Top Coder Challenge di 8090
Post originale su LinkedIn
Repo GitHub del progetto
Venerdì sera ho visto un post pubblico su Twitter/X di Chamath Palihapitiya che annunciava una Top Coder Challenge aperta organizzata dalla sua nuova azienda, 8090 Solutions. Chiunque poteva partecipare. La sfida si sarebbe svolta il giorno successivo, sarebbe durata solo 8 ore e avrebbe richiesto l’analisi inversa di un sistema legacy a scatola nera utilizzando solo dati storici e alcune interviste ai dipendenti.
Ho deciso di partecipare!
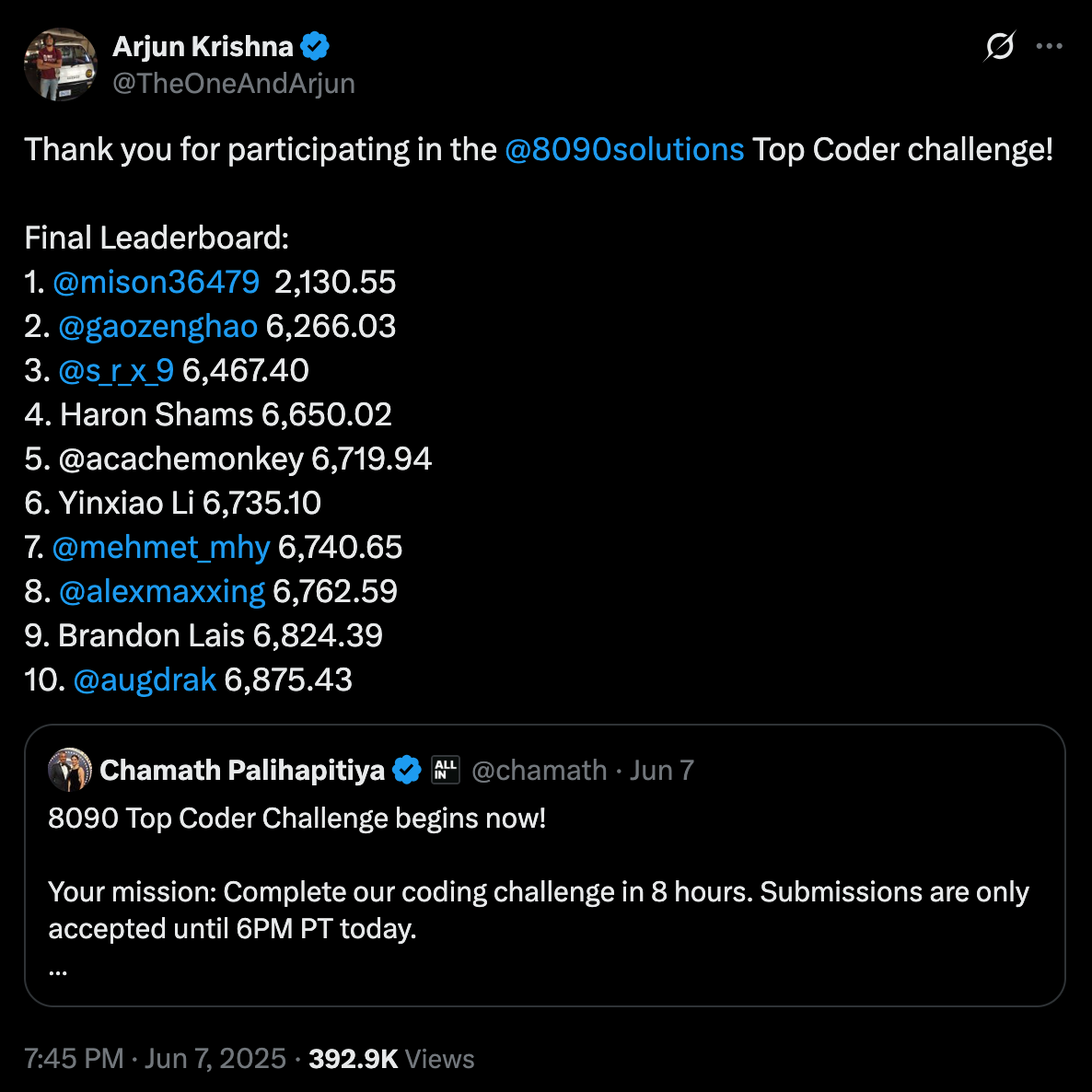
Entro la fine della giornata, sono stato onorato di classificarmi 7° su 425 ingegneri. Puoi consultare la classifica QUI e consultare il codice per questa sfida QUI. Ma non mentirò: onestamente speravo solo di riuscire a finire qualcosa in quel breve lasso di tempo, quindi entrare in classifica è stata una sorpresa e una grande vittoria personale per me.
La sfida era individuale, e l’obiettivo era replicare un sistema di rimborso spese di viaggio a scatola nera vecchio di 60 anni che non aveva codice sorgente né documentazione. Ci sono stati forniti alcuni artefatti, tra cui un brief di prodotto, trascrizioni di interviste ai dipendenti e un dataset pubblico contenente 1.000 esempi storici di input e output attesi. Da questi dovevo dedurre la logica di business dietro il calcolo degli importi di rimborso e implementare una versione moderna in grado di produrre risultati il più possibile simili. Le sottomissioni sono state valutate su un dataset nascosto separato contenente 5.000 casi di test invece dei 1.000 originali. Questo set privato più grande è stato ciò che ha determinato il punteggio finale e la classifica. Il sistema di punteggio premiava l’accuratezza, dove un punteggio più basso significava che la tua soluzione corrispondeva più da vicino al comportamento nascosto del sistema originale.
Per affrontare l’incertezza e i pattern nei dati, ho usato tecniche classiche di machine learning insieme a euristiche di base e logica programmatica. È stata una combinazione accurata di analisi dei dati, modellazione delle feature e approssimazione delle regole basata su indizi imperfetti.
Ecco il mio punteggio eval per il dataset pubblico da 1.000:
✅ Evaluation Summary
------------------------
Total cases : 1000
Exact matches (<$0.01): 0
Close matches (<$1.00): 17
Average error : $31.15
Score : 3214.93
Sviluppare una soluzione a una sfida del genere in 8 ore sarebbe stato quasi impossibile senza l’aiuto di strumenti basati sull’IA che hanno reso più facile esplorare, integrare e testare rapidamente le idee.
Sembrava archeologia del software combinata con uno sprint di coding dal vivo. Di gran lunga una delle sfide tecniche più intense e gratificanti che abbia affrontato.
Grazie a Chamath Palihapitiya e Arjun Krishna per aver organizzato una sfida così creativa e ispiratrice.
Link: