Création de Labeler NearBy
Table of Contents

Mon Premier Hackathon
Au cours des dernières parties de l’été 2022, je voulais vraiment travailler sur un projet passionnant. Je venais de terminer mon diplôme de premier cycle et je travaillais à temps plein en tant qu’ingénieur logiciel. Je voulais vraiment m’engager dans un projet secondaire et à l’époque, j’avais suffisamment de temps libre pour le faire. Je ne savais vraiment pas sur quoi travailler, jusqu’à ce que je découvre un site web appelé Devpost en août 2022. Devpost est un site web qui héberge des compétitions de logiciels appelées hackathons. En parcourant Devpost, j’ai découvert un hackathon appelé NEAR MetaBUILD III qui était un hackathon organisé par l’organisation NEAR Protocol.
Qu’est-ce que NEAR ?
Le NEAR Protocol est une blockchain qui prend en charge les contrats intelligents et la cryptomonnaie NEAR. Il est principalement connu pour avoir des frais de transition très bas, prendre en charge les contrats intelligents, avoir son propre réseau de test officiel et un excellent environnement de développement en raison du fait que vous pouvez écrire des contrats intelligents en Rust et/ou JavaScript. Vous pouvez obtenir un meilleur aperçu du NEAR Protocol grâce à la vidéo incroyable de CoinGecko :
Pendant ce temps, Coinbase a officiellement commencé à prendre en charge le NEAR Protocol en tant que monnaie négociable sur leur plateforme. Ce qui était un gros problème car Coinbase est connu pour être très sélectif en ce qui concerne les monnaies qu’ils prennent en charge sur leur plateforme. Cela a aidé à rendre NEAR une plateforme plus fiable. Vous pouvez toujours échanger NEAR sur Coinbase à ce jour.
Pourquoi S’engager ?
Après avoir passé un certain temps à réfléchir, j’ai décidé de consacrer mon temps à participer au hackathon NEAR MetaBUILD III. Mon raisonnement était le suivant :
- La crypto ne disparaît pas et est une technologie qui restera. Il était donc logique d’investir du temps pour apprendre cette technologie.
- Le hackathon offrait de grandes récompenses, allant de 20 000 $ à 100 000 $ en NEAR si vous étiez l’un des gagnants.
- Le hackathon avait une date limite spécifique, ce qui signifie que le projet ne pouvait pas être prolongé pendant des mois comme beaucoup de projets secondaires le sont généralement.
- Le projet serait une excellente expérience d’apprentissage et une excellente introduction aux hackathons.
- Dans le pire des cas, le hackathon me permettrait de créer un excellent projet à montrer sur mon CV.
Avec tout cela en tête, j’ai appelé mon ami proche de l’université le 26 août 2022 et nous avons commencé à planifier ce hackathon. Le hackathon devait commencer le 23 septembre 2023 et se terminer le 21 novembre 2022. Bien que la date limite ait été prolongée jusqu’au 24 novembre 2023 vers la fin du hackathon. Comme nous étions un mois en avance, nous avons décidé de passer ce temps à apprendre et à réfléchir à ce sur quoi nous travaillerions pour ce hackathon de 2 mois. Au cours de ce premier mois, nous avons obtenu un aperçu général de la crypto et des blockchains. Nous avons examiné et pratiqué sur le testnet de NEAR, examiné le SDK de NEAR et déployé quelques contrats intelligents.
L’Idée
Après avoir obtenu une excellente introduction à tout ce qui concerne la blockchain et NEAR, nous avons commencé à réfléchir à des idées. Je voulais que ce projet soit quelque chose qui ne soit pas juste un “projet de hackathon”, mais quelque chose qui pourrait devenir un produit que d’autres pourraient utiliser et servir d’exemple de la façon dont la crypto pourrait être utile pour des choses en dehors du simple trading.
Avec cela en tête, nous avons initialement décidé de créer quelque chose de similaire à l’Unreal Engine Blueprint, mais pour la création et le déploiement faciles de contrats intelligents sur la blockchain NEAR sans avoir besoin de coder. Cependant, une semaine avant le début du hackathon, nous avons abandonné l’idée car cela n’avait tout simplement pas de sens. Pourquoi quelqu’un se donnerait-il la peine d’utiliser notre outil pour créer des contrats intelligents NEAR s’il n’y avait pas encore de cas d’utilisation pratique pour eux ? Ce serait comme développer un outil dont beaucoup de gens n’avaient pas besoin.
Avec seulement une semaine avant le début du hackathon, nous avons recommencé à réfléchir et nous nous sommes arrêtés sur cette idée :
Une plateforme décentralisée où les chercheurs en IA peuvent externaliser
le marquage de données à des marqueurs du monde entier
Nous avons nommé le projet “Labeler NearBy”. Notre décision de choisir cette idée était basée sur les raisons suivantes :
- Le développement de l’IA nécessite un marquage humain des données pour l’entraînement.
