਾਣਕਾਰੀਆਂ ਦਿੱਤੀਆਂ।
ਸਿੱਖਿਆਵਾਂ
ਇਸ ਅਨੁਭਵ ਤੋਂ ਮੈਂ ਜੋ ਮੁੱਖ ਸਿੱਖਿਆਵਾਂ ਪ੍ਰਾਪਤ ਕੀਤੀਆਂ ਉਹ ਹੇਠਾਂ ਹਨ:
- ਜਿਸ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਅਸੀਂ ਚੁਣਿਆ ਸੀ, ਉਸ ਲਈ ਘੱਟ ਤੋਂ ਘੱਟ ਪਹਿਲਾਂ ਹੀ ਬਹੁਤ ਸਾਰੀਆਂ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਬਣਾਉਣ ਦੀ ਲੋੜ ਸੀ ਤਾਂ ਜੋ ਅਸੀਂ ਉਸ ‘ਤੇ ਦੁਬਾਰਾ ਕੰਮ ਕਰ ਸਕੀਏ। ਮੈਂ ਇਸਨੂੰ ਕੀ ਅਰਥ ਦਿੰਦਾ ਹਾਂ? ਠੀਕ ਹੈ, ਇਸ ਪ੍ਰੋਜੈਕਟ ਲਈ ਬਹੁਤ ਜ਼ਿਆਦਾ ਹਿੱਸਿਆਂ ਨੂੰ ਉਸ ਵਿਚਾਰ ਦੇ ਤਹਿਤ ਪਹਿਲਾਂ ਹੀ ਤਿਆਰ ਕੀਤਾ ਜਾਣਾ ਲਾਜ਼ਮੀ ਸੀ ਇਸ ਤੋਂ ਪਹਿਲਾਂ ਕਿ ਅਸੀਂ ਉਸ ਵਿਚਾਰ ਦੀ ਜਾਂਚ ਵੀ ਕਰ ਸਕੀਏ। ਇਹ ਵਧੀਆ ਹੁੰਦਾ ਕਿ ਅਸੀਂ ਕੋਈ ਐਸਾ ਪ੍ਰੋਜੈਕਟ ਚੁਣਦੇ ਜਿਸਦੇ ਕੰਮ ਕਰਨ ਲਈ ਘੱਟ ਜ਼ਰੂਰੀ ਘਟਕ ਹੋਣ। ਇਸ ਤਰ੍ਹਾਂ, ਅਸੀਂ ਜ਼ਰੂਰੀ ਘਟਕਾਂ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਤਿਆਰ ਕਰ ਸਕਦੇ ਸਾਂ ਤੇ ਫਿਰ ਪ੍ਰੋਜੈਕਟ ‘ਤੇ ਜਲਦੀ ਤੋਂ ਜਲਦੀ ਇਟਰੈਟ ਕਰਦੇ। ਇੰਝ ਕਰਕੇ ਅਸੀਂ ਮਿਆਦ ਵਿੱਚ ਆਸਾਨੀ ਨਾਲ ਪਹੁੰਚ ਸਕਦੇ ਸਾਂ ਅਤੇ ਇੱਕ ਐਸਾ ਪ੍ਰੋਜੈਕਟ ਬਣਾ ਸਕਦੇ ਸਾਂ ਜੋ ਸ਼ਾਇਦ ਸਧਾਰਨ ਹੋਵੇ ਪਰ ਜ਼ਿਆਦਾ ਪੂਰਾ ਹੋਵੇ। YC, ਇੱਕ ਟੈਕ ਸਟਾਰਟਅਪ ਐਕਸੈਲੇਰੇਟਰ, ਜ਼ੋਰ ਦਿੰਦਾ ਹੈ ਕਿ ਤੁਹਾਨੂੰ ਤੁਰੰਤ ਲਾਂਚ ਕਰੋ, ਉਪਭੋਗਤਿਆਂ ਨਾਲ ਗੱਲ ਕਰੋ, ਅਤੇ ਦੁਹਰਾਓ। ਅਸੀਂ ਇਸ ਹੈਕਥਾਨ ਲਈ ਆਪਣੇ ਪ੍ਰੋਜੈਕਟ ਨਾਲ ਇਹ ਕਰਨਾ ਚਾਹੀਦਾ ਸੀ।
