InsightRedによるABMマーケティング
![]()
概要
InsightRedは、最新のRedditコメントを「ホット」でソートされたSubredditから抽出し、あなたのプロジェクトや製品に潜在的な興味を示すユーザーを特定するLLM駆動のアカウントベースマーケティング(ABM)ツールです。これにより、Reddit上で高価値のユーザーを特定し、あなたの製品/プロジェクトの初期ユーザーを獲得するのに役立ちます。このプロジェクトは、ANARCHY 2023年10月ハッカソンのために構築されました。
発表
2023年10月19日
このプロジェクトのフォローアップとして、Anarchyの2023年10月ハッカソンで1位を獲得したことを発表できることを嬉しく思います!
テキストモードでメッセージを表示するにはここをクリックしてください(Discordのフォーマットのために修正されています)
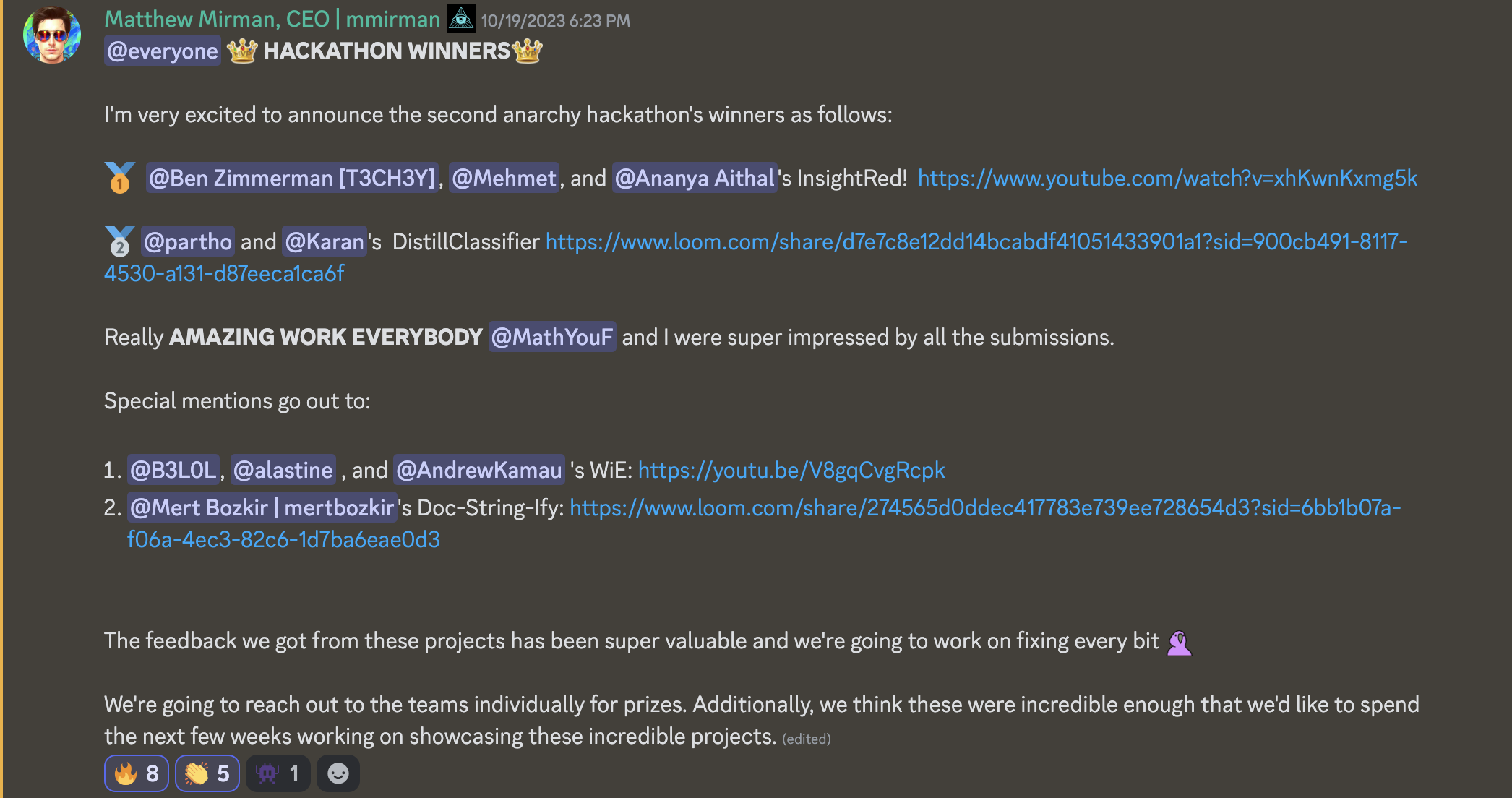
@everyone **👑 ハッカソン 👑**
第二回アナーキー・ハッカソンの受賞者を発表できることを非常に嬉しく思います:
🥇 "@Ben Zimmerman [T3CH3Y]", @Mehmet, および "@Ananya Aithal" のInsightRed! https://www.youtube.com/watch?v=xhKwnKxmg5k
🥈 @partho と @Karan のDistillClassifier https://www.loom.com/share/d7e7c8e12dd14bcabdf41051433901a1?sid=900cb491-8117-4530-a131-d87eeca1ca6f
本当に **素晴らしい仕事を皆さん** @MathYouF と私はすべての提出物に非常に感銘を受けました。
特別な言及は以下の通りです:
1. @B3LOL, @alastine , および @AndrewKamau のWiE: https://youtu.be/V8gqCvgRcpk
2. "@Mert Bozkir | mertbozkir" のDoc-String-Ify: https://www.loom.com/share/274565d0ddec417783e739ee728654d3?sid=6bb1b07a-f06a-4ec3-82c6-1d7ba6eae0d3
これらのプロジェクトから得たフィードバックは非常に貴重で、私たちはすべての部分を修正するために取り組むつもりです🦜
私たちは賞のためにチームに個別に連絡を取ります。さらに、これらのプロジェクトは素晴らしいものであり、次の数週間でこれらの素晴らしいプロジェクトを紹介するために取り組みたいと考えています。
デモ
InsightRedのコンポーネント
🧩 コレクター
コレクターは、指定されたSubredditから最新のReddit投稿とその投稿のコメントをRedditのAPIを使用して収集します。収集後、コレクターは収集したデータをローカルのSQLiteデータベースに保存します。これは、Reddit APIを使用するためにpythonパッケージのprawを使用し、ローカルのSQLiteデータベースでCRUD操作を行うためにSQLAlchemyを使用することで簡単に行えます。
🧩 ベクトライザー
ベクトライザーは、ローカルのSQLiteデータベースをチェックして、ベクトルデータベースに保存されていないコメントを確認します。コメントのリストを取得した後、OpenAIの「text-embedding-ada-002」モデルを使用して投稿+コメントの埋め込みを作成します。この埋め込みはベクトルデータベースのインデックスとして使用され、JSON形式のメタデータも作成されます。インデックスとメタデータは、その場合はパインコーン(クラウドベース)にアップロードされます。アップロード後、ローカルのSQLiteデータベースは、同じデータを再度パインコーンにアップロードしないように更新されます。これは、ベクトルデータベースに対するCRUDオプションを作成するためにパインコーンのpythonクライアント(pinecone-client)を使用し、埋め込みプロセスを処理するためにLangChainを使用することで行われます。
🧩 インターフェース
インターフェースは、ユーザーがツールと対話するために使用されるものです。この場合、インターフェースはCLIです。インターフェースには、Retrieval-Augmented-Generation(RAG)の実装があります。ユーザーは製品の説明、チェックするSubredditのリスト、およびいくつかのフィルターを提供します。このコンテキストを考慮して、コレクターが呼び出され、その後ベクトライザーが呼び出されます。これらの2つのサービスが処理を終えた後、入力された製品の説明を使用してベクトルデータベースで類似の検索を行います。トップの結果と製品の説明は、最終的なプロンプトを作成するためのプロンプトテンプレートに供給されます。最終的なプロンプトはOpenAIのGPT-4モデルに送信され、最終結果がユーザーに提示されます。これらの結果は、提供された製品の説明に基づいて、Redditユーザーが興味を持つ可能性が高いすべてのRedditコメントのリストになります。このコンポーネントは、コレクターとベクトライザーのコメントを使用し、AnarchyのLLM-VMを使用してOpenAIのGPT-4モデルにクエリを処理することで機能します。
チームメンバー
注目すべき外部クレジット
casta (Hacker News)
彼らのHN投稿を通じてこのプロジェクトのインスピレーションを提供しました。彼らの解決策はオープンソースではなかったため、オープンソース版(このプロジェクト)を作成する動機となりました。
ChatGPT (GPT-4)
開発を非常にスピードアップさせることで非常に役立ちました。また、OpenAIの新しいDALL-E 3モデルを使用してプロジェクトのロゴとYouTubeサムネイルを生成しました。
ジェームズ・ブリッグス (YouTuber)
ジェームズのビデオは、RedditのAPIの使用方法や、Pythonを使用した基本的なRAGパイプラインの実装方法を非常にわかりやすく説明していました。
ソース
- Show HN: 労働者の日の楽しいプロジェクト、ビジネスを宣伝するためのRedditコメントを見つける
- パインコーンインデックスの概要ドキュメント
- YouTube: RAGを使用したチャットボット - LangChain完全ガイド
- OpenAI APIページ
- パインコーンクイックスタートドキュメント
- Reddit: 今後数週間にわたって発効する更新されたレート制限
- Redditアプリページ
- YouTube: PythonでReddit APIを使用する方法
- Medium: Reddit APIを使用してRedditデータをスクレイピングする
- GitHub Gist: Reddit API
- GitHub: praw
- ChatGPT - ウェブアプリ