- Trouver et gérer des individus qualifiés pour marquer des ensembles de données spécifiques est un défi.
- L’idée a déjà été mise en œuvre avec succès par une entreprise appelée Scale AI, comme en témoigne la façon dont ils ont trouvé un ajustement produit-marché.
- Les services centralisés comme Scale AI posent des préoccupations car les organisations doivent envoyer leurs données à l’entreprise de marquage, qui externalise ensuite des marqueurs humains à l’échelle mondiale. Après le processus de marquage, l’entreprise renvoie les données marquées à l’organisation. Cela abandonne le contrôle sur des données d’entraînement précieuses, qui pourraient être utilisées par l’entreprise de marquage pour entraîner ses propres modèles. Décentraliser ce service semblait être une solution logique.
- Nous avons trouvé très peu de projets dans l’espace des applications décentralisées (dApp) travaillant sur cette idée, offrant une opportunité pour nous d’innover et de pionnier dans ce domaine.
Pour aider à réduire la complexité, nous avons décidé que Labeler NearBy ne prendrait en charge que les données d’image pour le moment.
Soumission
Avec l’idée choisie et le hackathon officiellement en cours, mon ami et moi avons commencé à construire Labeler NearBy. Nous avons travaillé sur notre projet pendant 2 mois jusqu’à ce que nous soumettions le brouillon final de notre projet à Devpost le 24 novembre 2022. Nous avons soumis notre projet sur Devpost et avons également créé une copie de notre soumission sur Github. Ce blog ne couvre pas tous les aspects techniques et le processus de développement de Labeler NearBy. Sachant cela, pour en savoir plus sur le fonctionnement de Labeler NearBy ou pour voir notre soumission finale, veuillez visiter l’un des liens suivants :
Labeler NearBy se compose de deux bases de code : ln-researcher et ln-labeler. Ces bases de code sont complètement open source sous la licence MIT et peuvent être consultées via les liens suivants :
Voici un aperçu général de la façon dont Labeler NearBy (LN) fonctionnerait :
Un chercheur a besoin d’images marquées pour entraîner son modèle d’IA. Pour ce faire, le chercheur utilise LN pour héberger ses données et fournir un moyen aux marqueurs de marquer ses données. Cela se fait grâce à ln-researcher, un service web auto-hébergé qui se compose d’une API, des contrats intelligents du chercheur et d’une base de données Postgres locale. Pour le marqueur, un frontend web est (aurait été) fourni, leur permettant d’accéder et de marquer les images du chercheur. Pendant