Prédire les Actions Humaines
Détails
Ce projet était le projet #3 pour le cours de Robotique Centrée sur l’Homme (CSCI473) de Dr. Zhang à l’École des Mines du Colorado pendant le semestre de printemps 2020. Il a été conçu pour fournir une introduction à l’apprentissage automatique en robotique grâce à l’utilisation de Machines à Vecteurs de Support (SVM). Les livrables/description du projet original peuvent être consultés ici.
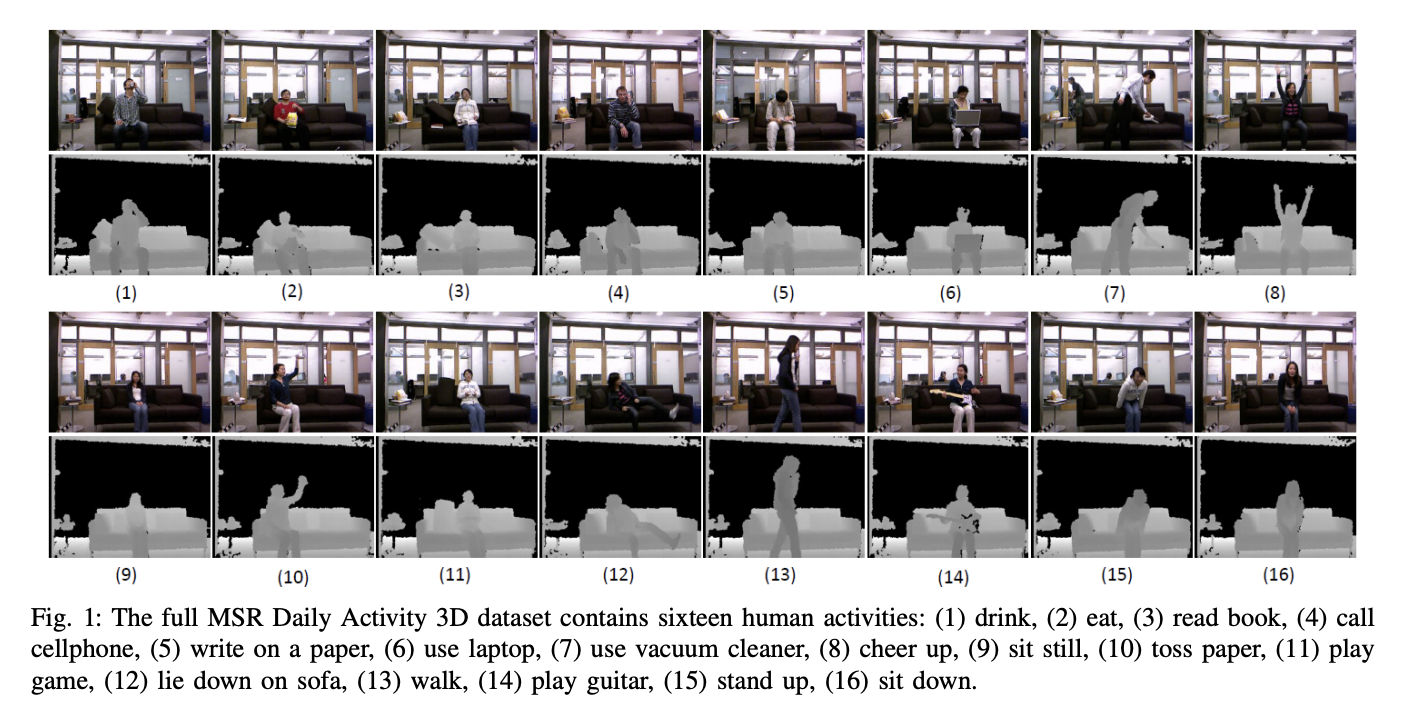
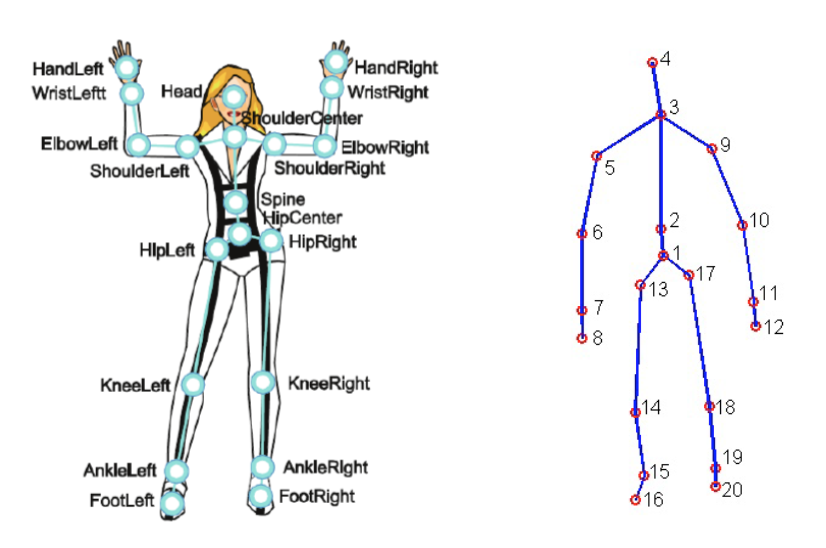
Pour ce projet, le Jeu de Données d’Activités Quotidiennes MSR 3D (Figure 2), avec quelques modifications, a été utilisé. Ce jeu de données contient 16 activités humaines recueillies à partir d’un capteur Xbox Kinetic et stockées sous forme de squelettes. Les squelettes sont un tableau de coordonnées réelles (x, y, z) de 20 articulations d’un humain enregistrées dans un cadre. Voici une figure qui montre ce qu’est un squelette :
Pour réaliser la prédiction des actions humaines, les données brutes doivent être représentées sous une forme pouvant être traitée par un SVM. Pour ce projet, les représentations suivantes ont été utilisées :
- Représentation des Angles et Distances Relatifs (RAD)
- Représentation de l’Histogramme des Différences de Position des Articulations (HJPD)
Pour la classification, la ou les représentations sont envoyées dans un SVM, alimenté par LIBSVM, pour créer un modèle capable de prédire les actions humaines. Deux modèles seront créés, l’un utilisant RAD et l’autre utilisant HJPD. L’objectif est de rendre ces modèles aussi précis que possible et de voir quelle représentation fonctionne le mieux.
Sachant cela, voici un aperçu de ce que fait le code :
- Charger les données brutes du jeu de données modifié
- Supprimer toute donnée aberrante et/ou erronée du jeu de données chargé
- Convertir les données brutes finales en représentations RAD et HJPD
- Les représentations sont envoyées dans des SVM réglés pour générer deux modèles
- Les deux modèles sont ensuite alimentés avec des données brutes de test et une matrice de confusion est générée pour mesurer comment les modèles ont performé.
Résultats
Après avoir exécuté le code et réglé les modèles du mieux que je pouvais, voici la matrice de confusion finale pour les modèles RAD et HJPD :
Représentation : RAD
Précision : 62.5%
Classification LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
Numéro d'Activité Réelle
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Représentation : HJPD
Précision : 70.83%
Classification LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
Numéro d'Activité Réelle
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Conclusion
Étant donné que les deux précisions sont supérieures à 50%, ce projet a été un succès. De plus, la représentation HJPD semble être la représentation la plus précise à utiliser pour ces classifications. Avec cela, il y a un ou des modèles qui prédisent les actions humaines en utilisant des données de squelette. Les modèles ici sont loin d’être parfaits mais ils sont meilleurs que le hasard. Ce projet a donné naissance au projet Moving Pose par la suite.
Notes Supplémentaires :
- Ce projet a été testé sur Python version 3.8.13
- Pour ce projet, le jeu de données MDA3 complet et un jeu de données MDA3 modifié sont utilisés. Le MDA3 modifié ne contient que les activités 8, 10, 12, 13, 15, et 16. De plus, la version modifiée a quelques points de données “corrompus” alors que le jeu de données complet n’en a pas.
- Représentation Spatio-Temporelle des Personnes Basée sur des Données Squelettiques 3D : Une Revue
- YouTube : Comment le Capteur de Profondeur Kinect Fonctionne en 2 Minutes
- Medium : Comprendre les Articulations et le Système de Coordonnées du Kinect V2
- Page Wikipedia Kinect
- Jameco Xbox Kinect
- Informations sur SVM et LibSVM : cjlin libsvm, page pypi libsvm, & libsvm github
- Logique et Documentation SVM & LIBSVM : papier guide cjlin & datasets libsvmtools cjlin
- Informations sur le Jeu de Données Utilisé/Modifié