Costruire Labeler NearBy
Table of Contents

Il mio primo hackathon
Durante la seconda parte dell’estate 2022, volevo davvero lavorare a un progetto entusiasmante. Avevo appena terminato la laurea e lavoravo a tempo pieno come ingegnere del software. Volevo davvero dedicarmi a un progetto secondario e, all’epoca, avevo abbastanza tempo libero per farlo. Non sapevo davvero su cosa lavorare, fino a quando non ho scoperto un sito chiamato Devpost nell’agosto 2022. Devpost è un sito che ospita competizioni software chiamate hackathon. Navigando su Devpost, ho scoperto un hackathon chiamato NEAR MetaBUILD III, che era un hackathon ospitato dall’organizzazione NEAR Protocol.
Cos’è NEAR?
Il NEAR Protocol è una blockchain che supporta smart contract e la criptovaluta NEAR. È principalmente noto per avere commissioni di transazione molto basse, supportare smart contract, avere la propria rete di test ufficiale e un ottimo ambiente per sviluppatori grazie al fatto che puoi scrivere smart contract in Rust e/o JavaScript. Puoi ottenere una panoramica migliore del NEAR Protocol tramite il fantastico video di CoinGecko:
Durante questo periodo, Coinbase ha ufficialmente iniziato a supportare il NEAR Protocol come moneta scambiabile sulla sua piattaforma. Questo è stato importante perché Coinbase è conosciuta per essere molto selettiva riguardo alle monete che supporta sulla propria piattaforma. Questo ha contribuito a rendere NEAR una piattaforma più affidabile. Puoi ancora scambiare NEAR su Coinbase ancora oggi.
Perché impegnarsi?
Dopo averci riflettuto un po’, ho deciso di dedicare il mio tempo a competere nell’hackathon NEAR MetaBUILD III. Le mie ragioni erano le seguenti:
- La criptovaluta non scomparirà ed è una tecnologia che resterà. Quindi aveva senso investire del tempo per imparare questa tecnologia.
- L’hackathon offriva grandi premi, da $20.000 a $100.000 in NEAR se fossi stato uno dei vincitori.
- L’hackathon aveva una scadenza specifica, il che significava che il progetto non poteva trascinarsi per mesi come spesso accade per molti progetti secondari.
- Il progetto sarebbe stata una grande esperienza di apprendimento e un’ottima introduzione agli hackathon.
- Nel peggiore dei casi, l’hackathon mi avrebbe permesso di realizzare un ottimo progetto da mostrare sul mio curriculum.
Con tutto ciò in mente, ho chiamato il mio caro amico del college il 26 agosto 2022 e abbiamo iniziato a pianificare questo hackathon. L’hackathon era previsto iniziare il 23 settembre 2023 e concludersi il 21 novembre 2022. Tuttavia la scadenza è stata estesa fino al 24 novembre 2023 verso la fine dell’hackathon. Poiché eravamo con un mese di anticipo, abbiamo deciso di trascorrere questo tempo imparando e facendo brainstorming su cosa avremmo lavorato per questo hackathon di 2 mesi. Durante quel primo mese, abbiamo ottenuto una panoramica generale su crypto e blockchain. Abbiamo rivisto e praticato sulla testnet di NEAR, esaminato l’SDK di NEAR e distribuito un paio di smart contract.
L’idea
Con una buona introduzione a tutto ciò che riguarda blockchain e NEAR, abbiamo iniziato a fare brainstorming di idee. Volevo che questo progetto fosse qualcosa che non fosse solo un “progetto da hackathon”, ma qualcosa che potesse diventare un prodotto che altri potessero utilizzare e fungere da esempio di come la crypto possa essere utile per cose al di fuori del semplice trading.
Con questo in mente, inizialmente abbiamo deciso di creare qualcosa di simile a Unreal Engine Blueprint, ma per la facile creazione e distribuzione di smart contract sulla blockchain NEAR senza la necessità di programmare. Tuttavia, una settimana prima dell’inizio dell’hackathon, abbiamo abbandonato l’idea perché semplicemente non aveva senso. Perché qualcuno si sarebbe preso la briga di usare il nostro strumento per creare smart contract NEAR se non esisteva ancora un caso d’uso pratico per essi? Sarebbe stato come sviluppare uno strumento di cui molte persone non avevano bisogno.
Con solo una settimana rimasta prima dell’inizio dell’hackathon, abbiamo ricominciato a fare brainstorming e ci siamo decisi per questa idea:
A decentralized platform where AI researchers can outsource
data labeling to labelers around the world
Abbiamo chiamato il progetto “Labeler NearBy.” La nostra decisione di scegliere questa idea si basava sui seguenti motivi:
- Lo sviluppo dell’IA richiede l’annotazione umana dei dati per l’addestramento.