le processus de marquage, une image est marquée trois fois par différents marqueurs. Seul le marqueur avec les meilleures étiquettes, déterminé par un système de vote, est récompensé par des pièces NEAR. L’application web responsable de ce processus s’appelle ln-labeler. Le chercheur finance chaque opération de marquage, et les pièces NEAR peuvent être facilement converties en dollars via Coinbase. Toute la logistique des transactions est gérée par des contrats intelligents hébergés sur la blockchain NEAR Protocol.
Vous pouvez visionner notre vidéo de démonstration de Labeler NearBy pour le hackathon ici :
Plus Grande Réalisation
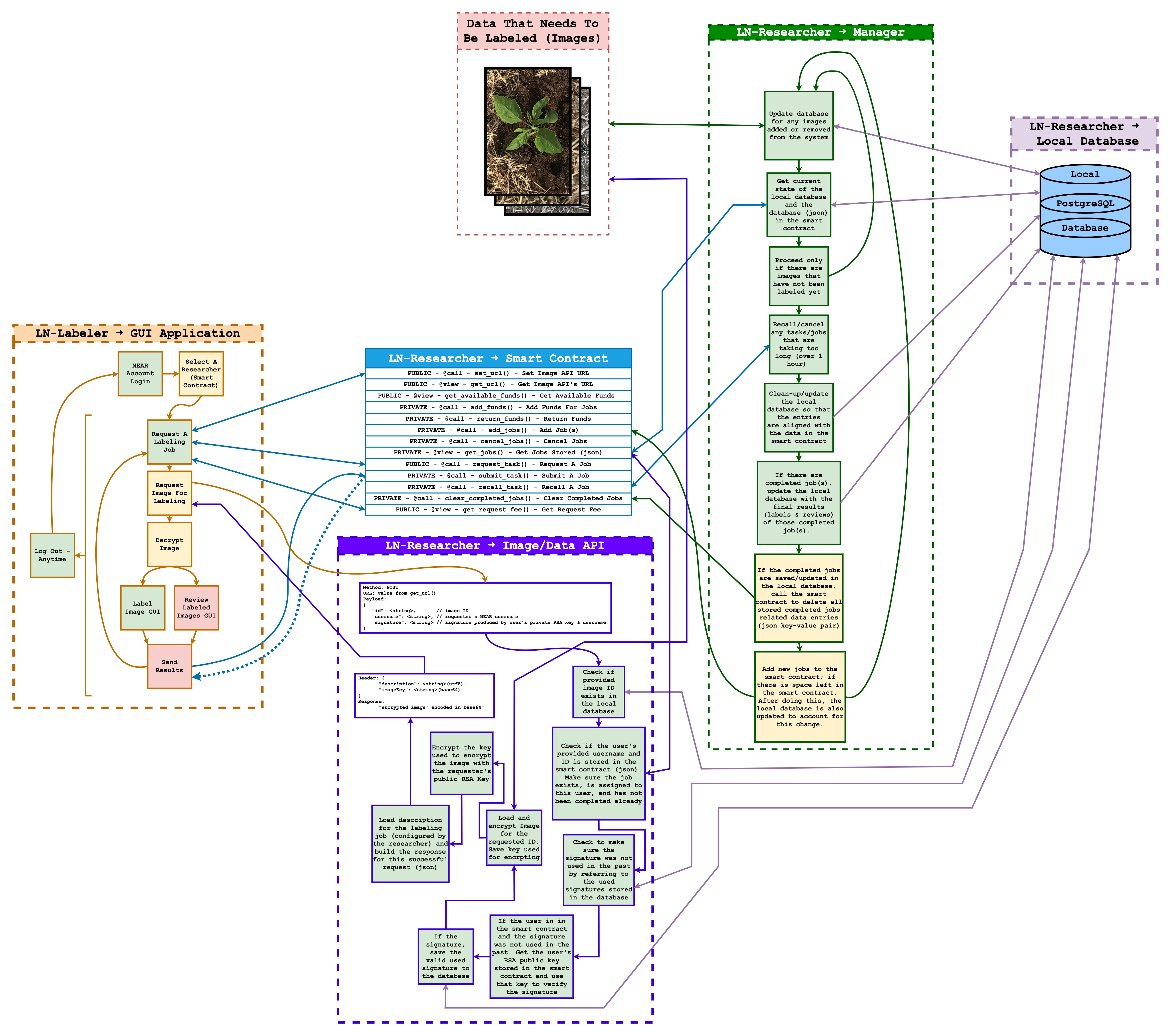
La fonctionnalité dont je suis le plus fier d’avoir mise en œuvre est une fonction appelée getImage(). Cette fonction sert de point de terminaison API dans ln-researcher et joue un rôle crucial dans le pipeline de données entre les chercheurs et les marqueurs dans Labeler NearBy (LN).
Ce point de terminaison API permet aux chercheurs de distribuer leurs images de manière sécurisée et fiable pour le marquage. Les missions de marquage sont gérées via des contrats intelligents NEAR sur la blockchain NEAR Protocol tandis que les données d’image sont hébergées par le chercheur via ln-researcher.
Le point de terminaison effectue une série de vérifications de sécurité pour s’assurer que seul le marqueur assigné peut accéder à l’image. Cela inclut la vérification de la signature de la demande et la vérification du contrat intelligent associé pour confirmer l’existence de la tâche et son attribution au marqueur demandant.
Une fois la demande validée dans l’API auto-hébergée ln-researcher du chercheur, la fonction récupère l’image de la base de données Postgres locale, crypte l’image et la livre au marqueur autorisé qui peut ensuite déchiffrer l’image pour le marquage. Simultanément, la fonction met à jour le statut de l’image dans la base de données, indiquant l’avancement du marquage de l’image. Tout au long de ce processus, des clés RSA des deux parties, chercheur et marqueur, sont utilisées pour authentifier. Pendant ce temps, le chiffrement AES est utilisé pour crypter l’image.
Ce point de terminaison joue un rôle critique dans la gestion de la distribution sécurisée et contrôlée des images des chercheurs aux marqueurs. Il garantit un transfert de données sécurisé et suit et gère efficacement le processus de marquage des images. De plus, ce processus a le potentiel d’éliminer le besoin d’utiliser HTTPS, du moins pour ce point de terminaison.
