توقع أفعال الإنسان
التفاصيل
كان هذا المشروع هو المشروع رقم 3 في فصل دراسي “روبوتات موجهة نحو الإنسان” (CSCI473) للدكتور زانغ في مدرسة كولورادو للمناجم خلال فصل الربيع 2020. تم تصميمه لتقديم مقدمة في تعلم الآلة في الروبوتات من خلال استخدام آلات الدعم المتجهة (SVM). يمكن عرض تسليمات/وصف المشروع الأصلي هنا.
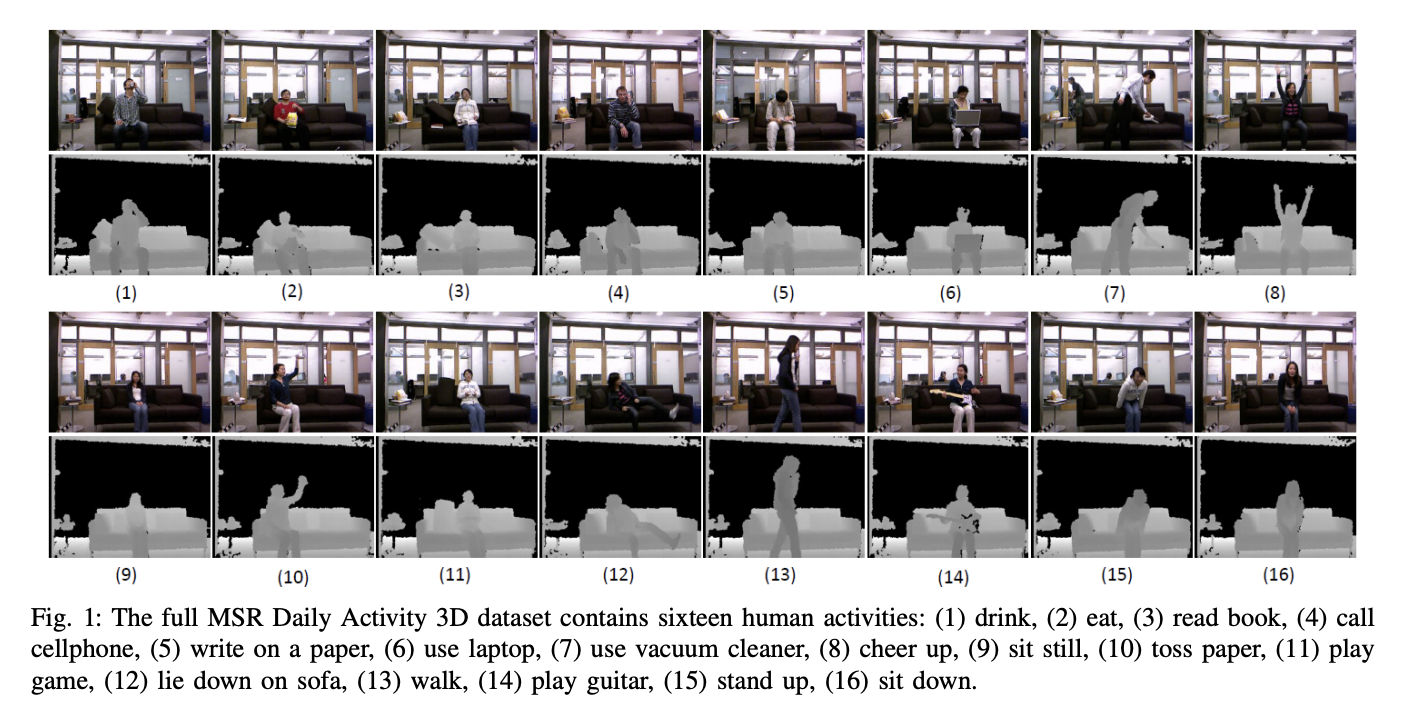
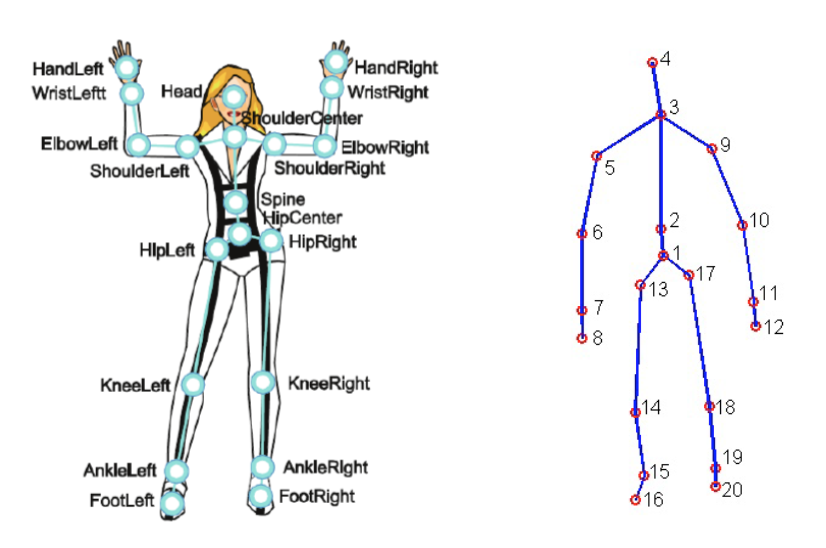
بالنسبة لهذا المشروع، تم استخدام مجموعة بيانات النشاط اليومي 3D من MSR (الشكل 2)، مع بعض التعديلات. تحتوي هذه المجموعة على 16 نشاطًا بشريًا تم جمعها من مستشعر Xbox Kinetic وتخزينها كهيكليات عظمية. الهيكليات هي مصفوفة من إحداثيات العالم الحقيقي، (x، y، z)، لـ 20 مفصلًا من جسم الإنسان تم تسجيلها في إطار واحد. هنا شكل يوضح ما هو الهيكل العظمي:
لتحقيق توقع أفعال الإنسان، يجب تمثيل البيانات الخام في شكل يمكن معالجته بواسطة SVM. بالنسبة لهذا المشروع، تم استخدام التمثيلات التالية:
- تمثيل الزوايا النسبية والمسافات (RAD)
- تمثيل اختلافات موضع المفاصل (HJPD)
للتصنيف، يتم إرسال التمثيل (أو التمثيلات) إلى SVM، المدعوم بـ LIBSVM، لإنشاء نموذج يمكنه توقع أفعال الإنسان. سيتم إنشاء نموذجين، واحد باستخدام RAD وآخر باستخدام HJPD. الهدف هو جعل هذه النماذج دقيقة قدر الإمكان ورؤية أي تمثيل يؤدي بشكل أفضل.
مع معرفة ذلك، إليك نظرة عامة على ما يفعله الكود:
- تحميل البيانات الخام من مجموعة البيانات المعدلة
- إزالة أي بيانات شاذة و/أو بيانات خطأ من مجموعة البيانات المحملة
- تحويل البيانات الخام النهائية إلى تمثيلات RAD و HJPD
- يتم إرسال التمثيلات إلى SVM (SVMs) المعدلة لتوليد نموذجين
- يتم بعد ذلك تغذية النموذجين ببيانات اختبار خام ويتم إنشاء مصفوفة ارتباك لقياس كيفية أداء النموذج (النماذج).
النتائج
بعد تشغيل الكود وضبط النماذج بأفضل ما أستطيع، إليك مصفوفة الارتباك النهائية لكل من نماذج RAD و HJPD:
التمثيل: RAD
الدقة: 62.5%
تصنيف LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
رقم النشاط الفعلي
8.0 8 0 0 0 0 0
10.0 1 5 0 0 1 1
12.0 0 1 1 0 3 3
13.0 0 0 0 6 1 1
15.0 0 0 0 1 5 2
16.0 0 0 0 0 3 5
التمثيل: HJPD
الدقة: 70.83%
تصنيف LIBSVM 8.0 10.0 12.0 13.0 15.0 16.0
رقم النشاط الفعلي
8.0 7 1 0 0 0 0
10.0 1 5 0 0 0 2
12.0 0 0 7 0 1 0
13.0 2 0 1 5 0 0
15.0 0 0 0 0 7 1
16.0 0 2 0 0 3 3
الخاتمة
نظرًا لأن كلا الدقتين تتجاوزان 50%، كان هذا المشروع ناجحًا. أيضًا، يبدو أن تمثيل HJPD هو التمثيل الأكثر دقة للاستخدام في هذا التصنيف. مع هذا، هناك نموذج (نماذج) تتوقع أفعال الإنسان باستخدام بيانات الهيكل العظمي. النموذج (النماذج) هنا بعيدة عن الكمال لكنها أفضل من العشوائية. كان هذا المشروع هو الذي أعطى الحياة لمشروع الوضع المتحرك لاحقًا.
ملاحظات إضافية:
- تم اختبار هذا المشروع على إصدار Python 3.8.13
- بالنسبة لهذا المشروع، تم استخدام مجموعة بيانات MDA3 الكاملة ومجموعة بيانات MDA3 المعدلة. تحتوي مجموعة بيانات MDA3 المعدلة فقط على الأنشطة 8 و 10 و 12 و 13 و 15 و 16. أيضًا، تحتوي النسخة المعدلة على بعض نقاط البيانات “التالفة” بينما لا تحتوي مجموعة البيانات الكاملة على ذلك.
- تمثيل الزمان والمكان للأشخاص بناءً على بيانات الهيكل العظمي ثلاثية الأبعاد: مراجعة
- يوتيوب: كيف يعمل مستشعر العمق Kinect في دقيقتين
- ميديا: فهم مفاصل Kinect V2 ونظام الإحداثيات
- صفحة ويكيبيديا Kinect
- Jameco Xbox Kinect
- معلومات حول SVM (آلات الدعم المتجهة) وLibSVM: cjlin libsvm، صفحة libsvm على pypi، و libsvm على GitHub
- منطق SVM وLIBSVM والوثائق: ورقة دليل cjlin و مجموعات بيانات أدوات libsvm
- معلومات حول مجموعة البيانات المستخدمة/المعدلة