Predicción de Acciones Humanas
Repositorio de GitHub del Proyecto
Detalles
Este proyecto fue el proyecto #3 para la clase de Robótica Centrada en el Humano (CSCI473) del Dr. Zhang en la Escuela de Minas de Colorado durante el semestre de Primavera de 2020. Fue diseñado para proporcionar una introducción al aprendizaje automático en robótica a través del uso de Máquinas de Vectores de Soporte (SVM). Los entregables/descripción originales del proyecto se pueden ver aquí.
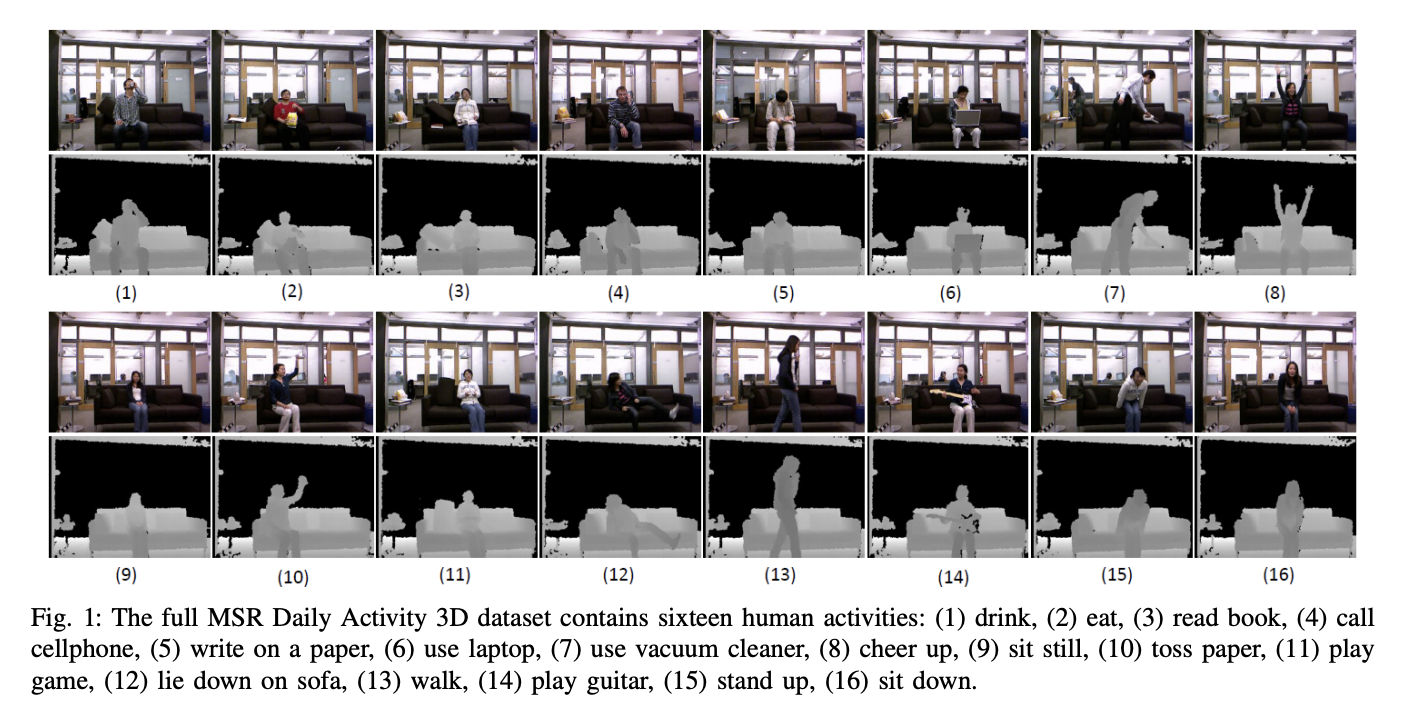
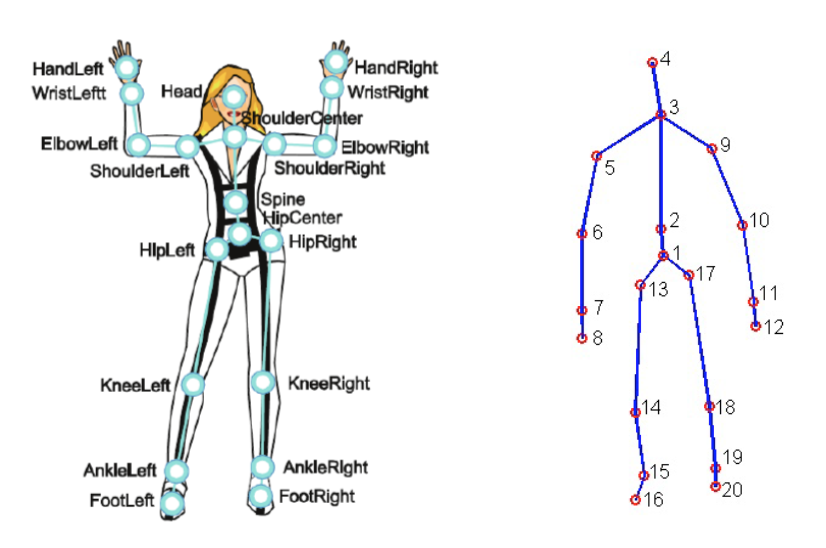
Para este proyecto se utilizó el Conjunto de Datos de Actividades Diarias MSR 3D (Figura 2), con algunas modificaciones. Este conjunto de datos contiene 16 actividades humanas recopiladas de un sensor Xbox Kinetic y almacenadas como esqueletos. Los esqueletos son un arreglo de coordenadas del mundo real, (x, y, z), de 20 articulaciones de un humano registradas en un marco. Aquí hay una figura que muestra qué es un esqueleto:
Para lograr la predicción de acciones humanas, los datos en bruto deben ser representados en una forma que pueda ser procesada por un SVM. Para este proyecto, se utilizaron las siguientes representaciones:
- Representación de Ángulos y Distancias Relativas (RAD)
- Representación de Histograma de Diferencias de Posición de Articulaciones (HJPD)
Para la clasificación, la(s) representación(es) se envían a un SVM, impulsado por LIBSVM, para crear un modelo que pueda predecir acciones humanas. Se crearán dos modelos, uno utilizando RAD y otro utilizando HJPD. El objetivo es hacer que estos modelos sean lo más precisos posible y ver cuál representación funciona mejor.
Sabiendo esto, aquí hay un resumen de lo que hace el código:
- Cargar los datos en bruto del conjunto de datos modificado
- Eliminar cualquier dato atípico y/o erróneo del conjunto de datos cargado
- Convertir los datos en bruto finales en representaciones RAD y HJPD
- Las representaciones se envían a SVM(s) ajustados para generar dos modelos
- Los dos modelos se alimentan con datos en bruto de prueba y se genera una matriz de confusión para medir cómo se desempeñaron el(los) modelo(s).
Resultados
Después de ejecutar el código y ajustar los modelos lo mejor que pude, aquí están las matrices de confusión finales para ambos modelos RAD y HJPD:
Representación: RAD
Precisión: 62.5%
Clasificación LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
Número de Actividad Real
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Representación: HJPD
Precisión: 70.83%
Clasificación LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
Número de Actividad Real
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Conclusión
Dado que ambas precisiones están por encima del 50%, este proyecto fue un éxito. Además, la representación HJPD parece ser la representación más precisa para usar en estas clasificaciones. Con esto, hay un modelo(s) que predice acciones humanas utilizando datos de esqueleto. El(los) modelo(s) aquí están lejos de ser perfectos, pero son mejores que aleatorios. Este proyecto fue lo que dio origen al proyecto Moving Pose más adelante.
Notas Adicionales:
- Este proyecto fue probado en Python versión 3.8.13
- Para este proyecto, se utilizó el conjunto de datos completo MDA3 y un conjunto de datos MDA3 modificado. El MDA3 modificado solo contiene las actividades 8, 10, 12, 13, 15 y 16. Además, la versión modificada tiene algunos puntos de datos “corrompidos” mientras que el conjunto de datos completo no.
- Representación Espacio-Tiempo de Personas Basada en Datos Esqueléticos 3D: Una Revisión
- YouTube: Cómo Funciona el Sensor de Profundidad Kinect en 2 Minutos
- Medium: Entendiendo las Articulaciones y el Sistema de Coordenadas del Kinect V2
- Página de Wikipedia del Kinect
- Jameco Xbox Kinect
- Información Sobre SVM(s) & LibSVM: cjlin libsvm, página de libsvm en pypi, & libsvm github
- Lógica y Documentación de SVM & LIBSVM: papel guía de cjlin & datasets de libsvmtools de cjlin
- Información Sobre El Conjunto de Datos Usado/Modificado