Desafío Top Coder de 8090
Publicación original de LinkedIn
Repositorio de GitHub del proyecto
El viernes por la noche, vi una publicación pública en Twitter/X de Chamath Palihapitiya anunciando un Top Coder Challenge abierto organizado por su nueva empresa, 8090 Solutions. Cualquiera podía unirse. El desafío tendría lugar al día siguiente, duraría solo 8 horas y consistiría en la ingeniería inversa de un sistema heredado de caja negra usando solo datos históricos y algunas entrevistas con empleados.
¡Decidí participar!
Al final del día, tuve el honor de quedar en el 7.º de 425 ingenieros. Puedes consultar la tabla de clasificación AQUÍ y ver el código de este desafío AQUÍ. Pero, no mentiré, honestamente solo esperaba terminar algo dentro de ese corto período de tiempo, así que aparecer en la tabla de clasificación fue una sorpresa y una gran victoria personal para mí.
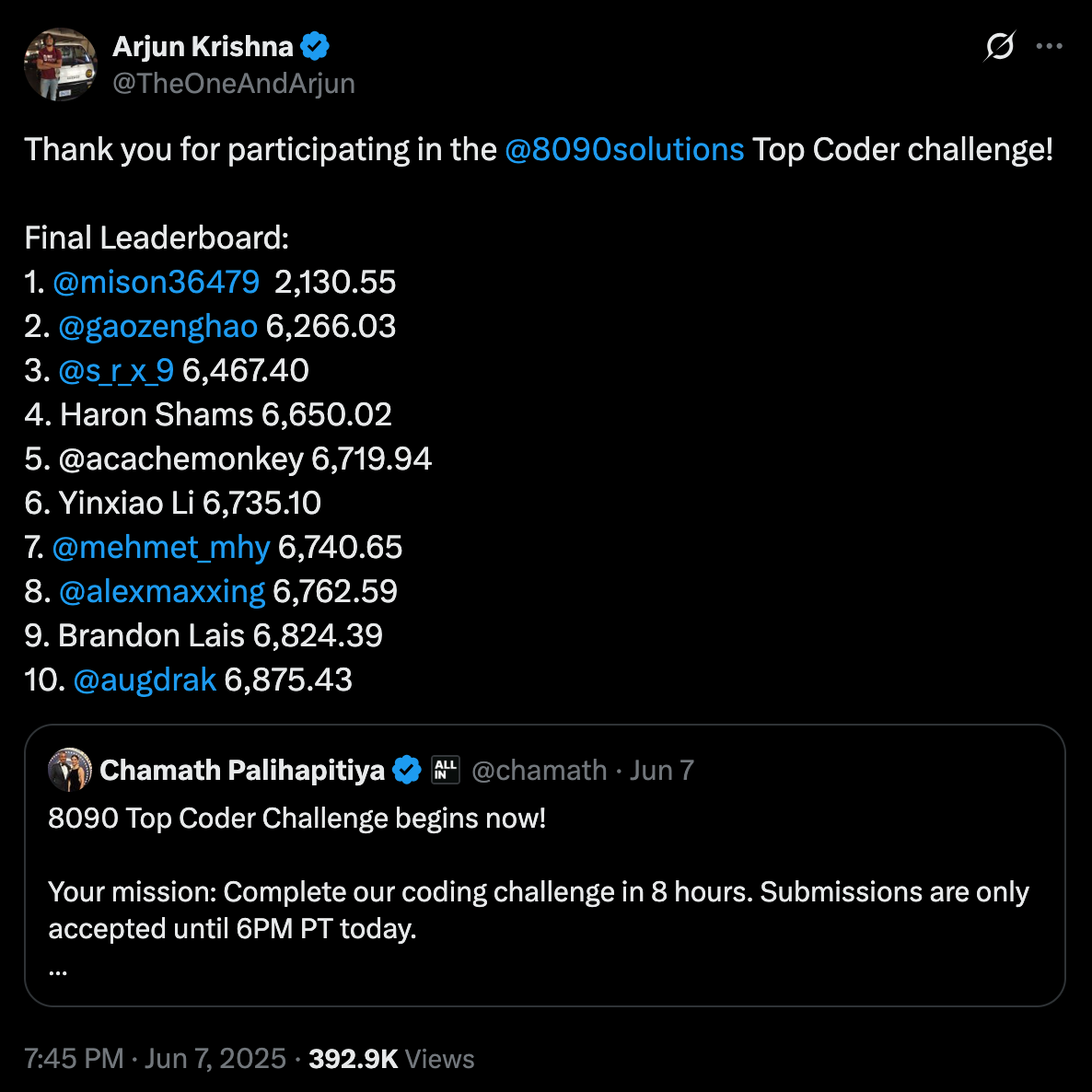
El desafío era individual, y el objetivo era replicar un sistema de reembolso de viajes de caja negra de 60 años que no tenía código fuente ni documentación. Se nos dieron algunos artefactos, incluyendo un resumen del producto, transcripciones de entrevistas con empleados y un conjunto de datos público que contenía 1 000 ejemplos históricos de entradas y salidas esperadas. A partir de eso, tuve que inferir la lógica de negocio detrás de cómo se calculaban los montos de reembolso e implementar una versión moderna que pudiera producir los mismos resultados lo más precisamente posible. Las presentaciones fueron evaluadas en un conjunto de datos oculto separado que contenía 5 000 casos de prueba en lugar de los 1 000 originales. Este conjunto privado más grande fue lo que finalmente determinó tu puntuación final y clasificación. El sistema de puntuación premiaba la precisión, donde una puntuación más baja significaba que tu solución coincidía más estrechamente con el comportamiento oculto del sistema original.
Para abordar la incertidumbre y los patrones en los datos, utilicé técnicas clásicas de aprendizaje automático junto con heurísticas básicas y lógica programática. Fue una combinación cuidadosa de análisis de datos, modelado de características y aproximación de reglas basadas en pistas imperfectas.
Este fue mi puntaje eval para el conjunto de datos público de 1 000:
✅ Evaluation Summary
------------------------
Total cases : 1000
Exact matches (<$0.01): 0
Close matches (<$1.00): 17
Average error : $31.15
Score : 3214.93
Desarrollar una solución para un desafío así en 8 horas habría sido casi imposible sin la ayuda de herramientas impulsadas por IA que facilitaron explorar, integrar y probar ideas rápidamente.
Se sintió como arqueología de software combinada con una sprint de codificación en vivo. Fácilmente uno de los desafíos técnicos más intensos y gratificantes que he realizado.
Gracias a Chamath Palihapitiya y Arjun Krishna por organizar un desafío tan creativo e inspirador.
Enlaces: