ABM Marketing mit InsightRed
![]()
Über
InsightRed ist ein LLM-gestütztes Account-Based Marketing (ABM) Tool, das die neuesten Reddit-Kommentare aus Subreddits extrahiert, sortiert nach “Hot”, und Benutzer identifiziert, die potenzielles Interesse an Ihrem Projekt oder Produkt zeigen. Es hilft Ihnen, wertvolle Benutzer auf Reddit zu identifizieren und anzusprechen, um Ihre ersten Benutzer für Ihr Produkt/Ihr Projekt zu gewinnen. Dieses Projekt wurde für den ANARCHY Oktober 2023 Hackathon entwickelt.
Ankündigung(en)
19. Oktober 2023
Als Nachverfolgung dieses Projekts freue ich mich, bekannt zu geben, dass wir den 1. Platz beim Anarchy Oktober 2023 Hackathon gewonnen haben!
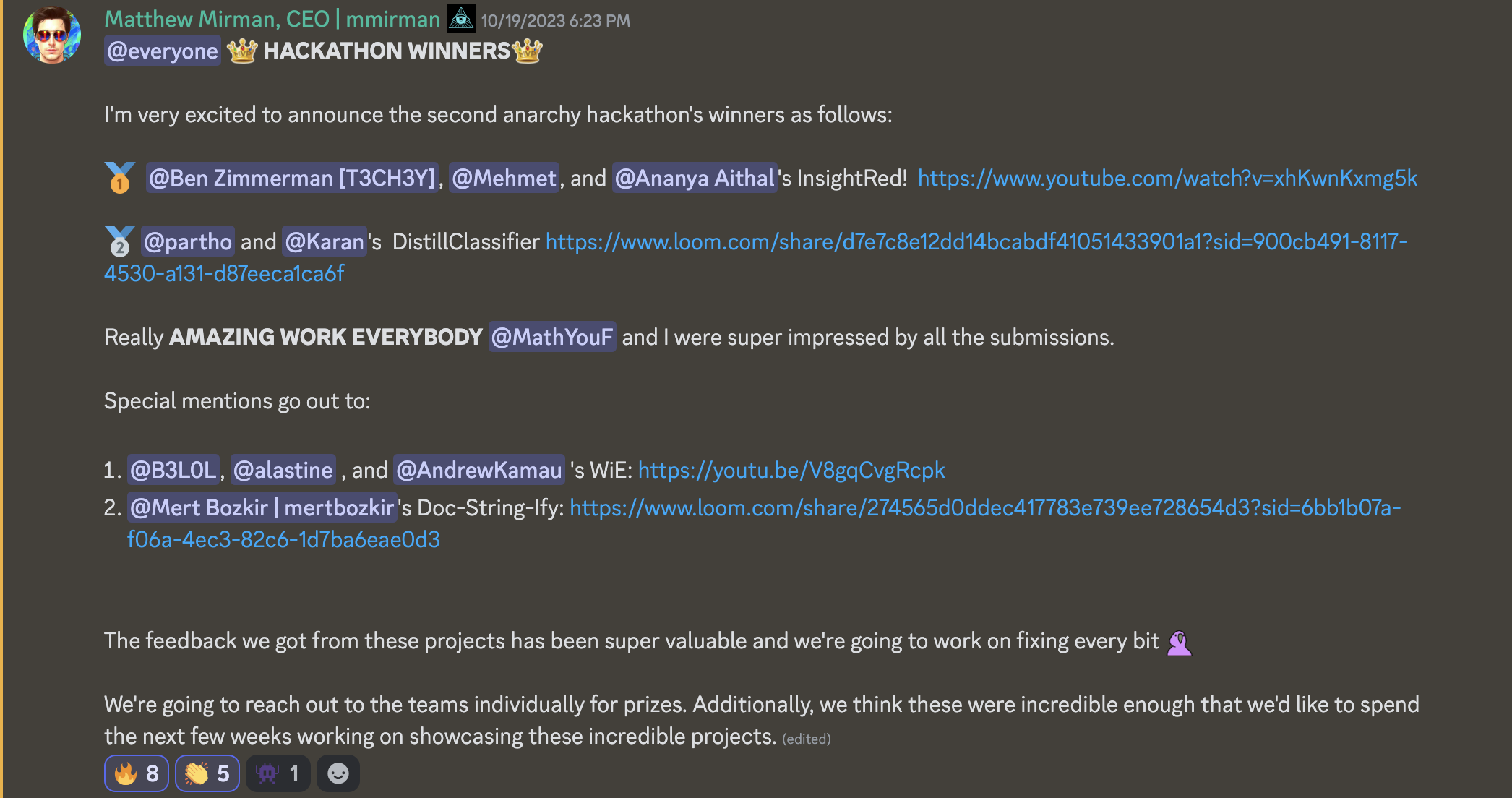
Klicken Sie hier, um die Nachricht im TEXT-Modus anzuzeigen (modifiziert aufgrund der Discord-Formatierung)
@everyone **👑 HACKATHON 👑**
Ich freue mich sehr, die Gewinner des zweiten Anarchy Hackathons wie folgt bekannt zu geben:
🥇 "@Ben Zimmerman [T3CH3Y]", @Mehmet und "@Ananya Aithal"'s InsightRed! https://www.youtube.com/watch?v=xhKwnKxmg5k
🥈 @partho und @Karans DistillClassifier https://www.loom.com/share/d7e7c8e12dd14bcabdf41051433901a1?sid=900cb491-8117-4530-a131-d87eeca1ca6f
Wirklich **TOLLE ARBEIT ALLE** @MathYouF und ich waren super beeindruckt von allen Einsendungen.
