Vorhersage menschlicher Aktionen
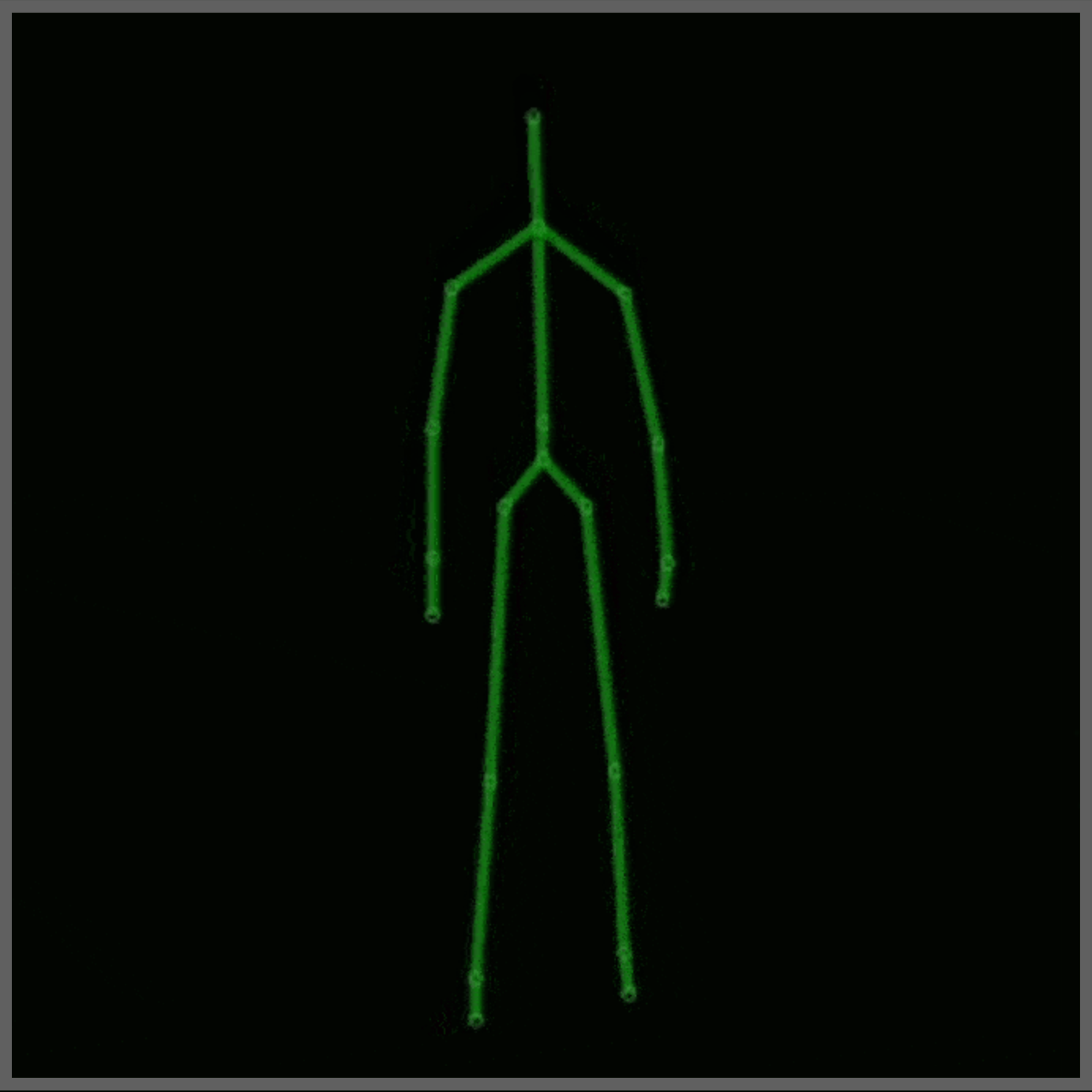
Einzelheiten
Dieses Projekt war Projekt #3 für Dr. Zhangs Human Centered Robotics (CSCI473) Klasse an der Colorado School of Mines während des Frühjahrssemesters 2020. Es wurde entwickelt, um eine Einführung in maschinelles Lernen in der Robotik durch die Verwendung von Support Vector Machines (SVM) zu bieten. Die ursprünglichen Projektlieferungen/Beschreibungen können hier eingesehen werden.
