Construyendo Labeler NearBy
Table of Contents

Mi Primer Hackathon
Durante las últimas partes del verano de 2022, realmente quería trabajar en un proyecto emocionante. Acababa de terminar mi licenciatura y estaba trabajando a tiempo completo como ingeniero de software. Realmente quería comprometerme a un proyecto paralelo y en ese momento, tenía suficiente tiempo libre para hacerlo. No sabía en qué trabajar, hasta que descubrí un sitio web llamado Devpost en agosto de 2022. Devpost es un sitio web que alberga competiciones de software llamadas hackathons. Mientras navegaba por Devpost, descubrí un hackathon llamado NEAR MetaBUILD III que fue un hackathon organizado por la organización NEAR Protocol.
¿Qué es NEAR?
El Protocolo NEAR es una blockchain que soporta contratos inteligentes y la criptomoneda NEAR. Es principalmente conocido por tener tarifas de transacción muy bajas, soportar contratos inteligentes, tener su propia red de prueba oficial y un gran entorno para desarrolladores debido al hecho de que puedes escribir contratos inteligentes en Rust y/o Java Script. Puedes obtener una mejor visión general del Protocolo NEAR a través del increíble video de CoinGecko:
Durante este tiempo, Coinbase comenzó a soportar oficialmente el Protocolo NEAR como una moneda negociable en su plataforma. Lo cual fue un gran acontecimiento porque Coinbase es conocido por ser muy selectivo en cuanto a qué monedas apoyan en su plataforma. Esto ayudó a hacer de NEAR una plataforma más confiable. Aún puedes negociar NEAR en Coinbase hasta el día de hoy.
¿Por qué Comprometerse?
Después de pasar un tiempo pensando, decidí comprometer mi tiempo a competir en el hackathon NEAR MetaBUILD III. Mi razonamiento fue el siguiente:
- La criptografía no va a desaparecer y es una tecnología que se quedará. Así que tenía sentido invertir algo de tiempo en aprender la tecnología.
- El hackathon tenía grandes recompensas, entre $20,000 y $100,000 en NEAR si eras uno de los ganadores.
- El hackathon tenía una fecha límite específica, lo que significaba que el proyecto no podría extenderse durante meses como muchos proyectos paralelos suelen ser.
- El proyecto sería una gran experiencia de aprendizaje y una gran introducción a los hackathons.
- En el peor de los casos, el hackathon me permitiría hacer un gran proyecto para mostrar en mi currículum.
Con todo esto en mente, llamé a mi amigo cercano de la universidad el 26 de agosto de 2022 y comenzamos a planear para este hackathon. El hackathon estaba programado para comenzar el 23 de septiembre de 2023 y concluir el 21 de noviembre de 2022. Aunque la fecha límite se extendió hacia el 24 de noviembre de 2023 hacia el final del hackathon. Dado que estábamos un mes antes, decidimos pasar este tiempo aprendiendo y generando ideas sobre en qué trabajaríamos para este hackathon de 2 meses. Durante ese primer mes, obtuvimos una visión general de la criptografía y las blockchains. Revisamos y practicamos en la testnet de NEAR, revisamos el SDK de NEAR y desplegamos un par de contratos inteligentes.
La Idea
Después de obtener una gran introducción a todo lo relacionado con blockchain y NEAR, comenzamos a generar ideas. Quería que este proyecto fuera algo que no fuera solo un “proyecto de hackathon”, sino algo que pudiera convertirse en un producto que otros pudieran usar y actuar como un ejemplo de cómo la criptografía podría ser útil para cosas fuera del simple comercio.
Con esto en mente, inicialmente decidimos crear algo similar al Blueprint de Unreal Engine, pero para la creación y despliegue fácil de contratos inteligentes en la blockchain de NEAR sin necesidad de codificación. Sin embargo, una semana antes de que comenzara el hackathon, abandonamos la idea porque simplemente no tenía sentido. ¿Por qué alguien se molestaría en usar nuestra herramienta para crear contratos inteligentes de NEAR si aún no había un caso de uso práctico para ellos? Sería como desarrollar una herramienta que muchas personas no necesitaban.
Con solo una semana antes de que comenzara el hackathon, comenzamos a generar ideas nuevamente y nos decidimos por esta idea:
Una plataforma descentralizada donde los investigadores de IA pueden externalizar
la etiquetación de datos a etiquetadores de todo el mundo
Nombramos al proyecto “Labeler NearBy”. Nuestra decisión de elegir esta idea se basó en las siguientes razones:
- El desarrollo de IA requiere etiquetado humano de datos para el entrenamiento.
- Encontrar y gestionar individuos calificados para etiquetar conjuntos de datos específicos es un desafío.
- La idea ya ha sido implementada con éxito por una empresa llamada Scale AI, como lo demuestra cómo encontraron el ajuste producto-mercado.
- Los servicios centralizados como Scale AI plantean preocupaciones ya que las organizaciones tienen que enviar sus datos a la empresa de etiquetado, que luego externaliza etiquetadores humanos a nivel mundial. Después del proceso de etiquetado, la empresa devuelve los datos etiquetados a la organización. Esto renuncia al control sobre datos de entrenamiento valiosos, que podrían ser utilizados por la empresa de etiquetado para entrenar sus propios modelos. Descentralizar este servicio parecía una solución lógica.
- Encontramos muy pocos proyectos en el espacio de aplicaciones descentralizadas (dApp) trabajando en esta idea, lo que nos brinda una oportunidad para innovar y ser pioneros en esta área.
Para ayudar a reducir la complejidad, decidimos que Labeler NearBy solo soportará datos de imagen por el momento.
Presentación
Con la idea elegida y el hackathon oficialmente en marcha, mi amigo y yo comenzamos a construir Labeler NearBy. Trabajamos en nuestro proyecto durante 2 meses hasta que enviamos el borrador final de nuestro proyecto a Devpost el 24 de noviembre de 2022. Enviamos nuestro proyecto a Devpost y también creamos una copia de nuestra presentación en Github. Este blog no cubre todos los aspectos técnicos y el proceso de desarrollo de Labeler NearBy. Sabiendo esto, para aprender más sobre cómo funciona Labeler NearBy o para ver nuestra presentación final, visita uno de los siguientes enlaces:
Labeler NearBy consiste en dos bases de código: ln-researcher y ln-labeler. Estas bases de código son completamente de código abierto bajo la licencia MIT y se pueden ver a través de los siguientes enlaces:
Aquí hay una visión general de cómo funcionaría Labeler NearBy (LN):
Un investigador requiere imágenes etiquetadas para entrenar su modelo de IA. Para lograr esto, el investigador utiliza LN para alojar sus datos y proporcionar un medio para que los etiquetadores etiqueten sus datos. Esto se logra a través de ln-researcher, un servicio web autoalojado que consiste en una API, los contratos inteligentes del investigador y una base de datos local de Postgres. Para el etiquetador, se proporciona (hubiera sido proporcionado) un frontend web, permitiéndoles acceder y etiquetar las imágenes del investigador. Mientras se está etiquetando, una imagen es etiquetada tres veces por diferentes etiquetadores. Solo el etiquetador con las mejores etiquetas, determinado a través de un sistema de votación, es recompensado con monedas NEAR. La aplicación web responsable de este proceso se llama ln-labeler. El investigador financia cada operación de etiquetado, y las monedas NEAR se pueden convertir fácilmente a dólares a través de Coinbase. Toda la logística de transacciones es manejada por contratos inteligentes alojados en la blockchain del Protocolo NEAR.
Puedes ver nuestro video de demostración de Labeler NearBy para el hackathon aquí:
Mayor Logro
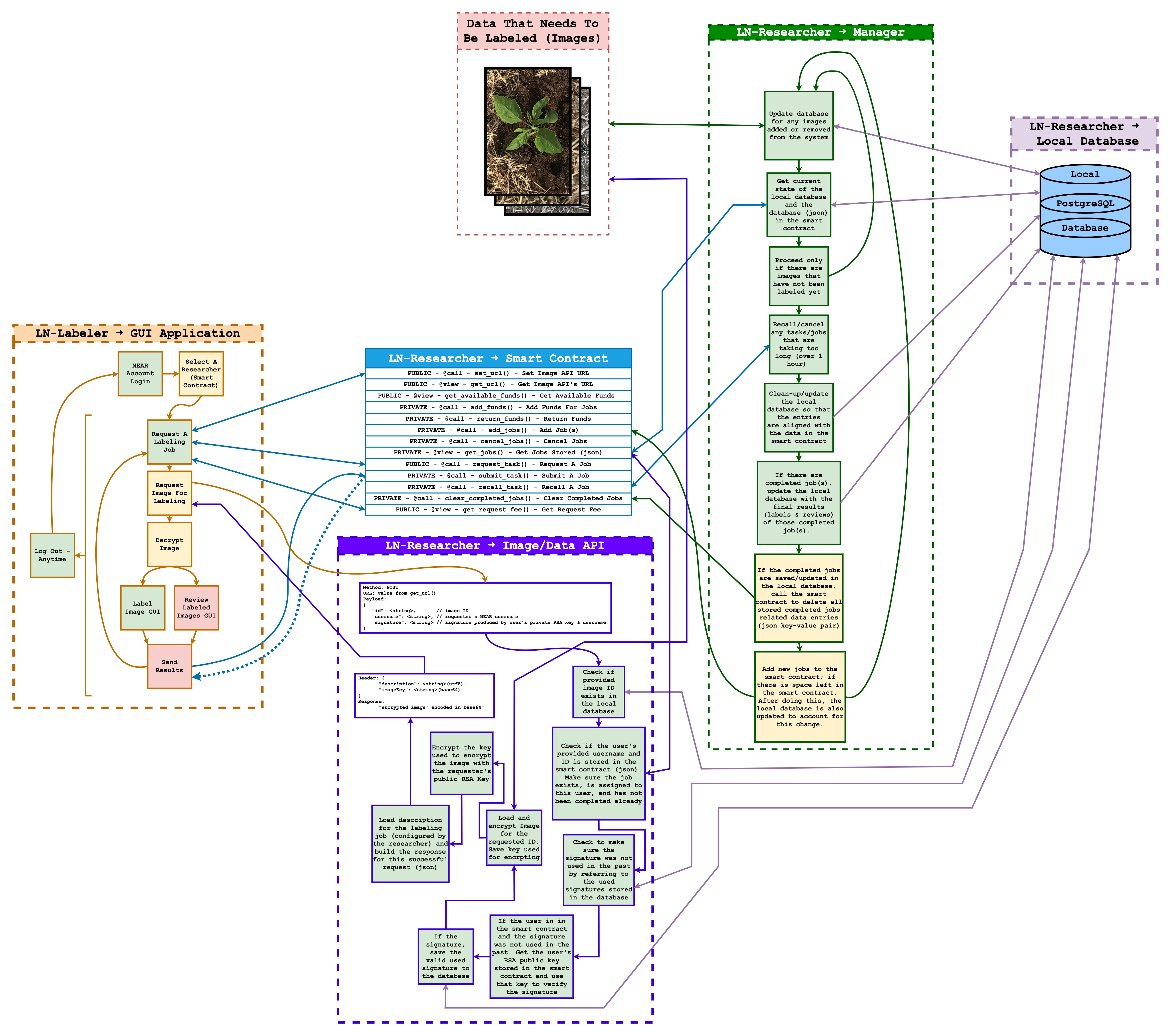
La característica de la que estoy más orgulloso de implementar es una función llamada getImage(). Esta función sirve como un punto final de API en ln-researcher y juega un papel crucial en la pipeline de datos entre investigadores y etiquetadores en Labeler NearBy (LN).
Este punto final de API permite a los investigadores distribuir de manera segura y confiable sus imágenes para etiquetado. Las asignaciones de etiquetado son gestionadas a través de contratos inteligentes de NEAR en la blockchain del Protocolo NEAR mientras que los datos de imagen son alojados por el investigador a través de ln-researcher.
El punto final realiza una serie de verificaciones de seguridad para asegurar que solo el etiquetador asignado pueda acceder a la imagen. Esto incluye verificar la firma de la solicitud y comprobar el contrato inteligente asociado para confirmar la existencia de la tarea y su asignación al etiquetador que solicita.
Una vez que la solicitud es validada en la API autoalojada del investigador ln-researcher, la función recupera la imagen de la base de datos local de Postgres, encripta la imagen y la entrega al etiquetador autorizado que luego puede desencriptar la imagen para etiquetado. Simultáneamente, la función actualiza el estado de la imagen en la base de datos, indicando el progreso de la imagen que se está etiquetando. A lo largo de este proceso, se utilizan claves RSA tanto del investigador como del etiquetador para autenticar. Mientras que la encriptación AES se utiliza para encriptar la imagen.
Este punto final juega un papel crítico en la gestión de la distribución segura y controlada de imágenes de investigadores a etiquetadores. Asegura una transferencia de datos segura y rastrea y gestiona efectivamente el proceso de etiquetado de imágenes. Además, este proceso tiene el potencial de eliminar la necesidad de usar HTTPS, al menos para este punto final.
