Prevedere le Azioni Umane
Repository GitHub del progetto
Dettagli
Questo progetto è stato il progetto #3 per il corso Human Centered Robotics (CSCI473) del Dr. Zhang presso il Colorado School of Mines durante il semestre della primavera 2020. È stato progettato per fornire un’introduzione al machine learning nella robotica attraverso l’uso delle Support Vector Machines (SVM). Le consegne/la descrizione originali del progetto possono essere consultate qui.

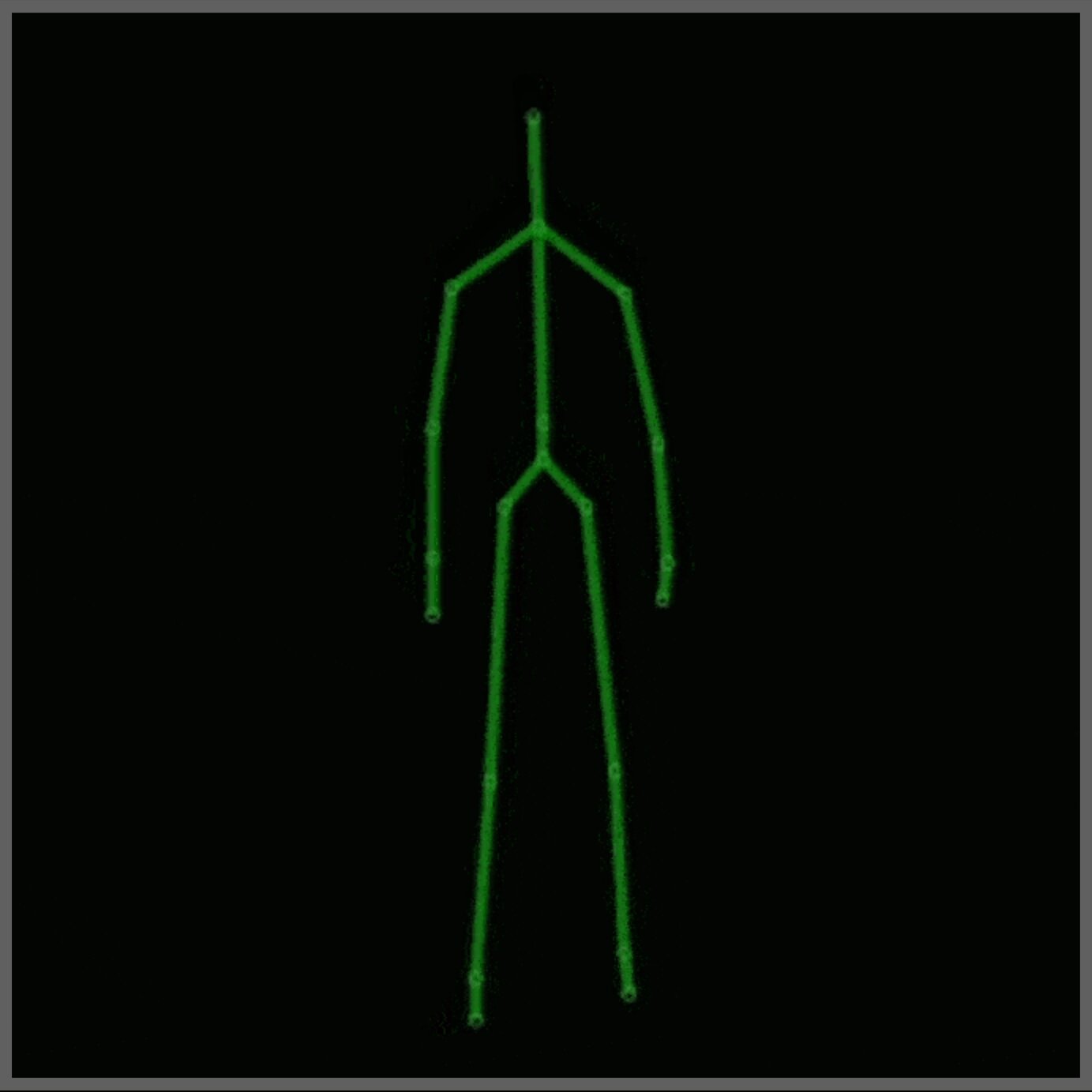
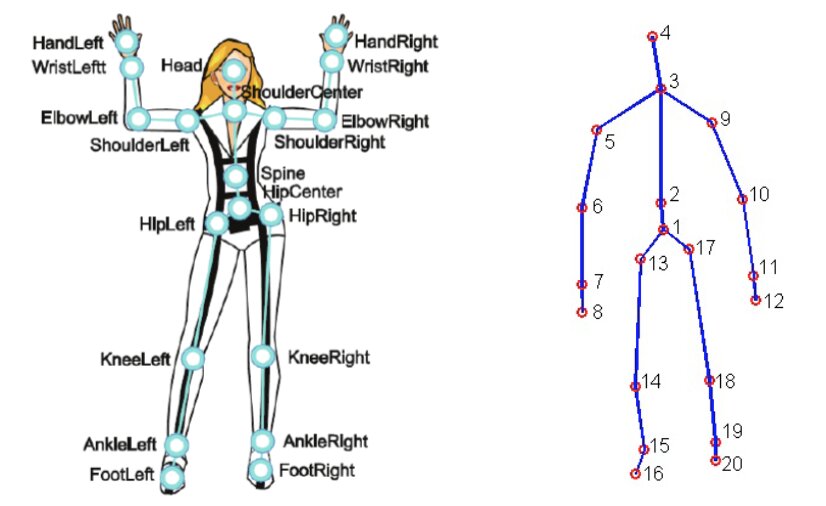
Per questo progetto è stato utilizzato il MSR Daily Activity 3D Dataset (Figura 2), con alcune modifiche. Questo dataset contiene 16 attività umane raccolte da un sensore Xbox Kinetic e memorizzate come scheletri. Gli scheletri sono un array di coordinate del mondo reale, (x, y, z), di 20 articolazioni di un essere umano registrate in un singolo frame. Ecco una figura che mostra cos’è uno scheletro:
Per ottenere la previsione delle azioni umane, i dati grezzi devono essere rappresentati in una forma che possa essere elaborata da una SVM. Per questo progetto sono state utilizzate le seguenti rappresentazioni:
- Rappresentazione degli Angoli e delle Distanze Relative (RAD)
- Rappresentazione dell’Istogramma delle Differenze di Posizione delle Articolazioni (HJPD)
Per la classificazione, la/le rappresentazione/i vengono inviate a una SVM, alimentata da LIBSVM, per creare un modello che possa prevedere le azioni umane. Verranno creati due modelli, uno utilizzando RAD e un altro utilizzando HJPD. L’obiettivo è rendere questi modelli il più accurati possibile e vedere quale rappresentazione funziona meglio.
Sapendo questo, ecco una panoramica di ciò che fa il codice:
- Caricare i dati grezzi dal dataset modificato
- Rimuovere eventuali dati anomali e/o errati dal dataset caricato
- Convertire i dati grezzi finali nelle rappresentazioni RAD e HJPD
- Le rappresentazioni vengono inviate a SVM ottimizzate per generare due modelli
- I due modelli vengono quindi alimentati con dati grezzi di test e viene generata una matrice di confusione per misurare come il/i modello/i abbia/hanno performato.
Risultati
Dopo aver eseguito il codice e ottimizzato i modelli al meglio delle mie capacità, ecco la matrice di confusione finale per entrambi i modelli RAD e HJPD:
Representation: RAD
Accuracy: 62.5%
LIBSVM Classification 8.0 10.0 12.0 13.0 15.0 16.0
Actual Activity Number
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Representation: HJPD
Accuracy: 70.83%
LIBSVM Classification 8.0 10.0 12.0 13.0 15.0 16.0
Actual Activity Number
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Conclusione
Dato che entrambe le accuratezze sono superiori al 50%, questo progetto è stato un successo. Inoltre, la rappresentazione HJPD sembra essere la rappresentazione più accurata da usare per questa classificazione. Con questo, c’è un modello/modelli che prevede/prevedono le azioni umane utilizzando dati scheletrici. Il modello/i qui presenti è/sono lontano/i dall’essere perfetto/i, ma è/sono migliore/i del caso casuale. Questo progetto è stato ciò che ha dato vita in seguito al progetto Moving Pose.
Note aggiuntive:
- Questo progetto è stato testato su Python versione 3.8.13
- Per questo progetto, vengono utilizzati il dataset MDA3 completo e un dataset MDA3 modificato. L’MDA3 modificato contiene solo le attività 8, 10, 12, 13, 15 e 16. Inoltre, la versione modificata contiene alcuni punti dati “corrotti”, mentre il dataset completo no.
- Rappresentazione Spazio-Tempo delle Persone Basata su Dati Scheletrici 3D: Una Revisione
- YouTube: Come Funziona il Sensore di Profondità Kinect in 2 Minuti
- Medium: Comprendere le Articolazioni e il Sistema di Coordinate di Kinect V2
- Pagina Wikipedia di Kinect
- Jameco Xbox Kinect
- Informazioni su SVM e LibSVM: cjlin libsvm, pagina libsvm su pypi, e libsvm github
- Logica e documentazione di SVM e LIBSVM: articolo guida di cjlin e dataset di cjlin libsvmtools
- Informazioni sul dataset usato/modificato