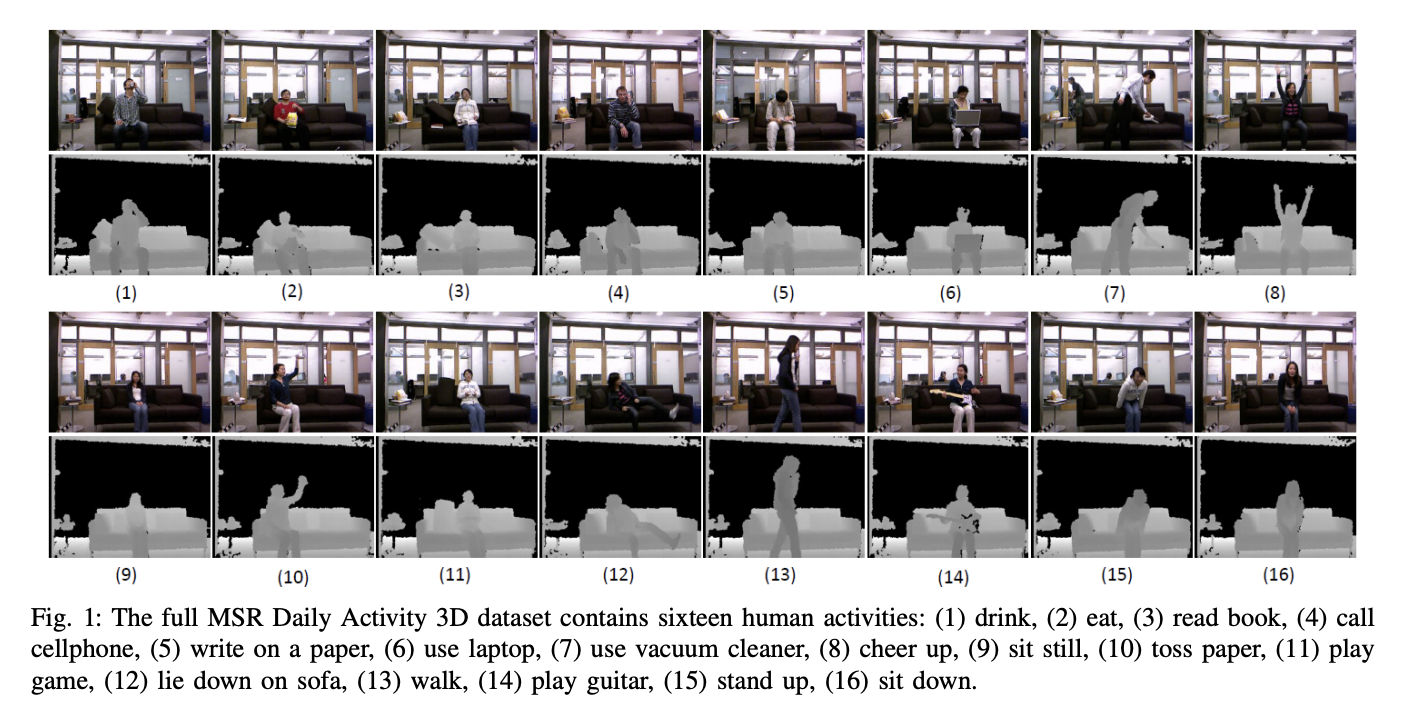
Für dieses Projekt wurde der MSR Daily Activity 3D Dataset (Abbildung 2) mit einigen Modifikationen verwendet. Dieser Datensatz enthält 16 menschliche Aktivitäten, die von einem Xbox Kinetic-Sensor gesammelt und als Skelette gespeichert wurden. Skelette sind eine Reihe von realen (x, y, z) Koordinaten von 20 Gelenken eines Menschen, die in einem Frame aufgezeichnet wurden. Hier ist eine Abbildung, die zeigt, was ein Skelett ist:
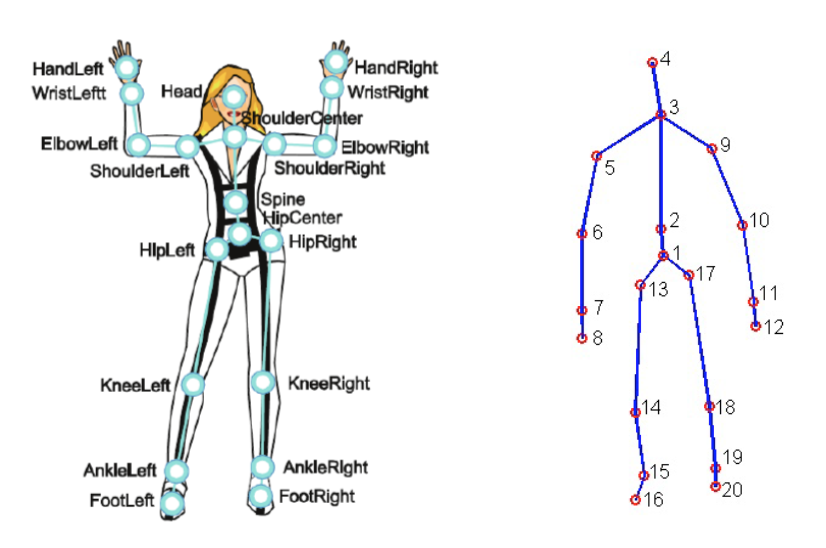
Um die Vorhersage menschlicher Aktionen zu erreichen, müssen die Rohdaten in einer Form dargestellt werden, die von einer SVM verarbeitet werden kann. Für dieses Projekt wurden die folgenden Darstellungen verwendet:
- Relative Winkel und Abstände (RAD) Darstellung
- Histogramm der Gelenkpositionsunterschiede (HJPD) Darstellung
Für die Klassifizierung werden die Darstellung(en) in eine SVM eingespeist, die von LIBSVM betrieben wird, um ein Modell zu erstellen, das menschliche Aktionen vorhersagen kann. Es werden zwei Modelle erstellt, eines mit RAD und ein anderes mit HJPD. Das Ziel ist es, diese Modelle so genau wie möglich zu machen und zu sehen, welche Darstellung die beste Leistung erbringt.
In Anbetracht dessen hier eine Übersicht darüber, was der Code tut:
- Laden der Rohdaten aus dem modifizierten Datensatz
- Entfernen von Ausreißern und/oder Fehlerdaten aus dem geladenen Datensatz
- Umwandlung der endgültigen Rohdaten in RAD- und HJPD-Darstellungen
- Die Darstellungen werden in abgestimmte SVM(s) eingespeist, um zwei Modelle zu generieren
- Die beiden Modelle werden dann mit Testrohdata gefüttert und eine Verwirrungsmatrix wird erstellt, um zu messen, wie die Modell(e) abgeschnitten haben.
Ergebnisse
Nach dem Ausführen des Codes und dem Abstimmen der Modelle nach bestem Wissen und Gewissen hier die endgültige Verwirrungsmatrix für sowohl die RAD- als auch die HJPD-Modelle:
Darstellung: RAD
Genauigkeit: 62,5%
LIBSVM Klassifizierung 8.0 10.0 12.0 13.0 15.0 16.0
Tatsächliche Aktivitätsnummer
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
Darstellung: HJPD
Genauigkeit: 70,83%
LIBSVM Klassifizierung 8.0 10.0 12.0 13.0 15.0 16.0
Tatsächliche Aktivitätsnummer
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
Fazit
Da beide Genauigkeiten über 50 % liegen, war dieses Projekt ein Erfolg. Außerdem scheint die HJPD-Darstellung die genauere Darstellung für diese Klassifikationen zu sein. Damit gibt es ein Modell(e), das menschliche Aktionen mithilfe von Skelettdaten vorhersagt. Die Modell(e) hier sind weit davon entfernt, perfekt zu sein, aber sie sind besser als zufällig. Dieses Projekt war das, was das Moving Pose Projekt später ins Leben rief.
Zusätzliche Hinweise:
- Dieses Projekt wurde mit Python Version 3.8.13 getestet
- Für dieses Projekt wird der vollständige MDA3-Datensatz und ein modifizierter MDA3-Datensatz verwendet. Der modifizierte MDA3 enthält nur die Aktivitäten 8, 10, 12, 13, 15 und 16. Außerdem hat die modifizierte Version einige “beschädigte” Datenpunkte, während der vollständige Datensatz dies nicht hat.
- Raum-Zeit-Darstellung von Personen basierend auf 3D-Skelettdaten: Eine Übersicht
- YouTube: Wie der Kinect-Tiefensensor in 2 Minuten funktioniert
- Medium: Verständnis der Kinect V2 Gelenke & Koordinatensystem
- Kinect Wikipedia-Seite
- Jameco Xbox Kinect
- Informationen über SVM(s) & LibSVM: cjlin libsvm, libsvm pypi-Seite, & libsvm github
- SVM & LIBSVM Logik & Dokumentation: cjlin Leitfadenpapier & cjlin libsvmtools Datensätze
- Informationen über den verwendeten/modifizierten Datensatz