InsightRed와 함께하는 ABM 마케팅
![]()
소개
InsightRed는 LLM 기반의 Account-Based Marketing (ABM) 도구로, Subreddit에서 “Hot"으로 정렬된 최신 Reddit 댓글을 추출하고 제품이나 프로젝트에 잠재적 관심을 보이는 사용자를 정확히 찾아냅니다. 이 도구는 Reddit에서 초기 사용자들을 확보하기 위해 고가치 사용자를 식별하고 타겟팅하는 데 도움을 줍니다. 이 프로젝트는 ANARCHY 2023년 10월 해커톤을 위해 만들어졌습니다.
발표
2023년 10월 19일
이 프로젝트에 이어, 저는 우리가 Anarchy의 2023년 10월 해커톤에서 1위를 차지했다는 소식을 전하게 되어 기쁩니다!
Discord의 서식을 수정하여 TEXT 모드로 메시지를 보려면 여기를 클릭하세요
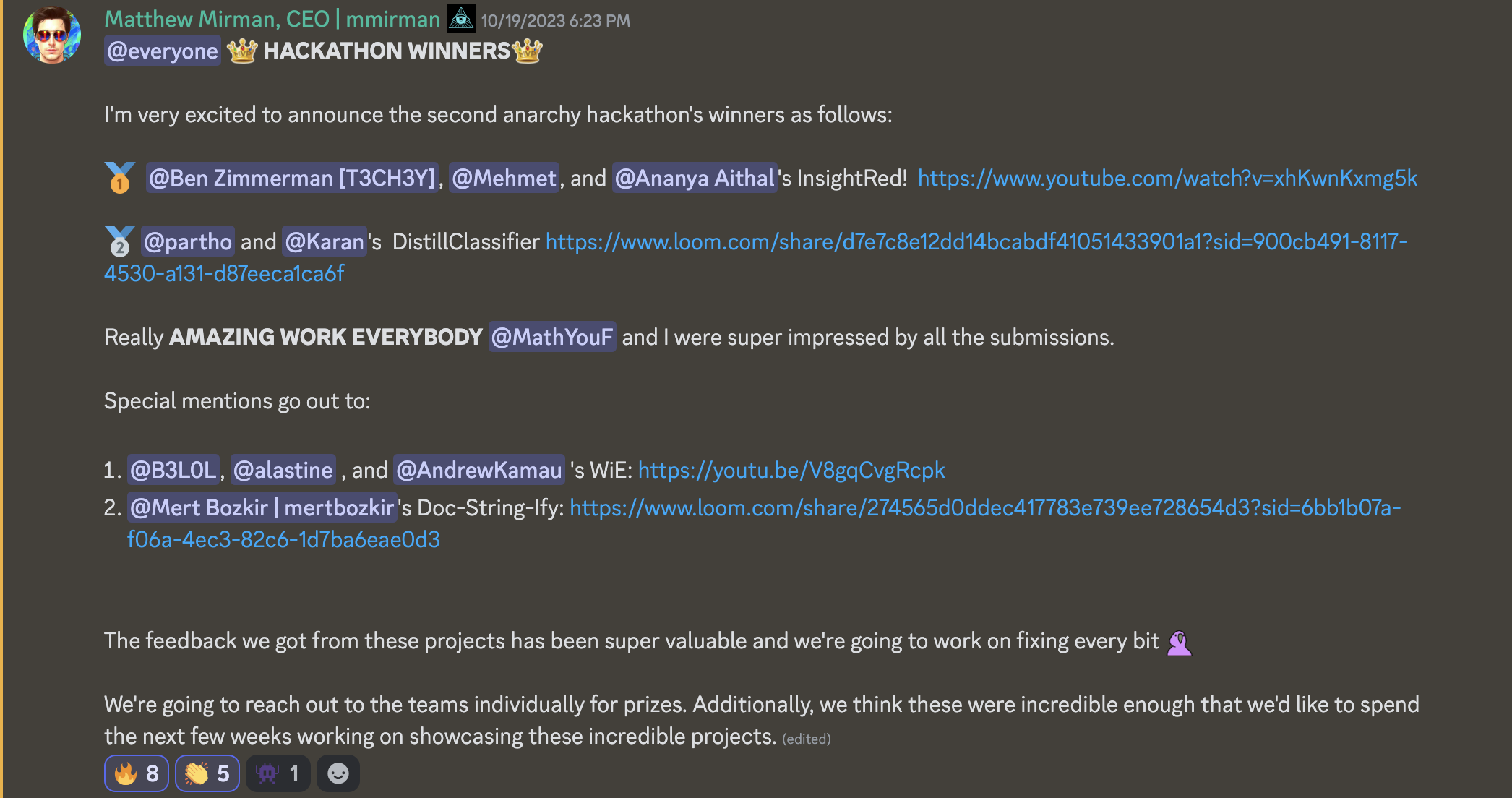
@everyone **👑 HACKATHON 👑**
I'm very excited to announce the second anarchy hackathon's winners as follows:
🥇 "@Ben Zimmerman [T3CH3Y]", @Mehmet, and "@Ananya Aithal"'s InsightRed! https://www.youtube.com/watch?v=xhKwnKxmg5k
🥈 @partho and @Karan's DistillClassifier https://www.loom.com/share/d7e7c8e12dd14bcabdf41051433901a1?sid=900cb491-8117-4530-a131-d87eeca1ca6f
Really **AMAZING WORK EVERYBODY** @MathYouF and I were super impressed by all the submissions.
Special mentions go out to:
1. @B3LOL, @alastine , and @AndrewKamau 's WiE: https://youtu.be/V8gqCvgRcpk
2. "@Mert Bozkir | mertbozkir"'s Doc-String-Ify: https://www.loom.com/share/274565d0ddec417783e739ee728654d3?sid=6bb1b07a-f06a-4ec3-82c6-1d7ba6eae0d3
The feedback we got from these projects has been super valuable and we're going to work on fixing every bit 🦜
We're going to reach out to the teams individually for prizes. Additionally, we think these were incredible enough that we'd like to spend the next few weeks working on showcasing these incredible projects.
데모
InsightRed의 구성 요소
🧩 수집기
수집기(Collector)는 주어진 Subreddit들에 대해 Reddit의 API를 사용하여 최신 Reddit 게시물과 해당 게시물의 댓글을 수집합니다. 수집 후, 수집된 데이터는 로컬 SQLite 데이터베이스에 저장됩니다. 이는 Reddit API 사용을 보조하는 파이썬 패키지 praw와 로컬 SQLite 데이터베이스에서 CRUD 작업을 수행하는 SQLAlchemy를 사용함으로써 쉽게 구현됩니다.
🧩 벡터화기
벡터화기(Vectorizer)는 로컬 SQLite 데이터베이스를 확인하여 벡터 데이터베이스에 저장되지 않은 댓글들을 확인합니다. 댓글 목록을 받은 후, 게시물+댓글의 임베딩을 OpenAI의 “text-embedding-ada-002” 모델을 사용하여 생성합니다. 이 임베딩은 벡터 데이터베이스의 인덱스로 사용되며, JSON 형식의 일부 메타데이터도 생성됩니다. 인덱스와 메타데이터는 이 경우 클라우드 기반인 Pinecone 벡터 데이터베이스에 업로드됩니다. 업로드된 후에는 동일한 데이터를 Pinecone에 다시 업로드하지 않도록 로컬 SQLite 데이터베이스가 업데이트됩니다. 이 모든 과정은 벡터 데이터베이스에 대한 CRUD 작업을 수행하기 위해 Pinecone의 파이썬 클라이언트(pinecone-client)와 임베딩 과정을 처리하기 위한 LangChain을 사용하여 이루어집니다.
🧩 인터페이스
인터페이스는 사용자가 도구와 상호작용하는 데 사용되는 부분입니다. 이 경우 인터페이스는 CLI입니다. 인터페이스에는 Retrieval-Augmented-Generation (RAG)의 구현이 포함되어 있습니다. 사용자는 제품 설명, 확인할 Subreddit 목록 및 몇 가지 필터를 제공합니다. 이러한 컨텍스트가 주어지면 수집기(Collector)가 호출되고 그 다음 벡터화기(Vectorizer)가 호출됩니다. 이 두 서비스가 처리를 마치면 입력된 제품 설명을 사용하여 벡터 데이터베이스에서 유사한 검색을 수행합니다. 상위 결과들과 제품 설명은 프롬프트 템플릿에 전달되어 최종 프롬프트를 생성합니다. 최종 프롬프트는 OpenAI의 GPT-4 모델로 전송되고 최종 결과가 사용자에게 제공됩니다. 이 결과들은 주어진 설명을 바탕으로 Reddit 사용자들이 제품에 관심을 가질 가능성이 높은 모든 Reddit 댓글의 목록이 될 것입니다. 이 구성 요소는 수집기와 벡터화기의 댓글들 및 OpenAI의 GPT-4 모델 쿼리를 처리하기 위해 Anarchy의 LLM-VM을 사용하여 작동합니다.
팀 구성원
주목할 외부 크레딧
casta (Hacker News)
이 프로젝트에 영감을 제공한 것은 그들의 HN 게시물입니다. 그들의 솔루션은 오픈 소스가 아니었기 때문에 저는 오픈 소스 버전(이 프로젝트)을 만들 동기를 얻었습니다.
ChatGPT (GPT-4)
개발 속도를 크게 높여 개발에 많은 도움을 주었습니다. 또한 OpenAI의 새로운 DALL-E 3 모델을 사용하여 프로젝트 로고와 YouTube 썸네일을 생성했습니다.
James Briggs (YouTuber)
James의 비디오는 Reddit의 API 사용 방법과 파이썬을 사용한 기본 RAG 파이프라인 구현 방법을 잘 설명해 주었습니다.
출처
- Show HN: Labor Day Fun Project, Find Reddit Comments to Promote Your Business
- Pinecone 인덱싱 개요 문서
- YouTube: Chatbots with RAG - LangChain Full Walkthrough
- OpenAI API 페이지
- Pinecone 빠른 시작 문서
- Reddit: 향후 몇 주 내에 시행될 업데이트된 속도 제한
- Reddit 앱 페이지
- YouTube: How-to Use The Reddit API in Python
- Medium: Scraping Reddit data using Reddit API
- GitHub Gist: Reddit API
- GitHub: praw
- ChatGPT - 웹 앱