Marketing ABM avec InsightRed
![]()
À propos
InsightRed est un outil de Marketing Basé sur le Compte (ABM) alimenté par LLM qui extrait les derniers commentaires Reddit des Subreddits, triés par “Chauds”, et identifie les utilisateurs qui montrent un intérêt potentiel pour votre projet ou produit. Il vous aide à identifier et cibler des utilisateurs de grande valeur sur Reddit pour obtenir vos premiers utilisateurs pour votre produit/projet. Ce projet a été construit pour le ANARCHY Hackathon d’octobre 2023.
Annonce(s)
19 octobre 2023
En tant que suite à ce projet, je suis ravi d’annoncer que nous avons remporté la 1ère place au Hackathon d’octobre 2023 d’Anarchy !
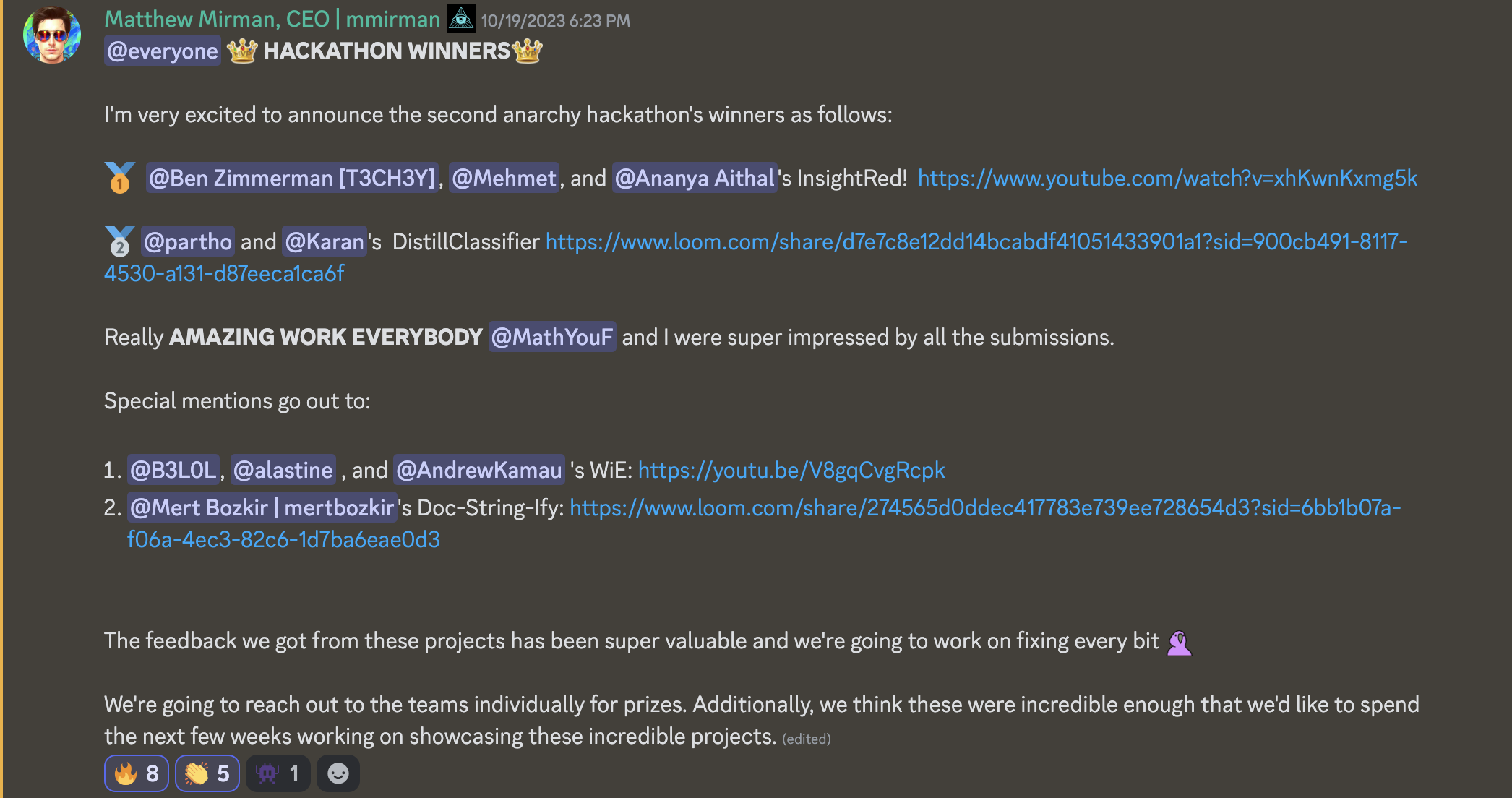
Cliquez ici pour voir le message en mode TEXTE (modifié en raison du formatage de Discord)
@everyone **👑 HACKATHON 👑**
Je suis très heureux d'annoncer les gagnants du deuxième hackathon d'anarchie comme suit :
🥇 "@Ben Zimmerman [T3CH3Y]", @Mehmet, et "@Ananya Aithal"'s InsightRed! https://www.youtube.com/watch?v=xhKwnKxmg5k
🥈 @partho et @Karan's DistillClassifier https://www.loom.com/share/d7e7c8e12dd14bcabdf41051433901a1?sid=900cb491-8117-4530-a131-d87eeca1ca6f
Vraiment **UN TRAVAIL INCROYABLE TOUT LE MONDE** @MathYouF et j'ai été super impressionné par toutes les soumissions.