Besondere Erwähnungen gehen an:
1. @B3LOL, @alastine und @AndrewKamau 's WiE: https://youtu.be/V8gqCvgRcpk
2. "@Mert Bozkir | mertbozkir"'s Doc-String-Ify: https://www.loom.com/share/274565d0ddec417783e739ee728654d3?sid=6bb1b07a-f06a-4ec3-82c6-1d7ba6eae0d3
Das Feedback, das wir von diesen Projekten erhalten haben, war super wertvoll und wir werden daran arbeiten, jedes Detail zu verbessern 🦜
Wir werden die Teams einzeln wegen der Preise kontaktieren. Darüber hinaus denken wir, dass diese Projekte so beeindruckend waren, dass wir die nächsten Wochen damit verbringen möchten, diese unglaublichen Projekte zu präsentieren.
Demo
Komponenten von InsightRed
🧩 Sammler
Der Sammler sammelt die neuesten Reddit-Beiträge und die Kommentare zu diesen Beiträgen für ein gegebenes Subreddit, indem er die Reddit-API verwendet. Nach dem Sammeln speichert der Sammler die gesammelten Daten in einer lokalen SQLite-Datenbank. Dies wird erleichtert durch die Verwendung des Python-Pakets praw, das bei der Nutzung der Reddit-API hilft, und SQLAlchemy für die Durchführung von CRUD-Operationen in der lokalen SQLite-Datenbank.
🧩 Vektorisierer
Der Vektorisierer überprüft die lokale SQLite-Datenbank, um zu sehen, welche Kommentare noch nicht in der Vektordatenbank gespeichert wurden. Nachdem eine Liste von Kommentaren erstellt wurde, erstellt er ein Embedding des Beitrags+Kommentars unter Verwendung des “text-embedding-ada-002” Modells von OpenAI. Dieses Embedding wird als Index in der Vektordatenbank verwendet, und einige Metadaten in Form von JSON werden ebenfalls erstellt. Der Index und die Metadaten werden dann in die Vektordatenbank hochgeladen, die in diesem Fall Pinecone (cloudbasiert) ist. Nach dem Hochladen wird die lokale SQLite-Datenbank aktualisiert, um ein erneutes Hochladen der gleichen Daten in Pinecone zu vermeiden. Dies geschieht alles mit dem Python-Client von Pinecone (pinecone-client) für CRUD-Optionen zur Vektordatenbank und LangChain für die Handhabung des Embedding-Prozesses.
🧩 Schnittstelle
Die Schnittstelle ist das, was der Benutzer verwendet, um mit dem Tool zu interagieren. In diesem Fall ist die Schnittstelle eine CLI. Die Schnittstelle hat eine Implementierung von Retrieval-Augmented-Generation (RAG). Der Benutzer gibt eine Beschreibung seines Produkts, eine Liste von Subreddits, die überprüft werden sollen, sowie einige Filter an. In diesem Kontext wird der Sammler aufgerufen, dann wird der Vektorisierer aufgerufen. Nachdem diese beiden Dienste mit der Verarbeitung fertig sind, wird die eingegebene Produktbeschreibung verwendet, um eine ähnliche Suche in der Vektordatenbank durchzuführen. Die besten Ergebnisse und die Produktbeschreibung werden dann in eine Prompt-Vorlage eingespeist, die die endgültige Eingabeaufforderung erstellt. Die endgültige Eingabeaufforderung wird dann an das GPT-4-Modell von OpenAI gesendet und die endgültigen Ergebnisse werden dem Benutzer präsentiert. Diese Ergebnisse sind eine Auflistung aller Reddit-Kommentare, die stark darauf hindeuten, dass die Reddit-Nutzer an dem bereitgestellten Produkt interessiert wären, basierend auf seiner Beschreibung. Diese Komponente funktioniert, indem sie die Kommentare des Sammlers und des Vektorisierers verwendet sowie Anarchys LLM-VM zur Abfrage des GPT-4-Modells von OpenAI nutzt.
Teammitglieder
Bemerkenswerte externe Anerkennung
casta (Hacker News)
Hat die Inspiration für dieses Projekt durch ihren HN-Beitrag geliefert. Da ihre Lösung nicht Open Source war, wurde ich motiviert, eine Open-Source-Version zu erstellen (dieses Projekt).
ChatGPT (GPT-4)
War sehr hilfreich bei der Entwicklung, indem es den Entwicklungszyklus wirklich beschleunigte. Und es generierte das Logo des Projekts und das YouTube-Thumbnail mit dem neuen DALL-E 3 Modell von OpenAI.
James Briggs (YouTuber)
Jame’s Video erklärte wirklich, wie man die Reddit-API verwendet und wie man eine grundlegende RAG-Pipeline mit Python implementiert.
Quellen
- Show HN: Labor Day Fun Project, Find Reddit Comments to Promote Your Business
- Pinecone Indexing Overview Docs
- YouTube: Chatbots with RAG - LangChain Full Walkthrough
- OpenAI API-Seite
- Pinecone Quickstart-Dokumentation
- Reddit: Aktualisierte Ratenlimits, die in den kommenden Wochen in Kraft treten
- Reddit Apps-Seite
- YouTube: So verwenden Sie die Reddit-API in Python
- Medium: Scraping Reddit-Daten mit der Reddit-API
- GitHub Gist: Reddit API
- GitHub: praw
- ChatGPT - Web-App