- Trovare e gestire persone qualificate per annotare dataset specifici è difficile.
- L’idea è già stata implementata con successo da un’azienda chiamata Scale AI, come dimostra il modo in cui ha trovato un product-market fit.
- Servizi centralizzati come Scale AI sollevano preoccupazioni poiché le organizzazioni devono inviare i loro dati alla società di annotazione, che poi esternalizza annotatori umani a livello globale. Dopo il processo di annotazione, la società restituisce i dati annotati all’organizzazione. Questo comporta la perdita di controllo su dati di addestramento preziosi, che potrebbero essere utilizzati dalla società di annotazione per addestrare i propri modelli. Decentralizzare questo servizio sembrava una soluzione logica.
- Abbiamo trovato pochissimi progetti nello spazio delle applicazioni decentralizzate (dApp) che lavorassero su questa idea, offrendo un’opportunità per innovare e fare da pionieri in questo settore.
Per ridurre la complessità, abbiamo deciso che Labeler NearBy supporterà solo dati di immagini per il momento.
Sottomissione
Con l’idea scelta e l’hackathon ufficialmente iniziato, il mio amico ed io abbiamo cominciato a costruire Labeler NearBy. Abbiamo lavorato al nostro progetto per 2 mesi fino a quando abbiamo inviato la versione finale del nostro progetto a Devpost il 24 novembre 2022. Abbiamo inviato il nostro progetto su Devpost e abbiamo anche creato una copia della nostra sottomissione su Github. Questo blog non copre ogni aspetto tecnico e il processo di sviluppo di Labeler NearBy. Detto ciò, per saperne di più su come funziona Labeler NearBy o per vedere la nostra sottomissione finale, visita uno dei seguenti link:
Labeler NearBy è composto da due codebase: ln-researcher e ln-labeler. Queste codebase sono completamente open source sotto licenza MIT e possono essere visualizzate tramite i seguenti link:
Ecco una panoramica generale di come funzionerebbe Labeler NearBy (LN):
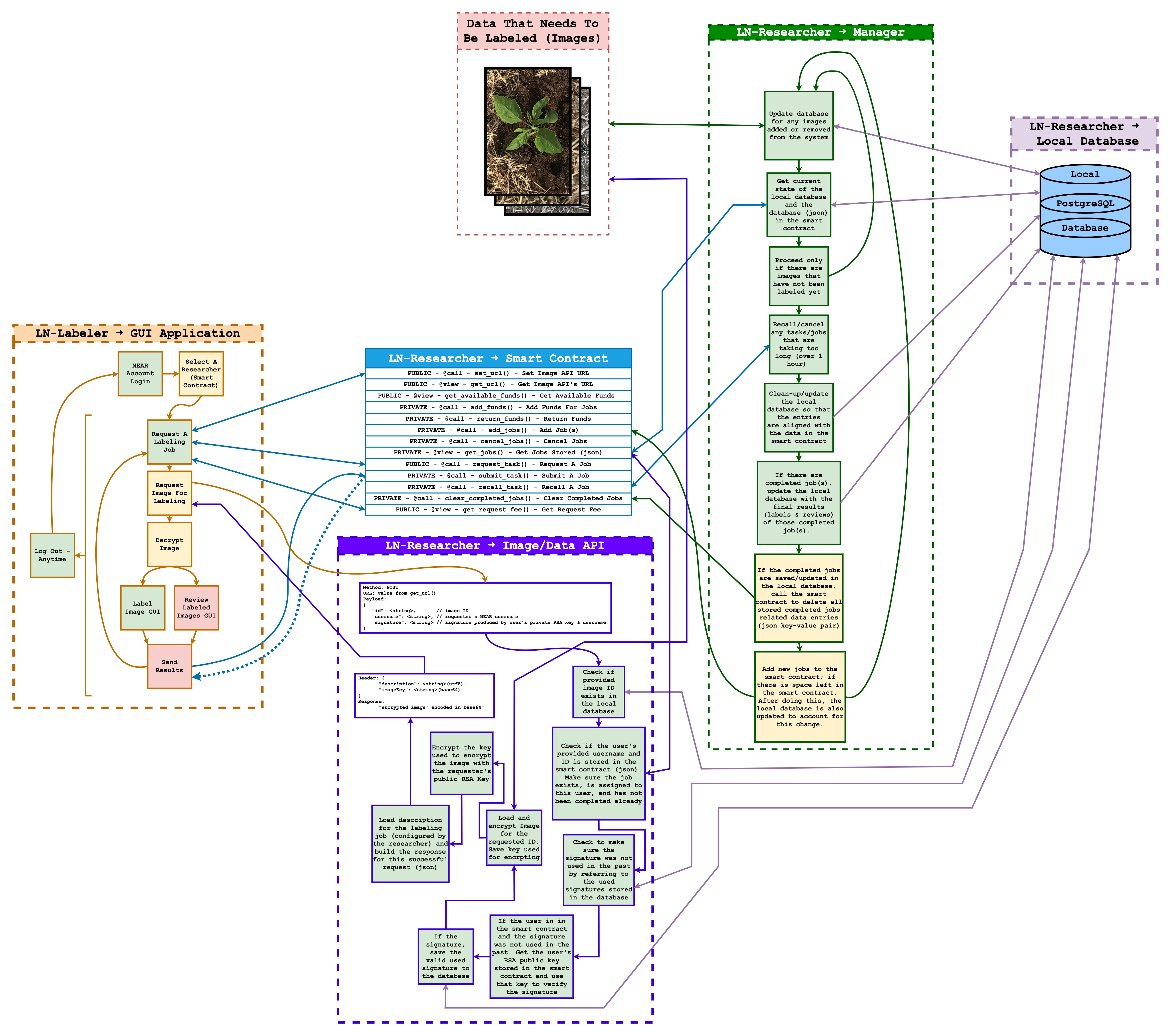
Un ricercatore necessita di immagini etichettate per addestrare il proprio modello di IA. Per ottenere ciò, il ricercatore utilizza LN per ospitare i propri dati e fornire un mezzo per consentire ai labeler di etichettare i dati. Questo viene realizzato tramite ln-researcher, un servizio web auto-ospitato che consiste in un’API, gli smart contract del ricercatore e un database Postgres locale. Per il labeler, è (sarebbe stato) fornito un frontend web, che gli consente di accedere e