- ਅਸੀਂ ਘੱਟ ਅੰਦਾਜ਼ ਲਾਇਆ ਕਿ ਇਸ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਬਣਾਉਣ ਵਿੱਚ ਕਿੰਨਾ ਸਮਾਂ ਲੱਗੇਗਾ। ਇਹ ਸਾਡਾ ਪਹਿਲਾ ਹੈਕਥਾਨ ਸੀ ਅਤੇ ਸਾਡੀ ਪਹਿਲੀ ਵਾਰੀ ਸੀ ਜਦੋਂ ਅਸੀਂ ਇੱਕ decentralized application (dapp) ਬਣਾਈ। ਨਾ ਸਿਰਫ ਇਹ, ਮੈਂ ਪੂਰੇ ਸਮੇਂ ਇਕ ਸੌਫਟਵੇਅਰ ਇੰਜੀਨੀਅਰ ਵਜੋਂ ਕੰਮ ਕਰ ਰਿਹਾ ਸੀ ਅਤੇ ਮੇਰਾ ਦੋਸਤ ਆਪਣੀ Masters ਪੂਰੀ ਕਰ ਰਿਹਾ ਸੀ। ਫਿਰ ਵੀ ਅਸੀਂ ਸੋਚਿਆ ਕਿ 2 ਮਹੀਨੇ ਕਾਫ਼ੀ ਹੋਣਗੇ। ਇਸਦਾ ਵਧੀਆ ਹੋਇਆ ਹੁੰਦਾ ਕਿ ਅਸੀਂ ਪ੍ਰੋਜੈਕਟ ਦੇ ਦਾਇਰੇ ਨੂੰ ਘੱਟ ਕਰਦੇ ਅਤੇ/ਜਾਂ ਇੱਕ ਹੋਰ ਟੀਮ ਮੈਂਬਰ ਲੱਭਦੇ ਜੋ ਸਾਡਾ ਕੰਮ ਘਟਾ ਸਕਦਾ।
- Winston Churchill ਨੇ ਪ੍ਰਸਿੱਧ ਤੌਰ ‘ਤੇ ਕਿਹਾ ਸੀ: “ਪੂਰਨਤਾ ਤਰੱਕੀ ਦੀ ਦੁਸ਼ਮਣ ਹੈ”। ਮੈਂ ਇਸ ਪ੍ਰੋਜੈਕਟ ਨੂੰ ਇੱਕ business-to-customer (B2C) ਉਤਪਾਦ ਵਾਂਗ ਵਰਤ ਰਿਹਾ ਸੀ, ਜਦਕਿ ਅਸਲ ਵਿੱਚ ਇਹ ਸਿਰਫ ਇਕ ਹੈਕਥਾਨ ਪ੍ਰੋਜੈਕਟ ਸੀ ਅਤੇ ਵੱਧ ਤੋਂ ਵੱਧ ਇਕ minimum viable product (MVP) ਸੀ। ਇਸ ਲਈ ਸ਼ੁਰੂਆਤ ਵਿੱਚ, ਮੈਂ ਛੋਟੀਆਂ-ਛੋਟੀਆਂ ਵੇਰਵਿਆਂ ‘ਤੇ ਬਹੁਤਾ ਸਮਾਂ ਨੁੱਕਸਾਨ ਕੀਤਾ ਜਦ ਕਿ ਮੈਨੂੰ ਆਪਣੇ ਸਮੇਂ ਨੂੰ ਮੁੱਖ ਫੀਚਰਾਂ ਨੂੰ ਕਾਫ਼ੀ ਤਰ੍ਹਾਂ ਕੰਮ ਕਰਨ ‘ਤੇ ਧਿਆਨ ਦੇਣਾ ਚਾਹੀਦਾ ਸੀ।
ਇਨ੍ਹਾਂ ਕੀਮਤੀ ਸਿੱਖਿਆਵਾਂ ਦੇ ਇਲਾਵਾ, ਮੈਂ ਨਵੇਂ ਹੁਨਰ ਵੀ ਹਾਸਲ ਕੀਤੇ ਹਨ ਜੋ ਮੇਰੇ ਨਿੱਜੀ ਪਾਸੇ ਦੇ ਪ੍ਰੋਜੈਕਟਾਂ ਅਤੇ ਪੇਸ਼ੇਵਰ ਕੋਸ਼ਿਸ਼ਾਂ ਦੋਹਾਂ ਵਿੱਚ ਬੇਹੱਦ ਕੀਮਤੀ ਸਾਬਤ ਹੋਏ ਹਨ। ਇਹ ਹੁਨਰ ਸ਼ਾਮਲ ਹਨ:
- Node.js, JavaScript, ਅਤੇ Express.js ਰਾਹੀਂ APIs ਵਿਕਸਿਤ ਕਰਨਾ
- ਡੇਟਾ ਪ੍ਰਬੰਧਨ ਲਈ PostgreSQL ਸੈਟਅਪ ਕਰਨ ਅਤੇ ਵਰਤਣ ਦੀ ਸਮਰੱਥਾ
- API ਵਿਕਾਸ ਵਿੱਚ PostgresSQL ਨੂੰ ਸ਼ਾਮਲ ਕਰਨਾ, PG ਵਰਗੇ ਪੈਕੇਜਾਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ।
- ਬਿਹਤਰ ਡੇਟਾ ਸੁਰੱਖਿਆ ਲਈ RSA (ਅਸਮਮਿਤ ਇੰਕ੍ਰਿਪਸ਼ਨ) ਅਤੇ AES (ਸਮਮਿਤ ਇੰਕ੍ਰਿਪਸ਼ਨ) ਦੀ ਵਰਤੋਂ।
ਨਤੀਜਾ
ਕੁੱਲ ਮਿਲਾ ਕੇ, ਹਾਲਾਂਕਿ ਆਖਰੀ ਨਤੀਜੇ ਨਾਲ ਨਿਰਾਸ਼ ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ਮੈਨੂੰ ਖੁਸ਼ੀ ਹੈ ਕਿ ਅਸੀਂ ਇਸ ਹੈਕਥਾਨ ਵਿੱਚ ਭਾਗ ਲਿਆ। ਮੈਂ ਉਹ ਕੀਮਤੀ ਸਿੱਖਿਆਵਾਂ ਅਤੇ ਹੁਨਰਾਂ ਦਾ ਆਭਾਰੀ ਹਾਂ ਜੋ ਮੈਂ Labeler NearBy ‘ਤੇ ਕੰਮ ਕਰਦਿਆਂ ਹਾਸਲ ਕੀਤੇ, ਕਿਉਂਕਿ ਉਨ੍ਹਾਂ ਨੇ ਮੈਨੂੰ ਇਕ ਵਧੀਆ ਡਿਵੈਲਪਰ ਬਣਾਇਆ ਹੈ ਅਤੇ ਮੇਰੇ ਅਗਲੇ ਪ੍ਰੋਜੈਕਟ Notify-Cyber ਦੇ ਵਿਕਾਸ ਵਿੱਚ ਮਹੱਤਵਪੂਰਨ ਯੋਗਦਾਨ ਦਿੱਤਾ ਹੈ।
ਹੋਰ ਨੋਟਸ
- ਮੈਂ ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਮੁੜ Labeler NearBy ਵੱਲ ਆਵਾਂ, ਪਰ ਇਸ ਵੇਲੇ ਲਈ, ਇਹ ਪ੍ਰੋਜੈਕਟ “ਲੰਬੇ ਅੰਤਰਾਲ” ‘ਤੇ ਹੈ
- ਵਰਤਮਾਨ ਵਿੱਚ, Labeler NearBy ਨੂੰ ਕੇਵਲ NEAR ਦੀ testnet ‘ਤੇ ਹੀ ਚਲਾਇਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਸਨੂੰ ਹੋਰ ਵਿਕਾਸ, ਟੈਸਟਿੰਗ ਅਤੇ ਆਡਿਟਿੰਗ ਦੀ ਲੋੜ ਹੈ।