Este punto final/función específica fue probado y demostrado ser funcional. A continuación se muestra un diagrama que ilustra la funcionalidad general de Labeler NearBy, incluyendo una representación clara de cómo funciona el punto final/función mencionado anteriormente:
Resultado
Lamentablemente, la triste realidad es que no pudimos completar completamente este proyecto antes de la fecha límite del hackathon. La mayor parte del proyecto se completó, como el ln-researcher, pero el frontend (ln-labeler) no se completó y no pudimos desplegar una demostración en vivo. Aunque el backend (ln-researcher) estaba básicamente completado, sin un frontend que funcionara correctamente y sin una demostración en vivo, nadie pudo probar la idea de Labeler NearBy. No solo eso, sino que los jueces no pudieron probar el proyecto y, en su lugar, tuvieron que leer la presentación, revisar el código y/o intentar ejecutarlo ellos mismos. Lo que hizo que nuestras posibilidades de ganar bajaran a prácticamente cero por ciento. Esto se confirmó el 15 de diciembre de 2022 cuando se anunciaron los ganadores del hackathon, y no estábamos entre ellos.
Perder
No voy a ocultar el hecho de que el resultado final de este hackathon fue desalentador. Se invirtieron meses en este proyecto y tenía una gran visión para este proyecto ya que pensé que proporcionaría una herramienta muy útil para los investigadores.
Tengo un estándar claro para los proyectos que emprendo: o tienen éxito o fracasan; no hay un término medio. Así que este proyecto fue un fracaso porque no se completó completamente antes de la fecha límite y permaneció inaccesible para los usuarios potenciales.
Pero es importante recordar que el fracaso es una parte natural de la vida. Nuestros éxitos se construyen sobre las lecciones que aprendemos de nuestros fracasos. Aunque el resultado de este hackathon fue desalentador, aún proporcionó valiosas ideas en lo que respecta al desarrollo y construcción de un proyecto/producto.
Lecciones Aprendidas
Las principales lecciones que saqué de esta experiencia fueron las siguientes:
- El proyecto que elegimos requería muchas características construidas de antemano antes de que pudiéramos iterar sobre él. ¿Qué quiero decir con esto? Bueno, este proyecto requería que casi todos los componentes de la idea estuvieran construidos antes de que pudiéramos siquiera probar la idea. Habría tenido más sentido elegir un proyecto que tuviera menos componentes esenciales para funcionar. Al hacerlo, podríamos haber construido los componentes esenciales más rápido y luego iterar sobre el proyecto antes. Al hacerlo, podríamos haber cumplido con la fecha límite más fácilmente y hecho un proyecto que podría haber sido más simple pero más completo. YC, un acelerador de startups tecnológicas, enfatiza que deberías lanzar rápidamente, hablar con los usuarios e iterar. Deberíamos haber hecho eso con nuestro proyecto para este hackathon.
- Subestimamos cuánto tiempo iba a llevar construir este proyecto. Este fue nuestro primer hackathon y nuestra primera vez haciendo una aplicación descentralizada (dapp). No solo eso, sino que yo estaba trabajando a tiempo completo como ingeniero de software y mi amigo estaba completando su maestría. Sin embargo, pensamos que 2 meses serían suficientes. Habría tenido más sentido reducir el alcance del proyecto y/o encontrar un miembro más del equipo que pudiera haber reducido nuestra carga de trabajo.
- Winston Churchill declaró famosamente: “La perfección es el enemigo del progreso”. Estaba tratando este proyecto como un producto de negocio a consumidor (B2C), cuando en realidad este era solo un proyecto de hackathon y, en el mejor de los casos, un producto mínimo viable (MVP). Así que, al principio, perdí demasiado tiempo en pequeños detalles cuando debería haber estado enfocando mi tiempo en hacer que las características principales funcionaran adecuadamente.
Además de estas valiosas lecciones, he adquirido nuevas habilidades que han demostrado ser invaluables tanto en mis proyectos personales como en mis esfuerzos profesionales. Estas habilidades incluyen:
- Desarrollar APIs a través de Node.js, JavaScript y Express.js
- Configurar y usar PostgreSQL para la gestión de datos
- Incorporar PostgreSQL en el desarrollo de API utilizando paquetes como PG.
- Utilizar RSA (cifrado asimétrico) y AES (cifrado simétrico) para mejorar la seguridad de los datos.
Conclusión
En general, me alegra que hayamos participado en este hackathon, a pesar de estar decepcionado con el resultado final. Estoy agradecido por las valiosas lecciones y habilidades que adquirí mientras trabajaba en Labeler NearBy, ya que me han convertido en un mejor desarrollador y han contribuido significativamente al desarrollo de mi próximo proyecto: Notify-Cyber.
Otras Notas
- Podría volver a Labeler NearBy, pero por el momento, este proyecto está en “largo hiato”
- Actualmente, Labeler NearBy debería funcionar SOLAMENTE en la testnet de NEAR. Necesita más desarrollo, pruebas y auditoría.