etichettare le immagini del ricercatore. Durante il processo di etichettatura, un’immagine viene etichettata tre volte da labeler diversi. Solo il labeler con le etichette migliori, determinate tramite un sistema di votazione, viene ricompensato con NEAR coin. L’app web responsabile di questo processo si chiama ln-labeler. Il ricercatore finanzia ogni operazione di etichettatura, e le NEAR coin possono essere facilmente convertite in dollari tramite Coinbase. Tutta la logistica delle transazioni è gestita da smart contract ospitati sulla blockchain NEAR Protocol.
Puoi vedere il nostro video dimostrativo di Labeler NearBy per l’hackathon qui:
Il più grande risultato
La funzione di cui sono più orgoglioso di aver implementato è una funzione chiamata getImage(). Questa funzione funge da endpoint API in ln-researcher e svolge un ruolo cruciale nella pipeline dei dati tra ricercatori e labeler in Labeler NearBy (LN).
Questo endpoint API consente ai ricercatori di distribuire in modo sicuro e affidabile le loro immagini per l’etichettatura. Le assegnazioni di etichettatura sono gestite tramite smart contract NEAR sulla blockchain NEAR Protocol, mentre i dati delle immagini sono ospitati dal ricercatore tramite ln-researcher.
L’endpoint esegue una serie di controlli di sicurezza per assicurare che solo il labeler assegnato possa accedere all’immagine. Ciò include la verifica della firma della richiesta e il controllo dello smart contract associato per confermare l’esistenza del task e la sua assegnazione al labeler richiedente.
Una volta che la richiesta è convalidata nell’API auto-ospitata del ricercatore ln-researcher, la funzione recupera l’immagine dal database Postgres locale, la cripta e la consegna al labeler autorizzato che può quindi decriptare l’immagine per l’etichettatura. Contemporaneamente, la funzione aggiorna lo stato dell’immagine nel database, indicando l’avanzamento del processo di etichettatura. In tutto questo processo, vengono utilizzate chiavi RSA sia del ricercatore sia del labeler per l’autenticazione. L’AES viene utilizzato per crittografare l’immagine.
Questo endpoint svolge un ruolo critico nella gestione della distribuzione sicura e controllata delle immagini dai ricercatori ai labeler. Garantisce il trasferimento sicuro dei dati e traccia e gestisce efficacemente il processo di etichettatura delle immagini. Inoltre, questo processo ha il potenziale di eliminare la necessità di usare HTTPS, almeno per questo endpoint.
Questo specifico endpoint/funzione è stato testato e dimostrato funzionante. Qui sotto c’è un diagramma che illustra la funzionalità complessiva di Labeler NearBy, incluso una chiara rappresentazione di come funziona l’endpoint/funzione sopra menzionato:
Risultato
Purtroppo, la triste realtà è che non siamo riusciti a completare completamente questo progetto entro la scadenza dell’hackathon. La maggior parte del progetto è stata completata, come ln-researcher, ma il frontend (ln-labeler) non è stato completato e non siamo riusciti a lanciare una demo dal vivo. Anche se il backend (ln-researcher) era sostanzialmente completato, senza un frontend funzionante e senza una demo dal vivo, nessuno ha potuto provare l’idea di Labeler NearBy. Non solo, ma i giudici non hanno potuto provare il progetto e hanno dovuto invece leggere la sottomissione, esaminare il codice e/o provare a eseguirlo da soli. Il che ha fatto scendere le nostre possibilità di vincere praticamente a zero. Questo è stato confermato il 15 dicembre 2022, quando sono stati annunciati i vincitori dell’hackathon, e noi non ne facevamo parte.
Sconfitta
Non nasconderò il fatto che il risultato finale di questo hackathon è stato scoraggiante. Mesi sono stati investiti in questo progetto e avevo una visione importante per questo progetto, poiché pensavo avrebbe fornito uno strumento molto utile ai ricercatori.
Ho uno standard chiaro per i progetti che intraprendo: o hanno successo o falliscono; non c’è una via di mezzo. Quindi questo progetto è stato un fallimento perché non è stato completato entro la scadenza ed è rimasto inaccessibile agli utenti potenziali.
Ma è importante ricordare che il fallimento è una parte naturale della vita. I nostri successi sono costruiti sulle lezioni che apprendiamo dai nostri fallimenti. Sebbene l’esito di questo hackathon sia stato scoraggiante, ha comunque fornito preziose intuizioni quando si tratta di sviluppare e costruire un progetto/prodotto.
Lezioni Apprese
Le principali lezioni che ho tratto da questa esperienza sono state le seguenti:
- Il progetto che abbiamo scelto richiedeva molte funzionalità costruite in anticipo prima di poterci lavorare iterativamente. Cosa intendo con questo? Beh, questo progetto richiedeva che quasi tutti i componenti dell’idea fossero sviluppati prima che potessimo anche solo testarla. Sarebbe stato più sensato scegliere un progetto che avesse meno componenti essenziali per funzionare. Facendo così, avremmo potuto costruire più velocemente i componenti essenziali e poi iterare sul progetto prima. In questo modo, avremmo potuto rispettare la scadenza più facilmente e realizzare un progetto che forse sarebbe stato più semplice ma più completo. YC, un acceleratore per startup tecnologiche, enfatizza che dovresti lanciare rapidamente, parlare con gli utenti e iterare. Avremmo dovuto farlo con il nostro progetto per questo hackathon.
- Abbiamo sottovalutato quanto tempo avrebbe richiesto la costruzione di questo progetto. Questo è stato il nostro primo hackathon e la nostra prima volta a creare un’applicazione decentralizzata (dapp). Non solo, io lavoravo a tempo pieno come ingegnere del software e il mio amico stava completando il suo Master. Eppure, pensavamo che 2 mesi sarebbero stati sufficienti. Sarebbe stato più sensato ridurre la portata del progetto e/o trovare un altro membro del team che potesse ridurre il nostro carico di lavoro.
- Winston Churchill disse famosamente: “La perfezione è il nemico del progresso”. Trattavo questo progetto come un prodotto business-to-customer (B2C), mentre in realtà questo era solo un progetto da hackathon e al massimo un prodotto minimo funzionante (MVP). Quindi, all’inizio, ho sprecato troppo tempo su piccoli dettagli quando avrei dovuto concentrare il mio tempo nel far funzionare sufficientemente le funzionalità core.
Oltre a queste preziose lezioni, ho acquisito nuove competenze che si sono rivelate inestimabili sia nei miei progetti personali sia nelle mie attività professionali. Queste competenze includono:
- Sviluppare API tramite Node.js, JavaScript e Express.js
- Configurare e utilizzare PostgreSQL per la gestione dei dati
- Incorporare PostgreSQL nello sviluppo di API usando pacchetti come PG.
- Utilizzare RSA (crittografia asimmetrica) e AES (crittografia simmetrica) per una maggiore sicurezza dei dati.
Conclusione
Nel complesso, sono contento che abbiamo partecipato a questo hackathon, nonostante la delusione per il risultato finale. Sono grato per le preziose lezioni e competenze che ho acquisito lavorando su Labeler NearBy, in quanto mi hanno reso un sviluppatore migliore e hanno contribuito in modo significativo allo sviluppo del mio prossimo progetto: Notify-Cyber.
Altre Note
- Potrei tornare su Labeler NearBy, ma per il momento questo progetto è in “lunga pausa”
- Attualmente, Labeler NearBy dovrebbe ESSERE ESEGUITO SOLO sulla testnet di NEAR. Ha bisogno di ulteriore sviluppo, test e audit.