8090's Top Coder Challenge
Original LinkedIn Post
Projekt GitHub Repo
Am Freitagabend sah ich einen öffentlichen Beitrag auf Twitter/X von Chamath Palihapitiya, der eine offene Top Coder Challenge ankündigte, die von seiner neuen Firma, 8090 Solutions, veranstaltet wurde. Jeder konnte teilnehmen. Die Herausforderung sollte am nächsten Tag stattfinden, nur 8 Stunden dauern und das Reverse Engineering eines Black-Box-Alt-Systems beinhalten, wobei nur historische Daten und einige Mitarbeiterinterviews verwendet werden durften.
Ich entschied mich, mitzumachen!
Am Ende des Tages war ich geehrt, 7. von 425 Ingenieuren zu werden. Du kannst die Rangliste HIER einsehen und den Code für diese Herausforderung HIER anschauen. Aber ich werde nicht lügen, ich hoffte ehrlich gesagt nur, in dieser kurzen Zeit etwas abzuschließen, daher war es eine Überraschung und ein großer persönlicher Erfolg für mich, es auf die Rangliste zu schaffen.
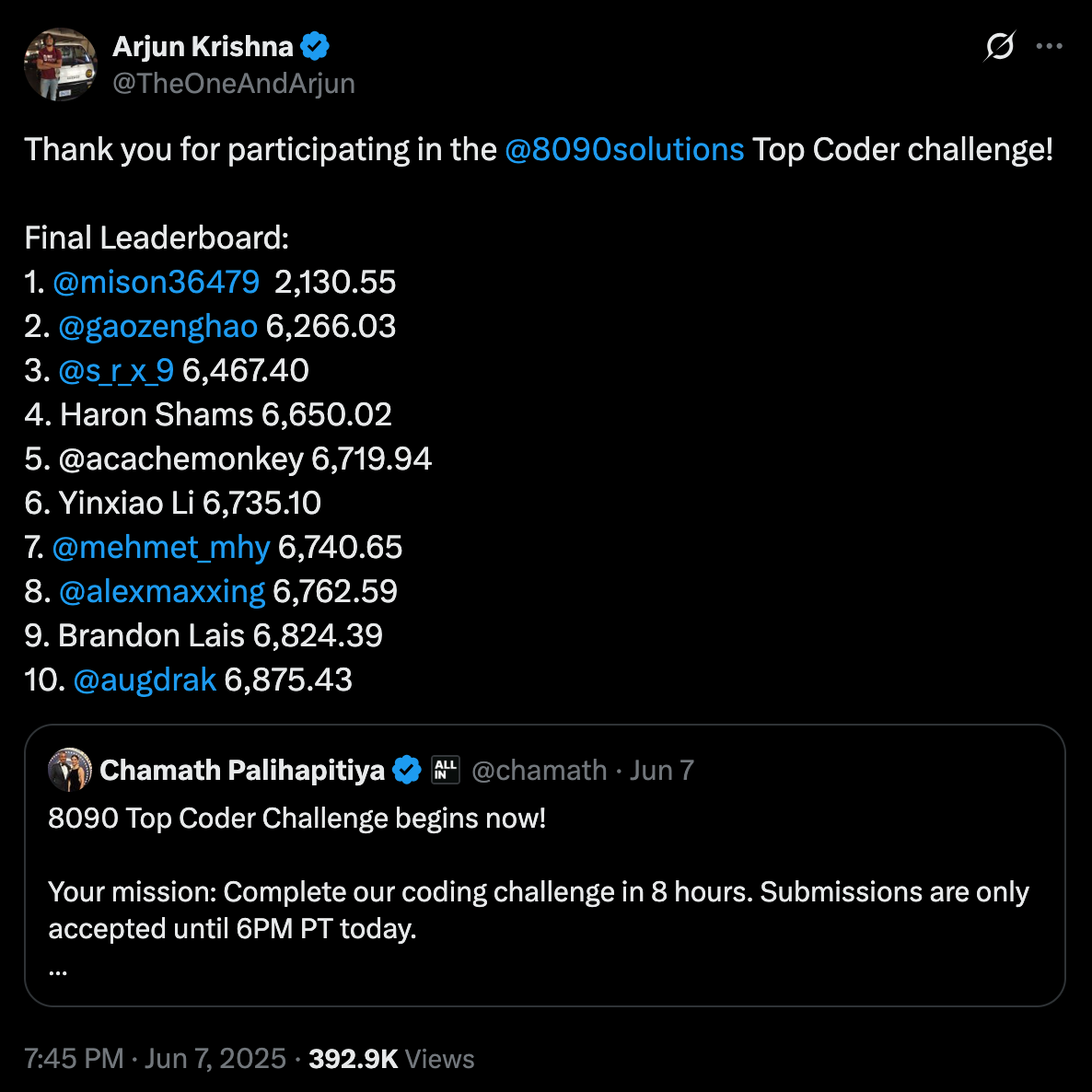
Die Herausforderung war solo, und das Ziel war es, ein 60 Jahre altes Black-Box-Reiseerstattungssystem zu replizieren, das keinen Quellcode und keine Dokumentation hatte. Uns wurden einige Artefakte zur Verfügung gestellt, darunter ein Produktbrief, Transkripte von Mitarbeiterinterviews und ein öffentliches Datenset mit 1.000 historischen Beispielen von Eingaben und erwarteten Ausgaben. Daraus musste ich die Geschäftslogik ableiten, wie die Erstattungsbeträge berechnet wurden, und eine moderne Version implementieren, die die gleichen Ergebnisse so genau wie möglich produzieren konnte. Die Einsendungen wurden anhand eines separaten versteckten Datensatzes bewertet, der 5.000 Testfälle enthielt, anstelle der ursprünglichen 1.000. Dieser größere private Datensatz bestimmte letztendlich deine Endnote und Platzierung. Das Bewertungssystem belohnte Genauigkeit, wobei eine niedrigere Punktzahl bedeutete, dass deine Lösung dem versteckten Verhalten des ursprünglichen Systems näher kam.
Um die Unsicherheit und Muster in den Daten zu bewältigen, verwendete ich klassische maschinelle Lerntechniken zusammen mit grundlegenden Heuristiken und programmatischer Logik. Es war eine sorgfältige Mischung aus Datenanalyse, Merkmalsmodellierung und Regelapproximation basierend auf unvollkommenen Hinweisen.
Hier war mein eval Score für den öffentlichen Datensatz von 1.000:
✅ Evaluierungszusammenfassung
------------------------
Gesamtfälle : 1000
Exakte Übereinstimmungen (<$0.01): 0
Nahe Übereinstimmungen (<$1.00): 17
Durchschnittlicher Fehler : $31.15
Punktzahl : 3214.93
Eine Lösung für eine solche Herausforderung in 8 Stunden zu entwickeln, wäre ohne die Hilfe von KI-gestützten Werkzeugen, die es erleichterten, Ideen schnell zu erkunden, zu integrieren und zu testen, nahezu unmöglich gewesen.
Es fühlte sich an wie Softwarearchäologie kombiniert mit einem Live-Coding-Sprint. Eines der intensivsten und lohnendsten technischen Herausforderungen, die ich je gemacht habe.
Danke an Chamath Palihapitiya und Arjun Krishna für die Organisation einer so kreativen und inspirierenden Herausforderung.
Links: