Défi des Meilleurs Codeurs des Années 8090
Post LinkedIn Original
Repo GitHub du Projet
Vendredi soir, j’ai vu un post public sur Twitter/X de Chamath Palihapitiya annonçant un défi Top Coder ouvert organisé par sa nouvelle entreprise, 8090 Solutions. Tout le monde pouvait participer. Le défi aurait lieu le lendemain, durerait seulement 8 heures et impliquerait l’ingénierie inverse d’un système hérité en boîte noire en utilisant uniquement des données historiques et quelques interviews d’employés.
J’ai décidé de me lancer !
À la fin de la journée, j’ai eu l’honneur de me classer 7ème sur 425 ingénieurs. Vous pouvez consulter le tableau des leaders ICI et voir le code pour ce défi ICI. Mais, je ne vais pas mentir, j’espérais honnêtement juste finir quelque chose dans ce court laps de temps, donc faire partie du tableau des leaders a été une surprise et une grande victoire personnelle pour moi.
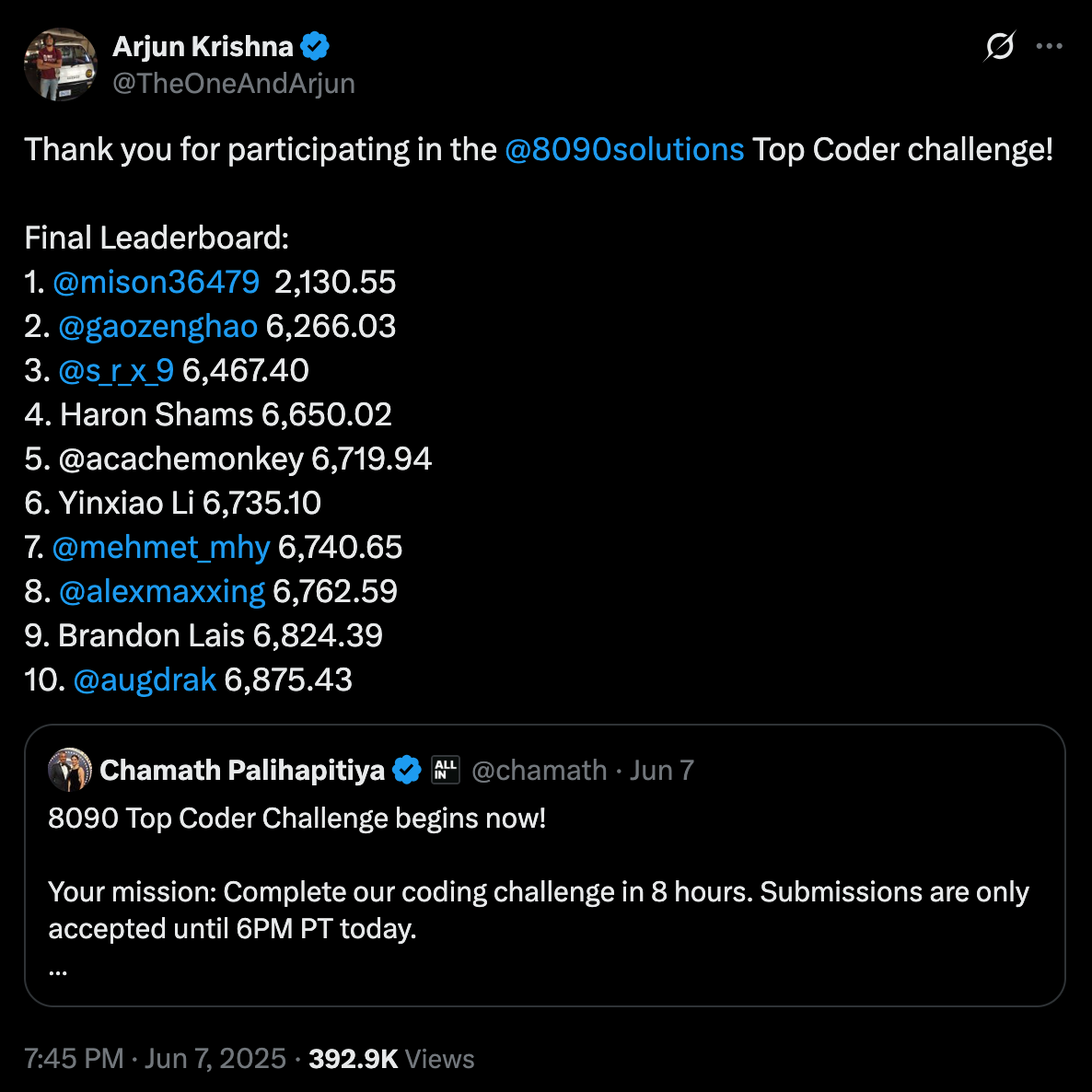
Le défi était en solo, et l’objectif était de reproduire un système de remboursement de voyage en boîte noire vieux de 60 ans qui n’avait pas de code source et pas de documentation. Nous avons reçu quelques artefacts, y compris un bref produit, des transcriptions d’interviews d’employés et un ensemble de données publiques contenant 1 000 exemples historiques d’entrées et de sorties attendues. À partir de cela, je devais déduire la logique commerciale derrière le calcul des montants de remboursement et mettre en œuvre une version moderne qui pourrait produire les mêmes résultats aussi près que possible. Les soumissions étaient évaluées sur un ensemble de données cachées séparées qui contenaient 5 000 cas de test au lieu des 1 000 d’origine. Cet ensemble privé plus grand est ce qui a finalement déterminé votre score final et votre classement. Le système de notation récompensait l’exactitude, où un score plus bas signifiait que votre solution correspondait plus étroitement au comportement caché du système original.
Pour aborder l’incertitude et les motifs dans les données, j’ai utilisé des techniques d’apprentissage automatique classiques aux côtés d’heuristiques de base et de logique programmatique. C’était un mélange soigneux d’analyse de données, de modélisation de caractéristiques et d’approximation de règles basées sur des indices imparfaits.
Voici mon score eval pour l’ensemble de données public de 1 000 :
✅ Résumé de l'Évaluation
------------------------
Total des cas : 1000
Correspondances exactes (<$0.01) : 0
Correspondances proches (<$1.00) : 17
Erreur moyenne : 31,15 $
Score : 3214,93
Développer une solution à un tel défi en 8 heures aurait été presque impossible sans l’aide d’outils alimentés par l’IA qui ont facilité l’exploration, l’intégration et le test rapides des idées.
On aurait dit une archéologie logicielle combinée à un sprint de codage en direct. C’est sans doute l’un des défis techniques les plus intenses et gratifiants que j’ai réalisés.
Merci à Chamath Palihapitiya et Arjun Krishna d’avoir organisé un défi aussi créatif et inspirant.
Liens :