Ce point de terminaison/fonction spécifique a été testé et prouvé fonctionnel. Ci-dessous se trouve un diagramme illustrant la fonctionnalité globale de Labeler NearBy, y compris une représentation claire de la façon dont le point de terminaison/fonction susmentionné fonctionne :
Résultat
Malheureusement, la triste réalité est que nous n’avons pas pu terminer complètement ce projet avant la date limite du hackathon. La plupart du projet a été complété, comme le ln-researcher, mais le frontend (ln-labeler) n’a pas été terminé et nous n’avons pas pu déployer de démo en direct. Bien que le backend (ln-researcher) ait été essentiellement terminé, sans frontend fonctionnel et sans démo en direct, personne n’a pu essayer l’idée de Labeler NearBy. Non seulement cela, mais les juges n’ont pas pu essayer le projet et ont dû lire la soumission, passer en revue le code et/ou essayer de l’exécuter eux-mêmes. Ce qui a fait que nos chances de gagner sont tombées à pratiquement zéro pour cent. Cela a été confirmé le 15 décembre 2022 lorsque les gagnants du hackathon ont été annoncés, et nous n’étions pas parmi eux.
Perdre
Je ne cacherai pas le fait que le résultat final de ce hackathon était décourageant. Des mois ont été investis dans ce projet et j’avais une grande vision pour ce projet car je pensais qu’il fournirait un outil très utile aux chercheurs.
J’ai un standard clair pour les projets que j’entreprends : soit ils réussissent, soit ils échouent ; il n’y a pas de terrain d’entente. Donc ce projet était un échec car il n’a pas été entièrement terminé avant la date limite et est resté inaccessible aux utilisateurs potentiels.
Mais il est important de se rappeler que l’échec est une partie naturelle de la vie. Nos succès sont construits sur les leçons que nous tirons de nos échecs. Bien que le résultat de ce hackathon ait été décourageant, il a tout de même fourni des informations précieuses en ce qui concerne le développement et la construction d’un projet/produit.
Leçons Apprises
Les principales leçons que j’ai tirées de cette expérience sont les suivantes :
- Le projet que nous avons choisi nécessitait beaucoup de fonctionnalités construites à l’avance avant que nous puissions itérer dessus. Que veux-je dire par là ? Eh bien, ce projet nécessitait que presque tous les composants de l’idée soient construits avant que nous puissions même tester l’idée. Il aurait été plus logique de choisir un projet qui avait moins de composants essentiels pour fonctionner. Ce faisant, nous aurions pu construire les composants essentiels plus rapidement puis itérer sur le projet plus tôt. Ce faisant, nous aurions pu respecter la date limite plus facilement et réaliser un projet qui aurait pu être plus simple mais plus complet. YC, un accélérateur de startups technologiques, souligne que vous devriez lancer rapidement, parler avec les utilisateurs et itérer. Nous aurions dû faire cela avec notre projet pour ce hackathon.
- Nous avons sous-estimé combien de temps ce projet allait prendre à construire. C’était notre premier hackathon et notre première fois à créer une application décentralisée (dapp). Non seulement cela, mais je travaillais à temps plein en tant qu’ingénieur logiciel et mon ami terminait son Master. Pourtant, nous pensions que 2 mois seraient suffisants. Il aurait été plus logique de réduire la portée du projet et/ou de trouver un membre d’équipe supplémentaire qui aurait pu réduire notre charge de travail.
- Winston Churchill a déclaré célèbrement : “La perfection est l’ennemi du progrès”. Je traitais ce projet comme un produit de consommation (B2C), alors qu’en réalité, c’était juste un projet de hackathon et au maximum un produit minimum viable (MVP). Donc, au début, j’ai perdu trop de temps sur des petits détails alors que j’aurais dû me concentrer sur le fait de faire fonctionner les fonctionnalités essentielles de manière suffisante.
En plus de ces leçons précieuses, j’ai acquis de nouvelles compétences qui se sont révélées inestimables tant dans mes projets personnels que dans mes efforts professionnels. Ces compétences incluent :
- Développer des API avec Node.js, JavaScript et Express.js
- Configurer et utiliser PostgreSQL pour la gestion des données
- Incorporer PostgreSQL dans le développement d’API en utilisant des packages comme PG.
- Utiliser RSA (cryptographie asymétrique) et AES (cryptographie symétrique) pour une sécurité des données améliorée.
Conclusion
Dans l’ensemble, je suis heureux que nous ayons participé à ce hackathon, malgré ma déception face au résultat final. Je suis reconnaissant pour les leçons précieuses et les compétences que j’ai acquises en travaillant sur Labeler NearBy, car elles m’ont rendu meilleur développeur et ont contribué de manière significative au développement de mon prochain projet : Notify-Cyber.
Autres Remarques
- Je pourrais revenir à Labeler NearBy, mais pour le moment, ce projet est en “longue pause”.
- Actuellement, Labeler NearBy ne devrait fonctionner QUE sur le testnet de NEAR. Il nécessite un développement, des tests et un audit supplémentaires.