Des mentions spéciales vont à :
1. @B3LOL, @alastine, et @AndrewKamau 's WiE: https://youtu.be/V8gqCvgRcpk
2. "@Mert Bozkir | mertbozkir"'s Doc-String-Ify: https://www.loom.com/share/274565d0ddec417783e739ee728654d3?sid=6bb1b07a-f06a-4ec3-82c6-1d7ba6eae0d3
Les retours que nous avons reçus de ces projets ont été super précieux et nous allons travailler à corriger chaque détail 🦜
Nous allons contacter les équipes individuellement pour les prix. De plus, nous pensons que ces projets étaient suffisamment incroyables pour que nous souhaitions passer les prochaines semaines à les mettre en valeur.
Démo
Composants d’InsightRed
🧩 Collecteur
Le Collecteur collecte les derniers posts Reddit et les commentaires de ces posts, pour un Subreddit donné, en utilisant l’API de Reddit. Après la collecte, le collecteur enregistre les données collectées dans une base de données SQLite locale. Cela est facilité par l’utilisation du package python praw pour aider à utiliser l’API Reddit et SQLAlchemy pour effectuer des opérations CRUD dans la base de données SQLite locale.
🧩 Vectoriseur
Le Vectoriseur vérifie la base de données SQLite locale pour voir quels commentaires n’ont pas été enregistrés dans la base de données vectorielle. Après avoir obtenu une liste de commentaires, il crée un embedding du post+commentaire en utilisant le modèle “text-embedding-ada-002” d’OpenAI. Cet embedding est utilisé comme un Index dans la base de données vectorielle et certaines métadonnées, sous forme de JSON, sont également créées. L’Index et les métadonnées sont ensuite téléchargés dans la base de données vectorielle, qui dans ce cas est Pinecone (basé sur le cloud). Après avoir été téléchargé, la base de données SQLite locale est mise à jour pour éviter de re-télécharger les mêmes données dans Pinecone. Tout cela est réalisé en utilisant le client python de Pinecone (pinecone-client) pour effectuer des options CRUD dans la base de données vectorielle et LangChain pour gérer le processus d’embedding.
🧩 Interface
L’interface est ce qui est utilisé par l’utilisateur pour interagir avec l’outil. Dans ce cas, l’interface est une CLI. L’interface a une implémentation de Génération Augmentée par Récupération (RAG). Où l’utilisateur fournit une description de son produit, une liste de Subreddits à vérifier, ainsi que quelques filtres. Dans ce contexte, le Collecteur est appelé puis le Vectoriseur est appelé. Après que ces deux services aient terminé le traitement, la description du produit saisie est utilisée pour effectuer une recherche similaire dans la base de données vectorielle. Les meilleurs résultats et la description du produit sont ensuite alimentés dans un modèle de prompt qui crée le prompt final. Le prompt final est ensuite envoyé au modèle GPT-4 d’OpenAI et les résultats finaux sont ensuite présentés à l’utilisateur. Ces résultats seront une liste de tous les commentaires Reddit qui suggèrent fortement que l’utilisateur Reddit serait intéressé par le produit fourni, basé sur sa description. Ce composant fonctionne en utilisant les commentaires du Collecteur et du Vectoriseur, ainsi qu’en utilisant le LLM-VM d’Anarchy pour gérer les requêtes au modèle GPT-4 d’OpenAI.
Membres de l’équipe
Crédit extérieur notable
casta (Hacker News)
Fournissant l’inspiration pour ce projet à travers leur post HN. Comme leur solution n’était pas open-source, j’ai été motivé à créer une version open-source (ce projet).
ChatGPT (GPT-4)
A été très utile pour le développement en accélérant vraiment le cycle de développement. Et il a généré le logo du projet et la miniature YouTube en utilisant le nouveau modèle DALL-E 3 d’OpenAI.
James Briggs (YouTuber)
La vidéo de James a vraiment expliqué comment utiliser l’API de Reddit ainsi que comment implémenter un pipeline RAG de base en utilisant Python.
Sources
- Show HN: Projet amusant de la fête du Travail, Trouver des commentaires Reddit pour promouvoir votre entreprise
- Documentation d’aperçu de l’indexation Pinecone
- YouTube: Chatbots avec RAG - Guide complet de LangChain
- Page API d’OpenAI
- Documentation de démarrage rapide de Pinecone
- Reddit: Limites de taux mises à jour entrant en vigueur dans les semaines à venir
- Page des applications Reddit
- YouTube: Comment utiliser l’API Reddit en Python
- Medium: Scraping des données Reddit en utilisant l’API Reddit
- Gist GitHub: API Reddit
- GitHub: praw
- ChatGPT - Application Web